Kim is watching a fireworks display from an observation spot 5 miles away. Find the angle of elevation from Kim to the fireworks, which are at a height of 0.5 miles.
Answers
The angle of elevation from Kim to the fireworks is approximately 5.71 degrees.
To find the angle of elevation from Kim to the fireworks, we can use trigonometry. Let's consider a right triangle formed by Kim, the fireworks, and the ground.
In the triangle, the horizontal distance between Kim and the fireworks is 5 miles, and the vertical distance (height) from the ground to the fireworks is 0.5 miles. We can use the tangent function to find the angle of elevation.
The tangent of an angle is defined as the ratio of the opposite side to the adjacent side. In this case, the opposite side is the height (0.5 miles) and the adjacent side is the horizontal distance (5 miles). So, we have:
tan(angle) = opposite/adjacent
tan(angle) = 0.5/5
To find the angle, we can take the inverse tangent (arctan) of both sides:
angle = arctan(0.5/5)
Using a calculator or trigonometric tables, we find:
angle ≈ 5.710593137 degrees
Therefore, the angle of elevation from Kim to the fireworks is approximately 5.71 degrees.
For such more questions on Elevation Angle
https://brainly.com/question/27243378
#SPJ11
Related Questions
/_A and /_B are complementary angles.
Given that m /_A = 23 degrees, find m /_B
Answers
Answer:
67
Step-by-step explanation:
When two angles are complimentary, it means that, together, they make a 90 degree angle.
/_A + /_B must equal 90°
1.Think about what you know about reach fill in each Box use words numbers and pictures show as many ideas as you can2. What to rates can you write for the ratios showing by the double number lines what do tell you

Answers
A rate is a constant value that relates two proportional variables, like miles and gallons, pounds and days, etc.
In the case of units rates, the second variable has a value of one unit.
Some examples are:
• 100 cars pass by in 2 hours. The unit rate is 100/2=50 cars per hour.
• You can paint 3 boards in half an hour. The unit rate is 3/0.5=6 boards per hour.
• 200 sausages were eaten by 50 people. The unit rate is 200/50=4 sausages per person.
For any 2 variables, we can write 2 ratios, being one the inverse of the other.
For example, for the graph of miles and gallons, we can see that 1 gallon corresponds to 30 miles.
We then can write a ratio as:
\(k_1=\frac{30\text{ miles}}{1\text{ gallon}}=30\text{ miles per gallon}\)This is a unit rate, as the second variable (gallons) have a value of 1 unit.
We can also write a second ratio as:
\(k_2=\frac{1\text{ gallon}}{30\text{ miles}}=\frac{1}{30}\text{gallons per mile}\approx0.033\text{ gallons per mile}=\frac{1}{k_1}\)This second ratio is the inverse of the first one.
T/F: if the range of feasibility indicates that the original amount of a resource, which was 20, can increase by 5, then the amount of the resource can increase to 25.
Answers
True. The statement "if the range of feasibility indicates that the original amount of a resource, which was 20, can increase by 5, then the amount of the resource can increase to 25" is true.
When a range of feasibility is given, the lower and upper bounds of the values that can be chosen for the variables in a linear programming problem are given. The range of feasibility reflects the range within which the optimum answer can be found. It is a parameter that measures the extent to which the variables can change and still allow the same optimal answer to be obtained. In this case, the range of feasibility suggests that the initial amount of a resource was 20 and could be increased by 5, implying that the total amount of the resource can be 25. Therefore, statement is true.
To know more about range: https://brainly.com/question/24326172
#SPJ11
DUE IN AN HOUR, WILL GIVE BRAINLIEST! need both of them done, please show work and give answers. thank you!!

Answers
Answer (9): I can’t see the full picture
Does the plan of future transfer plan affect the players performance in points?
a)yes, players with future transfer plan have largee variance in the points
b) Yes, players with future transfer plans have higher median points.
c) no
Answers
Option a, Yes players with future transfer plans do experience significant points variance if those plans have an impact on their point performance.
There are two probable conclusions: (a) players with a future transfer plan do indeed have a greater point variance, and (b) players with a future transfer plan do indeed have a higher point median.
The presentation of players with and without move expectations ought to be analyzed, jumbling variables ought to be considered, and factual tests ought to be rushed to survey the legitimacy of these speculations.
The outcome of this research would ultimately establish whether or not the possibility of a future transfer plan had an impact on a player's point production.
Learn more about variance at
https://brainly.com/question/13708253
#SPJ4
What is the nth term rule of the quadratic sequence below?
4
,
6
,
10
,
16
,
24
,
34
,
46
,
.
.
