The table shows the weights y
of x
pints of blueberries.
Number of Pints, x
0 1 2 3 4 5
Weight (pounds), y
0 0.8 1.50 2.20 3.0 3.80
a. Graph the data shown in the table using the coordinate plane provided to the right.
Question 1
b. A line that could best approximate the points could go through which two points below?
A line that could best approximate the points could go through Response area.
(0,0)
and (5,3.75)
(2,1.50)
and (4.5,2.25)
(0,0)
and (2,2.25)
Question 2
c. Use the points you chose in part (b) to write an equation of the line.
y=
y
=
d. Use the equation to predict the weight of 10 pints of blueberries.
Ten pints of blueberries weight about pounds.
e. Blueberries cost $2.25 per pound. Use the equation to predict how much 10 pints of blueberries will cost, to the nearest cent.
Ten pints of blueberries will cost about $
$
.
Question 3
PointMove
UndoRedoReset
PintsWeight (pounds)

Answers
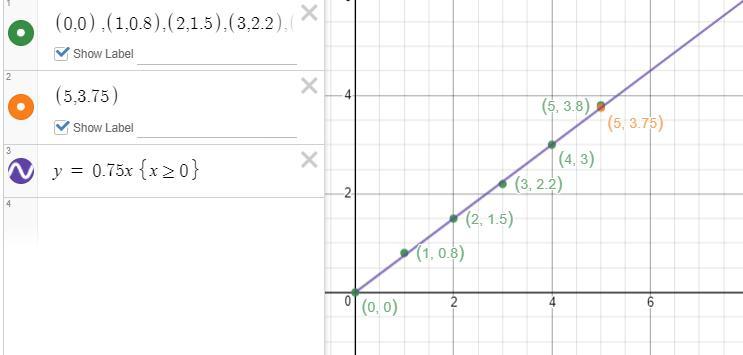
The table that shows the relationship between the weights of pints of blueberries is a linear regression function
The equation of the line is y = 0.75xTen pints of blueberries weigh about 7.5 pounds.Ten pints of blueberries will cost about $16.875The graphThe table entry is given as:
x 0 1 2 3 4 5
y 0 0.8 1.50 2.20 3.0 3.80
See attachment for the graph
The points on the lineA line that could best approximate the points could go through the origin (0,0) and (5,3.75)
The line equationWe have the points to be (0,0) and (5,3.75)
Since the line passes through the origin, the equation of the line would be:
\(y = \frac{y_2}{x_2}x\)
So, we have:
\(y = \frac{3.75}{5}x\)
\(y = 0.75x\)
Hence, the equation of the line is y = 0.75x
The weight of 10 pints of blueberriesThis means that x = 10.
So, we have:
y = 0.75 * 10
y = 7.5
Hence, ten pints of blueberries weigh about 7.5 pounds.
The cost of 10 pints of blueberriesThe unit rate is $2.25 per pound
Ten pints of blueberries weigh about 7.5 pounds.
So, the cost of 10 pints is:
Cost = 7.5 * 2.25
Cost = 16.875
Ten pints of blueberries will cost about $16.875
Read more about linear regression at:
https://brainly.com/question/17844286
Related Questions
What is the slope ? M=

Answers
Answer:
-3/2
Step-by-step explanation:
The slope is found by
m = ( y2-y1)/(x2-x1)
Using the points (-4,11) and ( 0,5)
m = ( 11-5)/( -4-0)
= 6/-4
= -3/2
Dallas has 5 fewer than 3 times as many marbles as Anthony. Anthony has x marbles. Enter an expression to represent the number of marbles Dallas has.
Answers
The expression that represent the number of marbles Dallas has is 3x - 5
How to determine the expression that represent the number of marbles Dallas has?From the question, we have the following parameters that can be used in our computation:
Dallas has 5 fewer than 3 times as many marbles as Anthony
Also from the question, we have
Anthony has x marbles
This means that
Anthony = x
So, we have
Dallas has 5 fewer than 3 times as many marbles as x
Express as equation
Dallas = 5 fewer than 3 times as many marbles as x
So, we have
Dallas = 5 fewer than 3x
Represent as equation
Dallas = 3x - 5
Hence, the expression is 3x - 5
Read more about expression at
https://brainly.com/question/4344214
#SPJ1
Hey guys, Please help me. Screenshots are below. I need them in the next 10 minutes. Please. I will also award brainiest!



