Write the equation of the line through the points (-6, -19) and (2,5).
Answers
Answer:
m = 7/2 y = 7/2x + b
Step-by-step explanation:
Related Questions
Equation E: c = 2d + 1 Equation F: c = 3d + 7 Which statement describes a step that can be used to find the solution to the set of equations? Equation F can be written as c = 3(c − 1) + 7. Equation F can be written as c = 2(c − 7) + 1. Equation F can be written as d + 1 = 3d + 7. Equation F can be written as 2d + 1 = 3d + 7.
Answers
Answer:
last option is correct
Step-by-step explanation:
A step that could be used to find the solution is substitution.
We can directly substitute for c in equation F
Since c= 2d + 1 from equation E, we can substitute directly in equation F and we will have 2d + 1 = 3d + 7
32x^8-50
32x
8
−50 factor completely
Answers
Answer:
Could you write the problem right? I don't get it tell me when it right and i can factor it.
Step-by-step explanation:
T/F: if you have the data for the entire population of interest, you are most likely going to engage in descriptive statistics.
Answers
True. If you have the data for the entire population of interest, you are most likely going to engage in descriptive statistics.
Descriptive statistics is the branch of statistics that deals with the analysis and interpretation of data that is collected from a sample or population. It is concerned with summarizing and describing the features of a dataset, such as its central tendency, variability, and distribution. Descriptive statistics is used to analyze data when the entire population is not known, and a sample is taken from the population instead. In such cases, inferential statistics is used to make inferences about the population based on the sample data.
However, if the data for the entire population of interest is available, then there is no need to infer or make any assumptions about the population based on the sample. Instead, the focus is on summarizing and describing the features of the population itself, which is the main objective of descriptive statistics. Examples of descriptive statistics include measures of central tendency (such as mean, median, and mode), measures of variability (such as range, standard deviation, and variance), and graphical displays (such as histograms, box plots, and scatterplots).
Learn more about descriptive statistics here:
https://brainly.com/question/30764358
#SPJ11
What method can be use to prove the triangles below are congruent?
options:
not congruent
sas
asa
sss

Answers
a triangle has two sides of length 2 & 6, what’s the smallest possible whole number length for the 3rd side
Answers
Answer:
2
Step-by-step explanation:
2 is the smallest you can get fir it to be a proper triangle
We draw a random sample of size 25 from a normal population with variance 2.4. If the sample mean is 12.5, what is a 99% confidence interval for the population mean? A. [11.7019,13.2981] B. [11.2600,13.7400] C. [11.7793,13.2207] D. [11.3835,13.6165]
Answers
The 99% confidence interval for the population mean can be calculated using the formula:
Confidence Interval = Sample mean ± (Critical value) * (Standard error)
where the critical value is obtained from the t-distribution based on the desired confidence level and the degrees of freedom (n-1), and the standard error is calculated as the square root of the population variance divided by the square root of the sample size.
Given:
Sample mean = 12.5
Population variance (σ²) = 2.4
Sample size (n) = 25
Step 1: Calculate the standard error (SE).
SE = √(σ²/n) = √(2.4/25) ≈ 0.275
Step 2: Determine the critical value based on a 99% confidence level and (n-1) degrees of freedom.
For a sample size of 25, the degrees of freedom is (25-1) = 24. Looking up the critical value in the t-distribution table for a 99% confidence level and 24 degrees of freedom gives approximately 2.797.
Step 3: Calculate the confidence interval.
Confidence Interval = 12.5 ± (2.797 * 0.275) = 12.5 ± 0.768 = [11.732, 13.268]
Therefore, the 99% confidence interval for the population mean is [11.732, 13.268]. This corresponds to option A, [11.7019, 13.2981], with the closest values in the answer choices.
Explanation:
To calculate the 99% confidence interval for the population mean, we use a formula that incorporates the sample mean, the standard error, and the critical value. The critical value represents the number of standard errors away from the mean we need to consider for a particular confidence level. In this case, we use the t-distribution since the population variance is unknown.
First, we calculate the standard error (SE) by dividing the population variance by the square root of the sample size. Next, we determine the critical value from the t-distribution table based on the desired confidence level (99%) and the degrees of freedom (n-1). In this case, the sample size is 25, so the degrees of freedom are 24.
Using the sample mean of 12.5, the standard error of 0.275, and the critical value of 2.797, we calculate the confidence interval by adding and subtracting the product of the critical value and the standard error from the sample mean. This gives us [11.732, 13.268] as the 99% confidence interval for the population mean.
Option A, [11.7019, 13.2981], is the closest representation of the calculated confidence interval and therefore the correct answer.
Learn more about confidence interval here:
brainly.com/question/32546207
#SPJ11
A nutrition researcher wants to determine the mean fat content of hen's eggs. She collects a sample of 40 eggs. She calculates a mean fat content of 23 grams with a sample standard deviation of 8 grams. From these statistics, she calculates a 90% confidence interval of 20.9 grams to 25.1 grams. What can the researcher do to decrease the width of the confidence interval?
a. increase the confidence level
b. decrease the confidence level
c. decrease the sample size
d. none of the above
Answers
To decrease the width of the confidence interval, the researcher can take the following steps:
1. Decrease the confidence level: The confidence interval width is inversely proportional to the confidence level. By decreasing the confidence level, the researcher can have a narrower interval. However, it is important to note that decreasing the confidence level also increases the chance of the interval not capturing the true population mean.
2. Increase the sample size: The sample size affects the precision of the estimate. Increasing the sample size reduces the standard error, which leads to a narrower confidence interval. This is because a larger sample provides more information about the population.
Therefore, the researcher can decrease the width of the confidence interval by either decreasing the confidence level or increasing the sample size. Both approaches will result in a narrower interval, providing a more precise estimate of the mean fat content of hen's eggs.
The researcher can decrease the width of the confidence interval by either decreasing the confidence level or increasing the sample size. Both approaches will result in a more precise estimate of the mean fat content of hen's eggs.
To know more about proportional , visit ;
https://brainly.com/question/33460130
#SPJ11
I need help with this question

