PLEASE URGENT I DONT WANNA FAIL
Natalia has reflected point A across the line x = -2, as shown above, and labeled this point as A'.
Do you believe she has plotted the correct A'? Please explain your thinking.

Answers
Answer:
She has not plotted it correctly.
Step-by-step explanation:
Point A’ should be at (0,2)
Related Questions
For the expression startfraction 9 x squared minus 8 over (3 x squared minus 4) squared endfraction, which sum represents the correct form of the partial fraction decomposition?
Answers
To find the correct form of the partial fraction decomposition for the expression: \(\(\frac{9x^2 - 8}{(3x^2 - 4)^2}\)\)
We need to factor the denominator and decompose it into partial fractions. Let's factor the denominator first:
\(\(3x^2 - 4 = (3x - 2)(x + 2)\)\)
Now, we can decompose the expression into partial fractions using the following general form:
\(\(\frac{A}{3x - 2} + \frac{B}{x + 2} + \frac{C}{(3x - 2)^2} + \frac{D}{(x + 2)^2}\)\)
To determine the values of A, B, C, and D, we need to find the common denominator and equate the numerators:
\(\(9x^2 - 8 = A(x + 2)(3x - 2) + B(3x - 2)(x + 2) + C(x + 2) + D(3x - 2)\)\)
Now, we can solve for A, B, C, and D by comparing the coefficients of like terms on both sides of the equation.
However, by following the steps outlined above, you can determine the specific values and complete the partial fraction decomposition.
Learn more about partial fraction here:
brainly.com/question/30401693
#SPJ11
find the value of x in the equation 5 - 3 (x + 1) = 4x - 40
Answers
Answer:
Step-by-step explanation:
To solve for x in the equation 5 - 3(x + 1) = 4x - 40, we can simplify and rearrange the terms as follows:
5 - 3(x + 1) = 4x - 40
5 - 3x - 3 = 4x - 40 (distribute the -3)
2x = 32 (add 3x to both sides and add 40 to both sides)
x = 16 (divide both sides by 2)
Therefore, the value of x in the equation 5 - 3(x + 1) = 4x - 40 is 16.
Answer:
x = 6
Step-by-step explanation:
5 - 3(x + 1) = 4x - 40 ← distribute parenthesis and simplify left side
5 - 3x - 3 = 4x - 40
2 - 3x = 4x - 40 ( subtract 4x from both sides )
2 - 7x = - 40 ( subtract 2 from both sides )
- 7x = - 42 ( divide both sides by - 7 )
x = 6
The number of student of schoolwas 450 last year and it is 396 this year.By how many percent did the number decrease
Answers
Step-by-step explanation:
450 - 396 = 54
(54/450) * 100% = 12%
Hence the decrease is 12%.
Answer:
12%Step-by-step explanation:
The way to solve is to divide the number.
396/450 = 0.88 or 88%
Now, we subtract 88 from 100 to get 12, since we wanted the percent decrease.
What is the general form of the equation of the line shown?
x + y + 2 = 0
x + y - 2 = 0
x - y - 2 = 0
Answers
Answer:
\( { \tt{x + y + 2 = 0}} \\ y = - x - 2 \\ \\ { \tt{x + y - 2 = 0}} \\ y = - x + 2 \\ \\ { \tt{x - y - 2 = 0}} \\ - y = - x + 2 \\ y = x - 2\)
Can someone please help I will be giving Brainliest to whoever can answer :)
Match the questions with the graphs that are labeled A-H. (keep in mind that some questions might have the same answer)
1. A = {(x, y): y > x^2}
2. B = {(x, y): y ≥ x^2+ 3}
3. C = {(x, y): y ≤ 3x^2 + 2}
4. D = {(x, y): y ≥ 2x^2- 5x + 1}





Answers
The inequalities are matched with their correct graph respectively as follows:
D ⇒ {(x, y): y > x²}.G ⇒ {(x, y): y ≥ x²+ 3C ⇒ {(x, y): y ≤ 3x² + 2}A ⇒ {(x, y): y ≥ 2x² - 5x + 1}J ⇒ x²- 3x ≥ 0H ⇒ x² - 3x + 2 ≤ 0B ⇒ {(x, y): y ≤ 1 - x²} B ⇒ {(x, y): y ≥ -1}What is a graph?A graph can be defined as a type of chart that's commonly used to graphically represent data on both the horizontal and vertical lines of a cartesian coordinate, which are the x-axis and y-axis.