Answers
HELP ME ITS A GRADE!!

Answers
Answer:
32/9
Step-by-step explanation:
Triangles â–łABC and â–łDFG are similar. The lengths of the two corresponding sides are 1. 4m , and 56 cm. What is the ratio of the perimeters of these triangles ?.
Answers
Answer:
5 : 2
Step-by-step explanation:
The ratio of perimeters of similar triangles is the same as the ratio of any pair of corresponding sides. That ratio is given as ...
1.4 m : 56 cm = 140 cm : 56 cm = 5 : 2
The ratio of the perimeters of the triangles is 5 : 2.
_____
As a unit ratio, it is 2.5 : 1, or 2.5.
A cylinder has a base radius of 5 centimeters and a height of 17 centimeters. What is its volume in cubic centimeters, to the nearest tenths place?
Answers
Find x in the triangle

Answers
Geometry: (ASAP!!! ((Pic included))
1. Underline the segments that are diagonals
2. Name all the diagonals that have A as the first vertex

Answers
Answer:
14. EA, EB, EC, EG
15. AC, AD, AE, A F
i need the answer quickly


Answers
Answer:
scatter plot 3
Step-by-step explanation:
No correlation exists when there is no relationship between two variables. For example there is no relationship between the x-axis to the y-axis while the other plots has noticeable linear correlation.
In simplest form, what is the quotient of 1/6 divided by 2/9?
Answers
step by step: The numbers in 1/6 divided by 2/9 are labeled below:
1 = dividend numerator
6 = dividend denominator
2 = divisor numerator
9 = divisor denominator
To make it a fraction form answer, you multiply the dividend numerator by the divisor denominator to make a new numerator.
Furthermore, you multiply the dividend denominator by the divisor numerator to make a new denominator:
1 x 9
6 x 2
=
9
12
Thus, the answer to 1/6 divided by 2/9 in fraction form is:
9
12
To make the answer to 1/6 divided by 2/9 in decimal form, you simply divide the numerator by the denominator from the fraction answer above:
9/12 = 0.75
The answer is rounded to the nearest four decimal points if necessary.
9/12 can be simplified to 3/4.
What could be the value X ??? PLEASE HELP !!!!!!!!!!!! I WILL MARK BRIANLIEST