.
Answers
,
76
lmk if you need anything else
Answer:
4+(n-1)2
Step-by-step explanation:
Because its an arithmatic series for which the formula is
n-term=first term+(n-1)d.
where "d" is the common difference.
Mr. Quesada took out a loan for $12,000. To pay it back, he will make 24 monthly payments of $629. How much will he pay in interest?
Answers
Answer:
$3,096
Step-by-step explanation:
To find the total interest Mr. Quesada will pay, we need to first calculate the total amount he will pay back, and then subtract the original amount borrowed.
The total amount Mr. Quesada will pay back over 24 months is:
$629 x 24 = $15,096
Subtracting the original loan amount, we get:
$15,096 - $12,000 = $3,096
So Mr. Quesada will pay a total of $3,096 in interest over the course of the loan.
for each step, choose the reason that best justifies it. (NEED HELP QUICK)

Answers
The reason for each step to justify it is:
Division Property of Equality: This step involves dividing both sides of the equation by 4 to isolate the variable term on one side of the equation.
The step involved here is: (w+25)/4
Multiplication Property of Equality: This step involves multiplying both sides of the equation by 4 to simplify the equation and cancel out the denominator.
The step involved here is: 4*(w+25)
Addition Property of Equality: This step involves subtracting 25 from both sides of the equation to isolate the variable term on one side of the equation.
The step involved here is: w+25
Simplifying: This step involves simplifying the expression by combining like terms and performing arithmetic operations to simplify the equation.
The step involved here is: w+25-25=12-25
Subtraction Property of Equality: This step involves subtracting 25 from both sides of the equation to isolate the variable term and solve for the variable.
The step involved here is: w=-13
What is meant by division?
Division is a mathematical operation that involves splitting a quantity into equal parts or groups. It is represented by the symbol ÷ or / and is the inverse operation of multiplication. Division can be used to solve problems related to sharing, fractions, and ratios.
What is meant by multiplication?
Multiplication is a mathematical operation that involves adding a number to itself a certain number of times. It is represented by the symbol × or * and is the inverse operation of division. Multiplication can be used to solve problems related to scaling, area, volume, and rates.
To know more about division visit
brainly.com/question/21416852
#SPJ1
The value of x is ____ degrees, and the value of y is___degrees
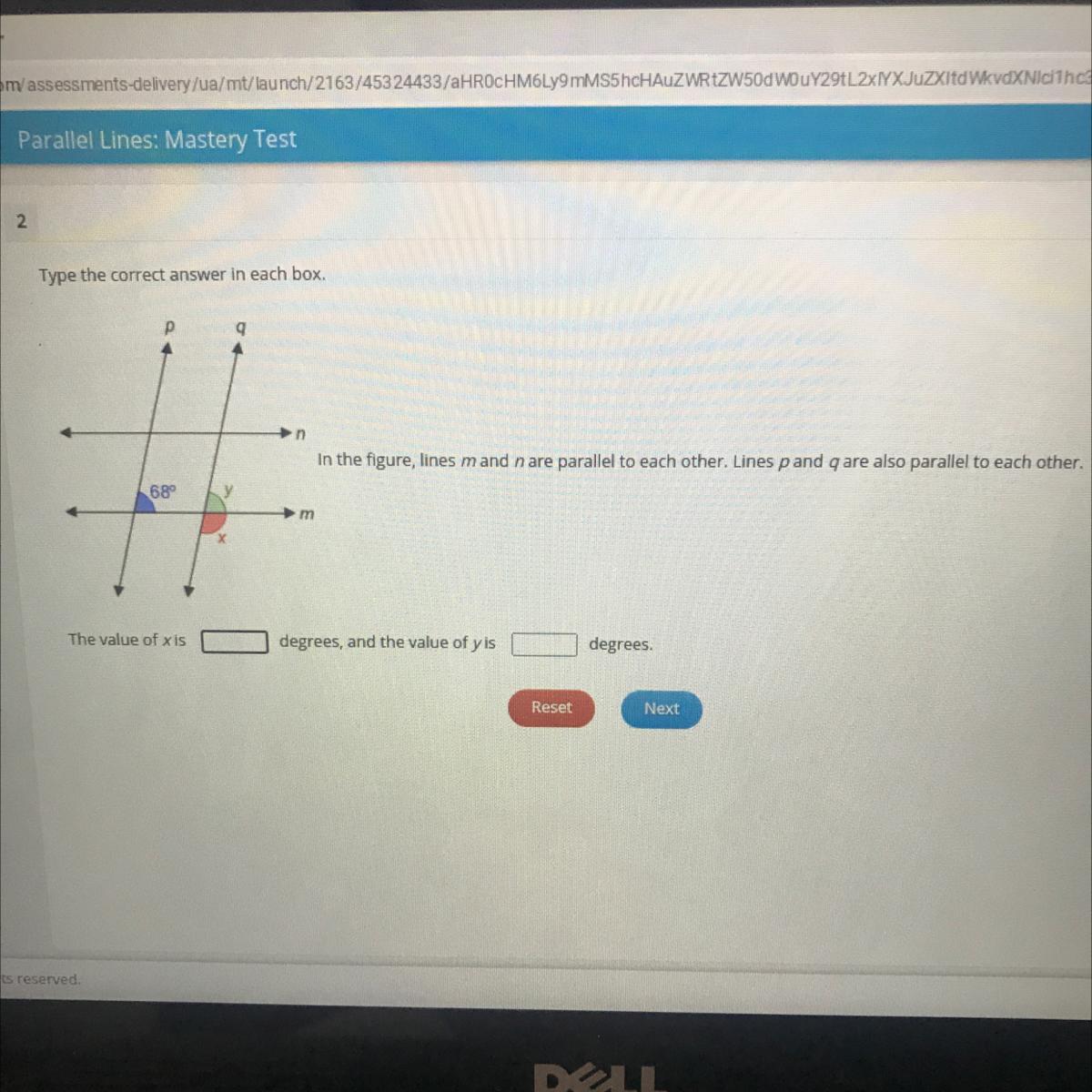
Answers
Answer:
x = 112°, y = 68°
Step-by-step explanation:
68° and y are corresponding angles and are congruent, then
y = 68°
x and y are adjacent angles and are corresponding ( sum to 180° ), then
x + y = 180°
x + 68° = 180° ( subtract 68° from both sides )
x = 112°