What is an inequality?An inequality can be defined as a mathematical relation that compares two (2) or more integers and variables in an equation based on any of the following arguments:
Less than (<).Greater than (>).Less than or equal to (≤).Greater than or equal to (≥).In Geometry, if the leading coefficient of a quadratic equation is greater than (>) zero, the parabolic curve would open upward while the parabolic curve would open downward when the leading coefficient of a quadratic equation is less than (<) zero.
Read more on graph of inequalities here: https://brainly.com/question/24372553
#SPJ1
Complete Question:
Match the questions with the graphs that are labeled A-H. (keep in mind that some questions might have the same answer)
1. A = {(x, y): y > x^2}
2. B = {(x, y): y ≥ x^2+ 3}
3. C = {(x, y): y ≤ 3x^2 + 2}
4. D = {(x, y): y ≥ 2x^2- 5x + 1}
6. x^2- 3x ≥ 0
7. x^2- 3x + 2 ≤ 0
8. {(x, y): y ≤ 1 - x^2}
9. {(x, y): y ≥ -1}
When displaying quantitative data, what is an ogive used to plot? Multiple Choice Frequency or relative frequency of each class against the midpoint of the corresponding class Cumulative frequency or cumulative relative frequency of each class against the upper limit of the corresponding class Frequency or relative frequency of each class against the midpoint of the corresponding class and cumulative frequency or cumulative relative frequency of each class against the upper limit of the corresponding class None of the above
Answers
An ogive is used to plot cumulative frequency or cumulative relative frequency of each class against the upper limit of the corresponding class when displaying quantitative data. Option B.
An ogive is a graph that represents a cumulative distribution function (CDF) of a frequency distribution. It shows the cumulative relative frequency or cumulative frequency of each class plotted against the upper limit of the corresponding class. In other words, an ogive can be used to represent data through graphs by plotting the upper limit of each class interval on the x-axis and the cumulative frequency or cumulative relative frequency on the y-axis.
An ogive is used to display the distribution of quantitative data, such as weight, height, or time. It is also useful when analyzing data that is not easily represented by a histogram or a frequency polygon, and when we want to determine the percentile or median of a given set of data. Based on the information given above, option B: "Cumulative frequency or cumulative relative frequency of each class against the upper limit of the corresponding class" is the correct answer.
More on an ogive: https://brainly.com/question/10870406
#SPJ11
A survey asked 1000 recently retired people how many different vehicles they owned during their working lives. The table below is a probability distribution table representing the data collected. Find the mean and the standard deviation of the probability distribution using Excel. Round the mean and standard deviation to three decimal places.
Answers
A survey asked 1000 recently retired people about the number of different vehicles they owned during their working lives. The goal is to find the mean and standard deviation of the probability distribution based on the collected data.
To calculate the mean and standard deviation of the probability distribution, the data collected from the survey can be analyzed using Excel. The probability distribution table represents thre fequency distribution of the number of vehicles owned. Each value of the number of vehicles owned corresponds to a specific probability.
In Excel, the mean can be calculated by multiplying each value by its corresponding probability, summing up the products, and dividing by the total number of values. This yields the average number of vehicles owned.
The standard deviation can be calculated by using the formula =STDEV.P(range), where the range is the data set of the number of vehicles owned. This formula calculates the standard deviation of a population, assuming that the data represents the entire population of retired individuals.
By applying these calculations in Excel, rounding the results to three decimal places, the mean and standard deviation of the probability distribution can be determined.