Answers
Answer:
51
Step-by-step explanation:
I mean it should add up to 180 so
180 = 63+66+x
x=51
Answer:
51
Step-by-step explanation:
Since there are two angles already filled in, we should know that a straight line equals 180°, meaning that we can add the two angles we already have (which makes 129) and subtract it by 180
180
- 129
____
51
If the turkey says gobble, gobble, gobble, and a peach says cobbler, cobbler, cobbler, what would a computer say?
Answers
Answer: error
Step-by-step explanation:
Answer:
goog le goo gle go ogle
Step-by-step explanation:
sorry but the problem is that brainly thinks Goo gle is too inappropriate of a word
how do you find line of best fit on a table
Answers
To find the line of best fit on a table, you can use a technique called linear regression.
Linear regression helps determine the relationship between two variables and allows you to create a line that represents the best fit for the data points.
Drawing a straight line on a scatter plot with nearly equal numbers of points above and below it (and passing through as many points as feasible) can allow you to roughly estimate the line of best fit.
Learn more about linear regression click;
https://brainly.com/question/14313391
#SPJ1
Show transcribed dataSuppose that a particular NBA player makes 94% of his free throws. Assume that late in a basketball game, this player is fouled and is awarded two free throws. a. What is the probability that he will make both free throws? (to 4 decimals) b. What is the probability that he will make at least one free throw? (to 4 decimals) c. What is the probability that he will miss both free throws? (to 4 decimals) d. Late in a basketball game, a team often intentionally fouls an opposing player in order to stop the game clock. The usual strategy is to intentionally foul the other team's worst free-throw shooter. Assume the team's worst free throw shooter makes 56% of his free throws. Calculate the probabilities for this player as shown in parts (a), (b), and (c), and show that intentionally fouling this player who makes 56% of his free throws is a better strategy than intentionally fouling the player who makes 94% of his free throws. Assume as in parts (a), (b), and (c) that two free throws will be awarded. What is the probability that this player will make both throws? (to 4 decimals) What is the probability that will make at least one throw? (to 4 decimals) What is the probability that this player will miss both throws? (to 4 decimals)
Answers
the probability of him making at least one free throw is lower (0.8044 vs. 0.9964), which means the opposing team has a better chance of preventing the other team from scoring points.
a. To find the probability that the player will make both free throws, we simply multiply the probability of making one free throw by itself: 0.94 * 0.94 = 0.8836 (to 4 decimals).
b. To find the probability that he will make at least one free throw, we can use the complement rule. The complement of making at least one free throw is missing both free throws, so we can find the probability of missing both free throws and subtract that from 1: 1 - 0.06 * 0.06 = 0.9964 (to 4 decimals).
c. To find the probability that he will miss both free throws, we multiply the probability of missing one free throw by itself: 0.06 * 0.06 = 0.0036 (to 4 decimals).
d. For the team's worst free throw shooter who makes 56% of his free throws, the probabilities are as follows:
a. The probability of making both free throws is 0.56 * 0.56 = 0.3136.
b. The probability of making at least one free throw is 1 - the probability of missing both free throws: 1 - 0.44 * 0.44 = 0.8044.
c. The probability of missing both free throws is 0.44 * 0.44 = 0.1936.
Comparing the probabilities for the two players, we can see that intentionally fouling the worst free throw shooter is a better strategy. This is because the probability of him missing both free throws is higher (0.1936 vs. 0.0036), which means the opposing team has a greater chance of gaining possession of the ball. In addition, the probability of him making at least one free throw is lower (0.8044 vs. 0.9964), which means the opposing team has a better chance of preventing the other team from scoring points.
To know more about complement rule click here:
brainly.com/question/29146128
#SPJ4
In order to set premiums at profitable levels, insurance companies must estimate how much they will have to pay in claims on cars of each make and model, based on the value of the car and how much damage it sustains in accidents. Let C be a random variable that represents the cost of a randomly selected car of one model to the insurance company. The probability distribution of C is given below.$0С$500 $1000 $2000Р(С) | 0.60 | 0.05 0.13 0.22The standard deviation is s = $817.60 . Interpret this value in context.Question 02)A professor gave a short quiz and tracked the number of questions the students missed. The results are in the probability distribution listed below where X = the number of questions missed on the quiz.If the professor selects a student from the class at random, what’s the probability this student missed at least two questions on the quiz?Please answer both to get a thumbs up.
Answers
Part 1: The standard deviation of $817 indicates the average amount of variation,
Part 2: The probability that a randomly selected student from the class missed at least two questions on the quiz is 0.7 or 70%.
Part 1:
Insurance companies estimate claim payments for cars based on make, model, value, and accident damage.
The random variable C represents the cost of a randomly selected car of one model to the insurance company.
The probability distribution of C is as follows:
P(C = $0) = 0.60
P(C = $500) = 0.05
P(C = $1000) = 0.13
P(C = $2000) = 0.22
The standard deviation (s) is given as $817.
Interpreting the Standard Deviation in Context The standard deviation (s) of $817 represents the measure of the average amount of variation or dispersion in the cost of cars for the given insurance company. A higher standard deviation indicates a wider range of car costs, suggesting that the insurance company faces a higher level of financial risk when setting premiums for different car models.
Part 2:
The professor gave a short quiz and tracked the number of questions missed.
X represents the number of questions missed on the quiz (random variable).
The specific probability distribution for X is not provided in the question.
To calculate the probability that a randomly selected student from the class missed at least two questions on the quiz,
We need the probability distribution for X, the number of questions missed on the quiz.
Since the distribution is not provided, we'll assume a hypothetical distribution for the purpose of calculation.
Assume the following hypothetical probability distribution for X:
X: Number of questions missed on the quiz
P(X): Probability
P(X = 0) = 0.1
P(X = 1) = 0.2
P(X = 2) = 0.3
P(X = 3) = 0.2
P(X = 4) = 0.1
P(X = 5) = 0.1
To find the probability that a student missed at least two questions, we need to sum the probabilities of all outcomes where X is greater than or equal to 2:
P(X ≥ 2) = P(X = 2) + P(X = 3) + P(X = 4) + P(X = 5)
P(X ≥ 2) = 0.3 + 0.2 + 0.1 + 0.1 P(X ≥ 2) = 0.7
Therefore, the probability that a student missed at least two questions on the quiz is 0.7 or 70%.
Learn more about the probability visit:
https://brainly.com/question/13604758
#SPJ4
Please help its line segment