Answers
The length of the legs of the right triangle are 2.83 units.
How to find the side of a right triangle?A right tangle triangle is a triangle that has one of its angles as 90 degrees. The sum of angles in a triangle is 180 degrees.
Therefore, the legs of the triangle can be found using trigonometric ratios.
Hence,
sin 45 = opposite / hypotenuse
sin 45 = a / 4
cross multiply
a = 4 × 0.70710678118
a = 2.83 units
Therefore,
cos 45 = b / 4
cross multiply
b = 0.70710678118 × 4
b = 2.82842712475
b = 2.83 units
Therefore, the legs are 2,83 units
learn more on right triangle here: https://brainly.com/question/29285631
#SPJ1
The mean of a set of numbers must be one of the numbers of the set. (7.SP.3.a)
Sometimes
Always
ONever
Answers
Answer:
The answer is Sometimes.
a learning theory would be most likely to emphasize the role of (fill in the blank) in the onset of anxiety disorders.
Answers
A learning theory would be most likely to emphasize the role of Classical conditioning in the onset of anxiety disorders.
Classical Conditioning:
Classical conditioning is a type of learning that occurs unconsciously.
In classical conditioned learning, automatically conditioned responses are paired with specific stimuli. This creates behavior.
Preconditioning:
At this stage, an unconditioned stimulus (UCS) produces an unconditioned response (UCR) in vivo. Basically, this means that the stimulus in the environment evoked an unlearned (i.e. unconditioned) behavior/response, and thus an untaught natural response. No new behavior has been learned in this regard.
For classical conditioning to be effective, the conditioned stimulus must occur before the unconditioned stimulus, rather than after or at the same time as the unconditioned stimulus. Thus, conditioned stimuli act as a kind of signal or cue for unconditioned stimulus.
To learn more about Classical Conditioning, refer:
https://brainly.com/question/15874680
#SPJ4
Marilyn wants to use a non-price competitive marketing strategy to gain more customers. Which of the following might she use?