Learn more about probability:
https://brainly.com/question/32117953
#SPJ11
Write a triple integral for f(x, y, z) = xyz over the solid region Q for each of the six possible orders of integration. Q = {(x, y, z): 0 ≤ x ≤ 1, 0 ≤ y ≤ 7x, 0 ≤ z ≤ 3}
Evaluate one of the triple integrals
Answers
For the function f(x, y, z) = xyz and the solid region Q defined as Q = {(x, y, z): 0 ≤ x ≤ 1, 0 ≤ y ≤ 7x, 0 ≤ z ≤ 3}, we can write the triple integral in six different orders of integration.
Each order represents a different sequence of integrating with respect to the variables x, y, and z. One of the triple integrals will be evaluated.
The six possible orders of integration for the triple integral of f(x, y, z) = xyz over the solid region Q = {(x, y, z): 0 ≤ x ≤ 1, 0 ≤ y ≤ 7x, 0 ≤ z ≤ 3} are as follows:
dz dy dx: Integrate first with respect to z, then y, and finally x. The limits of integration are z = 0 to z = 3, y = 0 to y = 7x, and x = 0 to x = 1.
dz dx dy: Integrate first with respect to z, then x, and finally y. The limits of integration are z = 0 to z = 3, x = 0 to x = 1, and y = 0 to y = 7x.
dx dz dy: Integrate first with respect to x, then z, and finally y. The limits of integration are x = 0 to x = 1, z = 0 to z = 3, and y = 0 to y = 7x.
dx dy dz: Integrate first with respect to x, then y, and finally z. The limits of integration are x = 0 to x = 1, y = 0 to y = 7x, and z = 0 to z = 3.
dy dz dx: Integrate first with respect to y, then z, and finally x. The limits of integration are y = 0 to y = 7x, z = 0 to z = 3, and x = 0 to x = 1.
dy dx dz: Integrate first with respect to y, then x, and finally z. The limits of integration are y = 0 to y = 7x, x = 0 to x = 1, and z = 0 to z = 3.
Now, let's evaluate one of the triple integrals, specifically the one with the order of integration dz dy dx:
∫∫∫xyz dz dy dx over the limits z = 0 to 3, y = 0 to 7x, and x = 0 to 1.
By evaluating this triple integral, we can find the numerical value of the integral and hence the answer to the specific computation.
To learn more about variables click here:
brainly.com/question/15078630
#SPJ11
Find the solution of the system of equations
8x+2y=38
2x-4y=-4
Answers
The solution of the system of equations is (4, 3)
How to solve the system of equations?Here we want to solve the system below:
8x+2y=38
2x-4y=-4
If we add 2 times the first equation and the second equation we will get:
2*(8x + 2y) + (2x - 4y) = 2*38 - 4
16x + 4y + 2x - 4y = 72
18x = 72
x = 72/18 = 4
And the vale of y is given by inputing x = 4 in one of the two equations.
2*4 - 4y = -4
8 - 4y = -4
-4y = -4 - 8
y = -12/-4 = 3
The solution is (4, 3)
Learn more about systems of equations at:
https://brainly.com/question/13729904
#SPJ1
the number of salmon observed in the sacramento river and the feather river in the last five years were counted and listed in the chart below: which of the following statements is true about the relation represented in the table? the relation is a function. the relation is not a function. there is not enough information to determine if it is a function or not.
Answers
The correct option is the relation is not a function.
A function is defined as a relation in which each input has exactly one output. A relation is any set of ordered pairs. According to the given chart:|Year|Sacramento River|Feather River| 2008|271,999|0| 2009|123,739|0| 2010|174,948|16,857| 2011|158,956|22,129| 2012|163,603|19,799| As we can see in the table, the Sacramento river has different number of salmon at a given year.
For example, in the year 2008, there are 271,999 salmon in the Sacramento river, in the year 2009, there are 123,739 salmon in the Sacramento river. The same with the Feather river. There is a year when there are zero salmon and there are years with different number of salmon.
Therefore, this relation is not a function. Hence, the correct option is the relation is not a function.
To know more about function, refer here:
https://brainly.com/question/12431044#
#SPJ11
this question was solved wronlgy on chegg help us to solve it
correclty please . g1 ,g2 be careful pf the values answer here in
chegg is wrong becuse values are swapped .
ans it correclty .