Answers
Answer:
-9 3/4
Step-by-step explanation:
FG = GH
9x+15 = 5x+4
Subtract 5x from each side
9x+15-5x = 5x+4-5x
4x+15 = 4
Subtract 15 from each side
4x+15-15 = 4-15
4x = -11
Divide by 4
4x/4 = -11/4
x = -11/4
FG = 9x+15
FG = 9*(-11/4) +15
= -99/4+15
-99/4 + 60/4
= -39/4
= -9 3/4
Suppose an nth order homogeneous differential equation has
characteristic equation (r - 1)^n = 0. What is the general solution
to this differential equation?
Answers
The general solution to the nth order homogeneous differential equation with characteristic equation\((r - 1)^n\) = 0 is given by y(x) = c₁\(e^(^x^)\) + c₂x\(e^(^x^)\) + c₃x²\(e^(^x^)\) + ... + cₙ₋₁\(x^(^n^-^1^)e^(^x^)\), where c₁, c₂, ..., cₙ₋₁ are constants.
When we have a homogeneous linear differential equation of nth order, the characteristic equation is obtained by replacing y(x) with \(e^(^r^x^)\), where r is a constant. For this particular equation, the characteristic equation is given as \((r - 1)^n\) = 0.
The equation \((r - 1)^n\) = 0 has a repeated root of r = 1 with multiplicity n. This means that the general solution will involve terms of the form \(e^(^1^x^)\), x\(e^(^1^x^)\), x²\(e^(^1^x^)\), and so on, up to\(x^(^n^-^1^)\)\(e^(^1^x^)\).
The constants c₁, c₂, ..., cₙ₋₁ are coefficients that can be determined by the initial conditions or boundary conditions of the specific problem.
Each term in the general solution corresponds to a linearly independent solution of the differential equation.
The exponential term \(e^(^x^)\) represents the basic solution, and the additional terms involving powers of x account for the repeated root.
In summary, the general solution to the nth order homogeneous differential equation with characteristic equation \((r - 1)^n\) = 0 is y(x) = c₁\(e^(^x^)\)+ c₂x\(e^(^x^)\) + c₃x²\(e^(^x^)\) + ... + cₙ₋₁\(x^(^n^-^1^)e^(^x^)\), where c₁, c₂, ..., cₙ₋₁ are constants that can be determined based on the specific problem.
Learn more about differential equations
brainly.com/question/28921451
#SPJ11
10. Calculpte the slope using these two points. (7,1) and (4,8)
A. 7/3
B. -7/3
C. 9/11
D. 2/3
Help please
Answers
Answer:
B
Step-by-step explanation:
slope is y2-x2/y1-x1
So, 8-1/4-7
Or, -7/3
so its B
Hope this helps plz hit the crown :D
Mrs.Taay’s is a franchise chain selling Ha Long bubble yogurt, a local specialty which made of yogurt and warm pearls with coconut milk. Currently, their menu has 10 different flavours of yogurt, whose ingrdients are plain yogurt and flavoured syrup.
As this chain is opening many new stores every quarter, the chain's managers try to find a way to optimize their production, aiming for a customer servicelevel of 95%.
Assuming that weekly demand at a specific store for each flavor is independent and normally distributed with N(100,144), while the replenishment lead time from the chain's factory is one week
a. How much safety stock will this store have to hold if the yogurt is flavoured at the chain's factory and held in inventory at the store as individual yogurt flavors?
b. How much safety stock will this store have to hold if the store holds plain yogurt and flavored syrups (supplied by the chain's factory) separately and only mixes falvors on demand?
c. Which option may conclude a less quantity of safety stock? What is the gap of safety stock between these two alternatives?
Answers
A. If the yogurt is flavored at a chain facility and stocked in the store as different yogurt flavors, the store must keep a separate safety stock for each flavor.
B. If the store only adds flavors on demand and keeps plain yogurt and flavored syrup separate.
C. In the second scenario, in which the store keeps plain yogurt and flavored syrup separately, the amount of safety stock will be minimal.
While calculating the safety stock required in each situation we must take into account the variation in demand and the lead time for replenishment.
A. Safety stock is used to account for the unpredictability of demand and guarantee that there is enough inventory to meet customer demand during the lead time for replenishment.
B. In this example the business keeps the plain yogurt and flavored syrup separate, allowing customers to mix the flavors. Because the retailer is not required to keep a safety stock for every flavor, the amount required will be less than in the previous case.