Answers
As Marilyn wants to use a non-price competitive marketing strategy to gain more customers, the strategy that she might use is offering a promotion.
What is a Non-price competition in marketing?In marketing, the non-price competition refers to a marketing strategy in which a firm tries to distinguish its product or service from competing products on the basis of attributes like design and workmanship.
This competition most often occurs in an imperfectly competitive markets because it exists between producers that sell goods and services at same prices but competes to increase their respective market shares through different non-price measures such as marketing schemes and greater quality.
Read more about Non-price competition
brainly.com/question/12297704
#SPJ1
I Need help with this

Answers
Explain
7-4=3
All of the following could be rewritten as an addition problem of two integers with the same sign except _____.
-9 - (-12)
-9 - 12
-12 - 9
12 - (-9)
Answers
Answer:
Answer is - 9 + 12 because they have different signs in front of each integer. (if that is what the question means)
Step-by-step explanation:
Negative sign x negative sign = positive sign
-9 - (-12) = -9 + 12
-9 - 12
-12 - 9 = -9 - 12
12 - (-9) = 12 + 9 = 9 + 12
why are named constants used, rather than numbers, for token codes?
Answers
Named constants are used rather than numbers for token codes because they make the code more readable and easier to understand.
Constants are also used to avoid any errors that may occur if a number is mistyped. By using named constants, it is easier to update the value of the constant if it needs to be changed in the future. Additionally, using named constants can help prevent mistakes, such as accidentally using the wrong number in a calculation. Overall, named constants provide a more organized and efficient way of coding.
For example, consider the following code:
const int BLUE = 2;
const int GREEN = 3;
Instead of using the numbers 1, 2, and 3 in the code, we can use the named constants RED, BLUE, and GREEN. This makes the code more readable and easier to understand. If we need to change the value of one of the constants, we can simply update the value in one place, rather than having to search through the entire code for all instances of the number.
To know more about token codes click here:
https://brainly.com/question/29981815
#SPJ11
A line with slope 3 intersects a line with slope 5 at the point (10, 15). What is the distance between the x-intercepts of these two lines?
Answers
The distance between the intercepts of both lines is 2 units
The equation of a line in slope intercept form is:
\(y = mx + b\)
Where:
\(m \to\) slope
\(b \to\) y intercept
For the first line, we have:
\(m_1 = 3\) ---- the slope
So, the equation of the first line is:
\(y = 3x + b_1\)
For the second line, we have:
\(m_2 = 5\) --- the slope
So, the equation of the second line is:
\(y = 5x + b_2\)
Both lines intersect at (10,15) means that (10,15) is a common solution to the equation of both lines
i.e.
\((x,y) = (10,15)\)
Substitute these values in the first equation and solve for b
\(y = 3x + b_1\)
\(15 = 3*10 + b_1\)
\(15 = 30 + b_1\)
\(b_1 = 15 - 30\)
\(b_1 = -15\)
So, the equation of the first line is
\(y = 3x - 15\)
Repeat the same process for the second line
\(y = 5x + b_2\)
\(15 = 5*10 + b_2\)
\(15 = 50 + b_2\)
\(b_2 = 15 - 50\)
\(b_2 = -35\)
So, the equation of the second line is
\(y =5x - 35\)
The x intercept is when \(y =0\)
So, we substitute 0 for y and solve for x in the equations of both lines
For line 1
\(y = 3x - 15\)
\(0 = 3x - 15\)
\(3x= 15\) ---- Collect like terms
\(x = 5\) --- Divide both sides by 3
The x intercept of line 1 is 5
For line 2
\(y =5x - 35\)
\(0 = 5x - 35\)
\(5x = 35\) --- Collect like terms
\(x = 7\) -- Divide both sides by 5
The x intercept of line 2 is 7
The distance (d) between both is the difference in the intercepts:
\(d = 7 - 5\)
\(d = 2\)
Read more about intercepts at:
https://brainly.com/question/12791065
What is the standard form of the number shown in this calculator display?

Answers
Answer:
38,200,000
Step-by-step explanation:
Put the 3 in the 8th spot to the left of the decimal point and fill in the other digits to the right of it.
38,200,000
__
The first spot immediately to the left of the decimal point has a place value of 10^0, so the location with a place value of 10^7 is the 8th spot left of the decimal point. You should be able to get the idea from the attached.
__
If you put your calculator in the appropriate display mode, it should show you the number in this form.