Consider the \( (2,1,2) \) convolutional code with: \[ \begin{array}{l} g^{(1)}=\left(\begin{array}{lll} 0 & 1 & 1 \end{array}\right) \\ g^{(2)}=\left(\begin{array}{lll} 1 & 0 & 1 \end{array}\right) \
Answers
The correct answer is
\(\[\boxed{\begin{array}{l}G = \left[ {\begin{array}{*{20}{c}}1&0&0&0&1&1\\0&1&0&1&0&1\end{array}} \right]\end{array}}\].\)
The wrong answer on Chegg for the generator matrix is due to swapped values.
Given that the convolutional code is (2, 1, 2) with:
\(\[\begin{array}{l}g^{(1)} = \left( {\begin{array}{*{20}{l}}0&1&1\end{array}} \right)\\g^{(2)} = \left( {\begin{array}{*{20}{l}}1&0&1\end{array}} \right)\end{array}\]\)
Here we can see that there are two generator matrices, which are given as
:g1 = [0 1 1]g2 = [1 0 1]
We have to find the generator matrix (G) for the above convolutional code (2, 1, 2).
Formula to calculate generator matrix G for convolutional code is:
G = [I_k | T] , where T = [g1, g2 g1 + g2].
Here k is the number of states in the convolutional encoder, which is equal to 2 in this case.
Since we have g1 and g2, we can find T as follows:
\(\[T = \left[ {\begin{array}{*{20}{c}}0&1&1&1&0&1\end{array}} \right]\]where g1 + g2 is equal to [1 1 0].\)
Since we have the matrix T, we can now calculate G as follows:
\(\[G = \left[ {\begin{array}{*{20}{c}}1&0&0&0&1&1\\0&1&0&1&0&1\end{array}} \right]\]\)
Thus, the generator matrix G for the convolutional code (2, 1, 2) is:
\(\[G = \left[ {\begin{array}{*{20}{c}}1&0&0&0&1&1\\0&1&0&1&0&1\end{array}} \right]\]\)
Therefore, the correct answer is
\(\[\boxed{\begin{array}{l}G = \left[ {\begin{array}{*{20}{c}}1&0&0&0&1&1\\0&1&0&1&0&1\end{array}} \right]\end{array}}\].\)
The wrong answer on Chegg for the generator matrix is due to swapped values.
To know more about generator matrix
https://brainly.com/question/31971440
#SPJ11
On a loan of $4,500 for 2 1/2 years at 4% per year, how much do you wind up paying to pay off the loan?
Answers
Answer:
4,950
Step-by-step explanation:
4,500*.10=450
4,500+450=4,950
Hope this helps:)
What is the length of the dotted line in the diagram below? Leave your answer in
simplest radical form.

Answers
Shoes selling price is $1099. It costs $413.50 to make. What is the percent markup?
Answers
Answer:
166%
Step-by-step explanation:
Shoes selling price is $1099. It costs $413.50 to make. What is the percent markup?
1099/413.50=266%
266&-100%=166%
what is the answer too 2/3x-7=11
Answers
Answer:
x = 27
Step-by-step explanation:
Add 7 to both sides to isolate x:
2/3x -7 = 11
2/3x = 18
Divide each side by 2/3:
x = 27
the answer is below hope it will help

select all the statements that are true. 7.107 > 7.017 0.200 = 0.200 10.220 < 10.022 8.008 < 8.080 13.190 > 13.090
Answers
Answer:
7.107 > 7.017
0.200 = 0.200
8.008 < 8.080
13.190 > 13.090
What’s ах — b = Р solves for x
Answers
Answer: x = b + p/a
Step-by-step explanation: First add b to both sides to get ax = b + p.
Now divide both sides by a to get x = b + b/a.
Evaluate each logarithm.
log₂2⁵
Answers
After evaluating the logarithm log₂ 2⁵, we get the result as 5.
The common logarithm is also known as the base 10 logarithm. It is represented by log10 or simply log.