C. The need for surplus inventory is reduced because flavors are mixed on demand, allowing the business to alter the proportions based on consumer preferences. Precise demand fluctuations and lead time considerations will determine the safety stock difference between these two options, which will require additional computations based on available data.
Learn more about Safety stock, here:
https://brainly.com/question/30906540
#SPJ4
Write 565,000 in scientific notation.AnswerX10
Answers
The given number is
\(565000\)The scientific notation of the number is,
\(5.65\times10^5\)James is making a math final for his students. He already has 22 questions, and can make 12 more for every hour. Which is an equation that represents how many questions (q) he has for every hour (h)?
a.q(h) = 12h
b.q(h) = 22h + 12
c. q(h) = 12h + 22
d.q(h) = 12h-22
Answers
a) use these data to estimate the mean wrist extension for people using this new mouse design using a 90% confidence interval. (round your answers to three decimal places.) , (b) what assumptions are required in order for it to be appropriate to generalize your estimate to the population of students at this university? yes, the assumption would have to be made that the 24 students in the study formed a random sample of people in the country. no, we can generalize the estimate to the population of students at this university. yes, the assumption that the 24 students in the study formed a random sample of students at all universities. yes, the assumption would have to be made that the 24 students in the study formed a random sample of students at this university. no, we cannot generalize the estimate to any population as we have less than 30 students. to the population of all university students? no, we cannot generalize the estimate to any population as we have less than 30 students. yes, the assumption would have to be made that the 24 students in the study formed a random sample of people in the country. yes, the assumption would have to be made that the 24 students in the study formed a random sample of students from this university. no, we can generalize the estimate to the population of all university students. yes, the assumption that the 24 students in the study formed a random sample of students at all universities. (c) based on your interval from part (a), do you think there is reason to believe that the mean wrist extension for people using the new mouse design is greater than 20 degrees? explain why or why not. no, the entire confidence interval is below 20, so the results of the study would be very likely if the population mean wrist extension were greater than 20. no, the confidence interval contains 20, so the results of the study would be very likely if the population mean wrist extension were greater than 20. yes, the confidence interval contains 20, so the results of the study would be very unlikely if the population mean wrist extension were as low as 20. yes, the entire confidence interval is above 20, so the results of the study would be very unlikely if the population mean wrist extension were as low as 20.
Answers
The random sample of \(24\) students has a mean of \(1.9149\), and the data suggests that the mean is \(20^{0}\).
How to Use the Sample Mean Formula to Determine the Sample Mean?x = (xi) / n is the general solution for computing the sample mean. Thus, xi refers to all X sample values, xi represents the sampling distribution, and n is the total number of specimen terms inside the data collection.
What does sample in statistics mean?The statistic known as the sampling distribution is created by arithmetically averaging the values of the variables in a group. The sample mean is an estimate of the anticipated value if the sample is taken from probabilistic with a common expected value.
(a) Sample mean \(= (17 + 21 + 20 + 19 + 23 + 22 + 20 + 20 + 18 + 21 + 19 + 24 + 22 + 20 + 19 + 20 + 19 + 20 + 21 + 22 + 23 + 21 + 18 + 22)/24 = 20.5\)Sample standard deviation \(= 1.9149\)
Next, we can use a t-distribution with \(23\) degrees of freedom
Confidence interval \(= (20.5 - 0.8277, 20.5 + 0.8277) = (19.6723, 21.3277)\)
b) The assumption required in order to generalize the estimate to the population of students at this university is that the \(24\) students in the study formed a random sample of students at this university.
(c) There is not enough evidence to suggest that the mean wrist extension for people using the new mouse design is greater than \(20^{0}\).
To know more about Sample mean visit:
https://brainly.com/question/30023845
#SPJ1
I really need help fast and ill do anything just help me plz