Roger is training for the upcoming track season and records the number of miles that he runs each day for 20 days: 2.5, 0.5, 3.5, 4, 1.5, 5, 2, 2.5, 0.5, 4, 4.5, 3, 1.5, 1, 0.5, 2.5, 3, 5, 2.5, 0.5, 4, 4.5, 2, 4 which dotplot displays the data correctly? a dotplot titled roger apostrophe s training. a number line labeled miles run goes from 0.5 to 5 in increments of 0.5. 0.5, 4; 1, 1; 1.5, 2; 2, 2; 2.5, 3; 3, 2; 3.5, 0; 4, 3; 4.5, 2; 5, 1. a dotplot titled roger apostrophe s training. a number line labeled miles run goes from 0 to 3.5. 0, 4; 2.5, 3; 4, 3; 1.5, 2; 2, 2; 3, 2; 4.3, 2; 1, 2; 5, 1; 3.5, 0. a dotplot titled roger apostrophe s training. a number line labeled miles run goes from 0 to 5. 0, 4; 1, 1; 1.5, 2; 2, 2; 2.5; 3, 3, 2; 4, 3; 4.5, 2; 5, 1.
Answers
By examining the dotplot, you can see the frequency and distribution of the miles run by Roger. For example, there are 4 instances where Roger ran 0.5 miles, 3 instances where he ran 4 miles, and so on.
The dotplot that displays the data correctly is the one titled "Roger's Training" with a number line labeled "Miles Run" that goes from 0.5 to 5 in increments of 0.5. The dotplot should have the following data points:
0.5, 4
1, 1
1.5, 2
2, 2
2.5, 3
3, 2
3.5, 0
4, 3
4.5, 2
5, 1
This dotplot accurately represents the number of miles Roger ran each day over a 20-day period. Each dot represents a data point from the given list of miles run. The number line indicates the range of miles run, starting from 0.5 and ending at 5, with increments of 0.5.
By examining the dotplot, you can see the frequency and distribution of the miles run by Roger. For example, there are 4 instances where Roger ran 0.5 miles, 3 instances where he ran 4 miles, and so on. This visual representation allows you to easily interpret the data and observe any patterns or trends in Roger's training.
To learn more about dotplot
https://brainly.com/question/15853311
#SPJ11
i need help with some grade 10 math it's on slope I have attached a photo
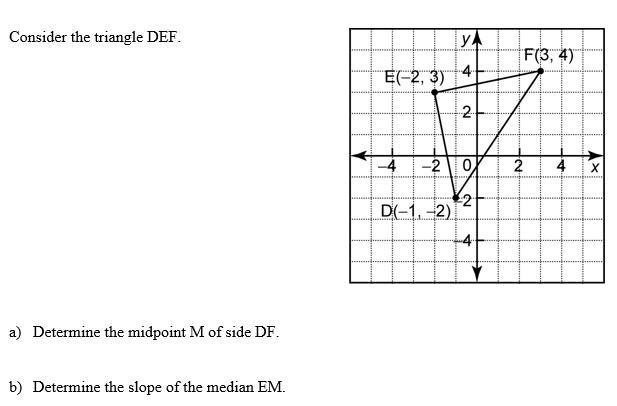
Answers
Answer:
a) (1,1)
b) 2/3
I think this is correct
Answer:
Co-ordinates of point M are ( 1, 1)
Slope of median EM = -2/3