For example, the common logarithm of 1000 is written as log(1000). The common logarithm defines how many times we need to multiply by 10 to get the required output. The natural logarithm is called the logarithm of base e. The natural logarithm is represented by ln or loge. Here, "e" stands for Euler's constant which is approximately equal to 2.71828.
For example, the natural logarithm of 78 is written as ln 78. The natural logarithm determines how much we need to multiply "e" to get the required output.
We need to evaluate log₂ 2⁵Using the property logₐ (mⁿ) = n logₐ m log₂ 2⁵ can be written as
log₂ 2⁵ = 5 log₂ 2
We know that logₐ a = 15 log₂ 2= 5
Therefore, after evaluating the logarithm log₂ 2⁵, we get the result as 5.
Learn more about logarithms here:
brainly.com/question/25710806
#SPJ4
In an AR (p) scheme the PACF shows p spikes outside the confidence interval. True False
Answers
In an AR (p) scheme the PACF shows p spikes outside the confidence interval is True.
In an AR (p) (autoregressive) scheme, the Partial Autocorrelation Function (PACF) is a plot that shows the correlation between a time series and its lagged values, while controlling for the influence of intermediate lags. The PACF can help identify the order of the autoregressive model.
In an AR (p) scheme, the PACF will typically show p significant spikes outside the confidence interval, indicating the presence of p significant autocorrelations at lags 1, 2, ..., p. These spikes represent the direct effect of each lag on the current value of the time series, while controlling for the influence of other lags.
Therefore, if the PACF shows p spikes outside the confidence interval, it suggests an AR (p) scheme. Hence, the statement is true.
To know more about interval visit:
brainly.com/question/11051767
#SPJ11
Identify pairs of items (x, y) such that the support of{x, y}is at least 100. for allsuch pairs, compute the confidence scores of the corresponding association rules:
Answers
Several pairs of items (x, y) have a support of at least 100. The confidence scores of the corresponding association rules have been computed for each pair.
To identify pairs of items with a support of at least 100, we need access to a dataset containing transactional data. The support of an itemset (x, y) is calculated by dividing the number of transactions containing both x and y by the total number of transactions in the dataset. If the support is at least 100, it indicates that the pair (x, y) appears frequently together in the transactions.
Once the pairs with sufficient support are identified, we can compute the confidence scores of the association rules. Confidence is a measure of the strength of an association rule. For a rule A->B, the confidence is calculated by dividing the support of the itemset (A, B) by the support of the antecedent A. A high confidence score indicates a strong association between A and B.
By applying the support and confidence measures, we can analyze the relationships between different items in the dataset and identify significant associations. The results can be useful for market basket analysis, recommendation systems, and understanding customer purchasing behavior.
Learn more about association rules here:
https://brainly.com/question/18046467
#SPJ11
find f g, f − g, fg, and f/g and their domains. f(x) = x, g(x) = 9x
Answers
The domain of f g, f − g, fg, and f/g are all x ∈ ℝ.
Given f(x) = x and g(x) = 9x, we can find the following:
1. f + g = x + 9x = 10x
To find the sum of f and g, we add the two functions together, which gives us:
f + g = x + 9x
Simplifying this expression, we get:
f + g = 10x
Therefore, the sum of f and g is 10x, and the domain of this function is all real numbers.
2. f - g = x - 9x = -8x
To find the difference between f and g, we subtract g from f, which gives us:
f - g = x - 9x
Simplifying this expression, we get:
f - g = -8x
Therefore, the difference between f and g is -8x, and the domain of this function is all real numbers.
3. fg = x * 9x = 9x^2
To find the product of f and g, we multiply f and g together, which gives us:
fg = x * 9x
Simplifying this expression, we get:
fg = 9x²
Therefore, the product of f and g is 9x^2, and the domain of this function is all real numbers.
f/g = x/(9x) = 1/9
5. To find the quotient of f and g, we divide f by g, which gives us:
f/g = x/(9x)
Simplifying this expression, we get:
f/g = 1/9
Therefore, the quotient of f and g is 1/9, and the domain of this function is all real numbers except x = 0. This is because division by zero is undefined.