Answers
C = pi x diameter
Diameter = 20cm
You times pi by 20cm (diameter) to get the circumference of approx 62.84cm
Then times the circumference by the angle in the circle
62.84 x 70/360 = 12.22cm
PLISSSSSS HELP!!!!!!!!!!!!!
i will give brainliest.....

Answers
Product is multiplication.
First multiply 0.7 by 2:
0.7 x 2 = 1.4
Because there is only one number to the left of the decimal point the scientific notation remains the same 10^4
The answer is 1.4 x 10^4
Eight friends share 64 tickets to the school carnival. Each friend has the same
number of tickets. How many tickets does each friend have?
9
7
6
8
Answers
Answer:
Step-by-step explanation:
Please tell me the correct answer. If u answer correct I’ll mark u as brainiest. I really need help.

Answers
Answer:
b
Step-by-step explanation:
324/100 into a mixed fraction
Answers
The reason why is, because fractions are technically dividing two numbers. So, we can do 324 divided by 100, getting us 3.24 or 3 24/100. Then we’re able to simplify the fraction into 6/25 by dividing it by 4, leaving us with an answer of 3 6/25.
Hopefully this helped!
Help pls help pls help pls help pls help pls

Answers
Answer:
Domain: -2 < x ≤ 3
General Formulas and Concepts:
Algebra I
Domain is the set of x-values that can be inputted into function f(x)Step-by-step explanation:
Since domain encompasses x values only, we are looking at the x-values of the graph. We see that our x-values span from -2 to 3. However, since x = -2 is a open dot, it is NOT included in the domain. Since x = 3 is a closed dot, it IS included in the domain:
(-2, 3] or -2 < x ≤ 3
Answer:
ramen is the true answer to lifes problems
Step-by-step explanation:
If A and B are independent events, P(A) = 0.4, and P(B) = 0.5, what is P(BIA)?

Answers
Answer:
A 0.5
Step-by-step explanation:
p(b/a) = (p(a) × p(b))/p(a)
If A and B are independent events, P(A) = 0.4, and P(B) = 0.5, P(BIA) = 0.5 .So, correct option is A.
In probability theory, two events A and B are considered independent if the occurrence of one event does not affect the probability of the other event happening. Mathematically, this is represented as P(A ∩ B) = P(A) * P(B).
In this case, we are given that events A and B are independent, and we know the probabilities of each individual event: P(A) = 0.4 and P(B) = 0.5.
The probability of both events A and B occurring (denoted as P(A ∩ B) or P(B ∩ A)) is the product of their individual probabilities: P(A ∩ B) = P(A) * P(B).
So, P(B|A) represents the conditional probability of event B occurring given that event A has already occurred. Since A and B are independent, the occurrence of A doesn't affect the probability of B happening. Therefore, P(B|A) is equal to P(B), which is 0.5.
In summary, P(B|A) = P(B) = 0.5, as events A and B are independent, and the probability of B occurring is unaffected by the occurrence of A.
So, correct option is A.
To learn more about probability/events click on,
https://brainly.com/question/28502755
#SPJ2
If mike read 30 pages an hour how long will it take him to read 1225 pages
Answers
Answer: 2450 min or 40hr and 50 min
Step-by-step explanation:
We can use a proportion to set up this equation.
\(\frac{30 pages}{60 min} =\frac{1225 pages}{x min}\)
We cross muliply so get our equation.
\(30x=1225(60)\\\)
\(30x=73500\)
\(x=2450 min\)
It took Mike 2450 min to read 1225 pages. We can also use a proportion to write this in hours
\(\frac{60min}{1hr} =\frac{2450min}{x }\)
\(60x=2450\)
\(x=40 hr 50 min\)