What is the first step in solving the following equation?
28 = -12 - 4x
Answers
Answer:
4x = - 12 - 28Step-by-step explanation:
When we transpose - 4x to the LHS then it becomes positive i.e +4x
Now we transpose 28 to the RHS then it becomes negative i.e - 28
So the first step you have to is,
4x = - 12 - 28
Over the weekend Mary binge watched 3 out of the 12 seasons of her favorite television show. What percent of the shows did she watch?
Answers
Answer:
1/4 is answer.
Step-by-step explanation:
Divide 3 to 12 = 1/4
Hope this helps. :)
ANOVA F-statistic is defined as the Within Group Variation divided by the Between Group Variation. True False
Answers
False. The ANOVA F-statistic is defined as the Between Group Variation divided by the Within Group Variation.
In Analysis of Variance (ANOVA), we compare the variation between different groups (the Between Group Variation) to the variation within each group (the Within Group Variation). The F-statistic is the ratio of the Between Group Variation to the Within Group Variation.
The F-statistic is used to test the null hypothesis that the means of the different groups are equal. If the F-statistic is large and the associated p-value is small, we reject the null hypothesis and conclude that there is evidence of a difference between the means of the groups.
On the other hand, if the F-statistic is small and the associated p-value is large, we fail to reject the null hypothesis and conclude that there is not enough evidence to conclude that the means of the groups are different.
Learn more about ANOVA F-statistic here: brainly.com/question/31809956.
#SPJ11
Using the formula identify the constant of proportionality? y=7.6x
Answers
9514 1404 393
Answer:
7.6
Step-by-step explanation:
The equation is written in the form ...
y = kx . . . . . k is the constant of proportionality
where k = 7.6.
The constant of proportionality is 7.6.
PLEASE HELP IM STRUGGLING IN MATH!! THANK YOU!!!!❤️

Answers
Answer:
$5193.77
Step-by-step explanation:
You want to figure out what x is.
Since x is the number of years after 1996, you can do 2005 - 1996 = 9 years.
Then, plug x = 9 into the equation:
y = 11,000(0.92)^9
Plug this into a calculator and you get: y = $5193.77
help me with this question please

Answers
Answer:
N+1
Step-by-step explanation:
It begins with = 2
then n+1=3
then n+2=4 and so on it is n+1
Round 843,590 to the nearest thousand,
Answers
Answer:
844,000
Step-by-step explanation:
help me ;-;(with image)

Answers
Answer:
12
Step-by-step explanation:
A : B
1 : 3
Since we know that B is 3 times of A and A is 4...
1 unit = 4
3 units = 4 x 3 = 12
Factor the following:
36x^2 - 49
What is the vocabulary word describing the factors that result in this answer?
Answers
Answer:
(6x+7)(6x-7)
Step-by-step explanation:
This is an example of "Difference Of Squares".
Answer:
(6x - 7)(6x + 7).
The difference of 2 squares.
Step-by-step explanation:
Note that 36x^2 and 49 are perfect squares.
36x^2 - 49
= (6x - 7)(6x + 7).
Which of Polygons B, C, D, E, and F are similar to Polygon A?
Answers
Answer:
b and d
Step-by-step explanation:
jeremiah is testing the impact of different fertilizers on crop yields. six different fertilizers have been applied to one field. suppose he uses an anova to test whether or not there are differences in yields. how many treatments are in this test?
Answers
The impact of different fertilizers on crop which yields six different fertilizers have been applied to one field. here, the number of treatments in the test are 6.
Treatments are the numerous values of the factor.
The factor here is the effect of various fertilizers on crop yields.
Six different fertilizers were used.
As a result, the number of treatments equals the number of different fertilizers used = 6.
Fertilizers supply essential nutrients such as nitrogen to crops, allowing them to grow larger, faster, and produce more food. However, overfertilization can be a problem because it causes greenhouse gas emissions and eutrophication.
For more information on Fertilizers, visit :
https://brainly.com/question/3204813
#SPJ4
(2x+1)(3x+1)=35 using quandratic equation solve
Answers
Answer:
x = {-2 5/6, +2}
Step-by-step explanation:
To use the quadratic formula, it is helpful to write the equation in standard form.
(2x +1)(3x +1) = 35
6x^2 +5x -34 = 0 . . . . . . . subtract 35 and simplify. a=6, b=5, c=-34
The quadratic formula tells you the values of x are ...
\(x=\dfrac{-b\pm\sqrt{b^2-4ac}}{2a}=\dfrac{-5\pm\sqrt{5^2-4(6)(-34)}}{2(6)}\\\\=\dfrac{-5\pm\sqrt{841}}{12}=\dfrac{-5\pm29}{12}\\\\\boxed{x=\left\{-\dfrac{17}{6},2\right\}}\)