The domain of f g, f − g, fg, and f/g are all x ∈ ℝ.
To learn more about domain:
https://brainly.com/question/28135761#
#SPJ11
what is the surface area

Answers
The surface area of the figure would be 5 cm².
What is surface area?The surface area of a three-dimensional object is the total area of all its faces.
Given is a 2 - D figure as shown in the image.
We can write the surface area as -
{S} = A{cube} + 4 x A{triangle}
{S} = (1 x 1) + (4 x 1/2 x 1 x 2)
{S} = 1 + 4
{S} = 5 cm²
Therefore, the surface area of the figure would be 5 cm².
To solve more questions on surface area, visit the link below -
https://brainly.com/question/10839034
#SPJ1
Danielle pays a monthly charge of $69 for her cable bill. She also pays a fee every time she watches a movie on demand. Last month danielle watched 7 movies on demand, and her total monthly bill was $104. Select from the drop-down menu to correctly complete each statement. The monthly charge for danielle's cable bill is choose. . Danielle also pays choose. Every time she watches a movie on demand.
Answers
Danielle viewed 7 movies on demand, thus you must divide her 35 dollars among them. So the monthly charge for Danielle's cable bill is $5.
Danielle pays a monthly charge of $69 for her cable bill.
She also pays a fee every time she watches a movie on demand.
Last month Danielle watched 7 movies on demand, and her total monthly bill was $104.
We have to find the monthly charge for Danielle's cable bill to choose.
Remove the monthly fee of 69 dollars for cable service from the total of 104 dollars, then check the statement to see that there is still a mystifying 35 dollars on it.
Danielle viewed 7 movies on demand, thus you must divide her 35 dollars among them, giving you the result of $5 per on-demand movie.
To learn more about Simplification link is here brainly.com/question/19691064
#SPJ4
Store A sells a box of 8 pencils for $0.89. Store B sells a box of 12 pencils for $1.25. Which store sells the better deal? Tell the unit rate for each store (rounding to nearest cent)
Answers
Answer:
Should be store B :) The unit rate for store A (rounded) is 0.11 and the rounded unit rate for store B is 0.10
Step-by-step explanation:
Answer:
Store B has the better deal
Unit rate:
Store A = $0.11
Store B = $0.10
Step-by-step explanation:
Store A :
8pencils = $0.89
1 pencil = $0.89/8 = $0.111
Store B:
12pencils = $1.25
1 pencil = $1.25/12 = $0.104
Store B sells 1 pencil at $0.104 and store A at $0.111
Therefore Store B sells the better deal.
Doug estimates that his soccer team will win 7 games this year. The team actually wins 10 games. What is the percent error of Doug’s estimate? Round the percent to the nearest tenth if necessary.
Answers
Answer: 30%
Step-by-step explanation:
Percent error = \(\dfrac{|\text{Estimated value - Actual value}|}{\text{Actual value}}\times100\%\)
Estimated number of games win this year = 7
Actual number of games won = 10
Now , the percent error of Doug’s estimate = \(\dfrac{|7-10|}{10}\times100\%= \dfrac{3}{1}\times10\%=30\%\)
Hence, the percent error of Doug’s estimate = 30%
Answer:
30%
Step-by-step explanation:
you want to know the percentage of utility companies that earned revenue between 41 million and 99 million dollars. if the mean revenue was 70 million dollars and the data has a standard deviation of 18 million, find the percentage. assume that the distribution is normal. round your answer to the nearest hundredth.
Answers
Approximately 89.26% of utility companies have revenue between 41 million and 99 million dollars. We need to use the normal distribution formula and find the z-scores for the given values.
First, we need to find the z-score for the lower limit of the range (41 million dollars): z = (41 - 70) / 18 = -1.61
Next, we need to find the z-score for the upper limit of the range (99 million dollars): z = (99 - 70) / 18 = 1.61
We can now use a standard normal distribution table or a calculator to find the area under the curve between these two z-scores. The area between -1.61 and 1.61 is approximately 0.9044. This means that approximately 90.44% of utility companies earned revenue between 41 million and 99 million dollars.
To find the percentage of utility companies with revenue between 41 million and 99 million dollars, we can use the z-score formula and the standard normal distribution table. The z-score formula is: (X - mean) / standard deviation. First, we'll calculate the z-scores for both 41 million and 99 million dollars: Z1 = (41 million - 70 million) / 18 million = -29 / 18 ≈ -1.61
Z2 = (99 million - 70 million) / 18 million = 29 / 18 ≈ 1.61
Now, we'll look up the z-scores in the standard normal distribution table to find the corresponding percentage values.
For Z1 = -1.61, the table value is approximately 0.0537, or 5.37%.
For Z2 = 1.61, the table value is approximately 0.9463, or 94.63%.
Percentage = 94.63% - 5.37% = 89.26%
To know more about distribution formula visit :-
https://brainly.com/question/15776502
#SPJ11
what was the average wait time in a drive-thru in 2013?
Answers
Answer:
In 2003 there was only a short waiting time of 116 seconds!
That's less than TWO minutes.
However, over the years, the drive-thru wait time has gone up 20%
In 2021, due to a study/survey, the drive-thru wait time has been 3+ minutes on average.
Answer:
in 2013 the average time was 180.83
Step-by-step explanation:
solve each logarithmic equation. Round your answer to two decimal places.
Teach me this one? I want to work on the next and will submit it once I have it done.
7 log9 (x + 8) = 7
Answers
Answer:
\(\sf \boxed{\bold{x=1}}\)
Explanation:
\(\rightarrow \sf 7 log_9 (x + 8) = 7\)
divide both sides by 7
\(\rightarrow \sf \dfrac{7\log _9\left(x+8\right)}{7}=\dfrac{7}{7}\)
simplify the following
\(\sf \rightarrow \log _9\left(x+8\right)=1\)
apply log rules \(\underline{The \ rule}: \ \bold{log_{b} (a)= c} \ \ \Longrightarrow \sf a = b^c\)
\(\sf \rightarrow x+8 = 9^1\)
simplify
\(\sf \rightarrow x+8=9\)
subtract both sides by 8
\(\sf \rightarrow x=1\)
\(\\ \rm\Rrightarrow 7log_9(x+8)=7\)
\(\\ \rm\Rrightarrow log_9(x+8)=1\)
\(\\ \rm\Rrightarrow x+8=9^1\)
a^1=a\(\\ \rm\Rrightarrow x+8=9\)
\(\\ \rm\Rrightarrow x=9-8\)
\(\\ \rm\Rrightarrow x=1\)
brainliest+100 points


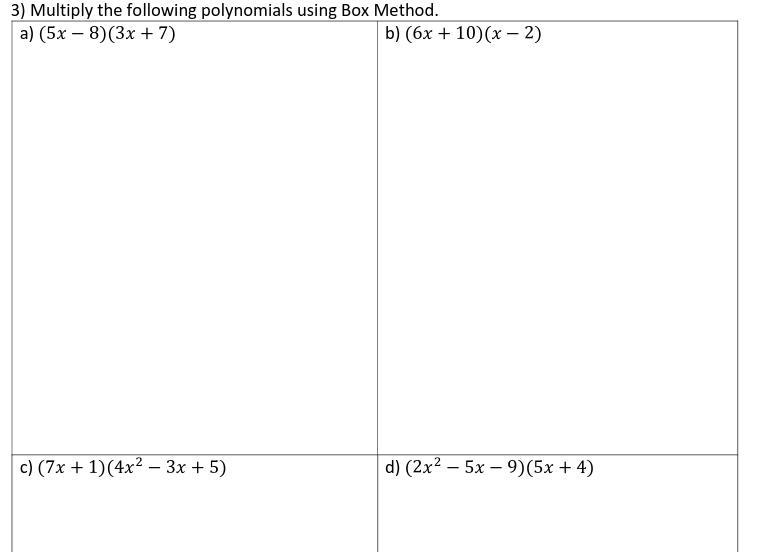
Answers
Answer:
Page 1
1)
a) - 5x^4+3
Degree: 4
Number of terms: 2
b) 5x² + 30x+25
Degree: 2
Number of Terms: 3
c) 16r^4p
Degree: 4
Number of Terms: 1
d) 9m²n + 12mn +4m -6n+19
Degree:2
Number of Terms:5
Note:
Degree: the highest exponent of the variable x)
Number of terms: It is either a single number or variable, or numbers and variables multiplied together. Terms are separated by + or - signs, or sometimes by divide
Page 2:
Add or subtract the following polynomials.
a) (3p^3+6p^2+14p)+(-5p^3-2p+8p^2
opening bracket
3p^3+6p^2+14p+(-5p^3-2p+8p^2)
3p^3+6p^2+14p-5p^3-2p+8p^2
Combining like terms
-2p^3 +14p^2+12p
b) (7y^3-5y)-(5y-7y^3)
Opening bracket
7y^3-5y-5y+7y^3
Combining like terms
14y^3-10y
c) (6z^4+15-7z^3)+(-2z^4+8z^3-5z^5)
Opening bracket
6z^4+15-7z^3-2z^4+8z^3-5z^5
-5z^5 +4z^4+1z^3+15
d) (-3n²-14n+1)-(-7n+2-6n²)
Opening bracket
-3n²-14n+1+7n-2+6n²
3n²-7n-1
e) (7b^3-14-8b^4) − (−3b^4+7b³ +4)
Opening bracket
7b^3-14-8b^4+3b^4-7b³-4
-5b^4-18
f) (-3n^2-4n+2n⁴) + (3n^2+ 19n-7n^4)
Opening bracket
-3n^2-4n+2n⁴+3n^2+ 19n-7n^4
-5n⁴+15n
Answer:
Page 1
1)
a) - 5x^4+3
Degree: 4
Number of terms: 2
b) 5x² + 30x+25
Degree: 2
Number of Terms: 3
c) 16r^4p
Degree: 4
Number of Terms: 1
d) 9m²n + 12mn +4m -6n+19
Degree:2
Number of Terms:5
Note:
Degree: the highest exponent of the variable x)
Number of terms: It is either a single number or variable, or numbers and variables multiplied together. Terms are separated by + or - signs, or sometimes by divide
Page 2:
Add or subtract the following polynomials.
a) (3p^3+6p^2+14p)+(-5p^3-2p+8p^2
opening bracket
3p^3+6p^2+14p+(-5p^3-2p+8p^2)
3p^3+6p^2+14p-5p^3-2p+8p^2
Combining like terms
-2p^3 +14p^2+12p
b) (7y^3-5y)-(5y-7y^3)
Opening bracket
7y^3-5y-5y+7y^3
Combining like terms
14y^3-10y
c) (6z^4+15-7z^3)+(-2z^4+8z^3-5z^5)
Opening bracket
6z^4+15-7z^3-2z^4+8z^3-5z^5
-5z^5 +4z^4+1z^3+15
d) (-3n²-14n+1)-(-7n+2-6n²)
Opening bracket
-3n²-14n+1+7n-2+6n²
3n²-7n-1
e) (7b^3-14-8b^4) − (−3b^4+7b³ +4)
Opening bracket
7b^3-14-8b^4+3b^4-7b³-4
-5b^4-18
f) (-3n^2-4n+2n⁴) + (3n^2+ 19n-7n^4)
Opening bracket
-3n^2-4n+2n⁴+3n^2+ 19n-7n^4
-5n⁴+15n
Step-by-step explanation:
Lena knit a total of 20 centimeters of scarfs over night. How many nights will Lena have to spend knitting in order to knit a total of 50 cm of scarfs. Assume the relationship is directly proportional.
Answers
Answer:
50cm of scarfs is equal to 2.5 nights of knitting.
Step-by-step explanation:
20cm= 1 night
10cm= 1/2 or 0.5 a night
40cm= 2 nights
50cm=2.5 nights