The way we can figure this out is by deciding which variable to find first. Since we know that lines p and q are parallel, we know that they intersect line m in the same manner. (They are kinda like the same line, just shifted along line m). Since the 68 degrees and y are at the same relative point on lines p and q along m, we know y = 68.
Now we can easily find x. Since a line is basically just a 180 degree angle no matter how you look at it, we know that 68 + x = 180, as these two angles together become a straight line. Thus, solve the equation and get x = 112 degrees.
Ceiling Height: Suppose the ceiling of a home is 3.06 meters above the floor. Express the height of the ceiling in centimeters.The ceiling is ? centimeters tall.
Answers
One meter is equal to 100 centimeters.
Now, we need to know 3.06 meters in centimeters:
Use the rule of three to find this value
1meter-------------------- 100cm
3.06------------------------- x cm
Where x is = (3.06*100)/1
Then x=306
The ceiling is 306 centimeters tall.
Scenario 2 Magnifi Co. produces a high-end amplifier for musical aficionados. Historically, only 85% of the 200 amplifiers produced per month on average have met the company's demanding standards for
Answers
Scenario 2 Magnifi Co. produces a high-end amplifier for musical aficionados. Historically, only 85% of the 200 amplifiers produced per month on average have met the company's demanding standards for quality control. Suppose a random sample of 50 amplifiers is taken from a month's production..
What is the probability that less than 40 of the amplifiers will meet the company's quality standards? b) What is the probability that between 40 and 45 inclusive of the amplifiers will meet the company's quality standards? c) What is the probability that more than 45 of the amplifiers will meet the company's quality standards? a) In order to solve for the probability that less than 40 amplifiers will meet the company's quality standards, we can use the binomial distribution formula: P(X < 40) = Σi=0^39 C(50, i) (0.85)i(1-0.85)50-i
This can be solved using a computer, calculator, or by using a binomial probability table. Using a binomial table, we can find that P(X < 40) = 0.024. Therefore, there is a 0.024 probability that less than 40 amplifiers will meet the company's quality standards. b) To solve for the probability that between 40 and 45 amplifiers inclusive will meet the company's quality standards, we can use the binomial distribution formula again. We need to solve for P(40 ≤ X ≤ 45): P(40 ≤ X ≤ 45) = Σi=40^45 C(50, i) (0.85)i(1-0.85)50-i This can also be solved using a computer, calculator, or binomial table. Using a binomial table, we can find that P(40 ≤ X ≤ 45) = 0.435. Therefore, there is a 0.435 probability that between 40 and 45 amplifiers inclusive will meet the company's quality standards. c) To solve for the probability that more than 45 amplifiers will meet the company's quality standards, we can use the binomial distribution formula one more time. We need to solve for P(X > 45): P(X > 45) = Σi=46^50 C(50, i) (0.85)i(1-0.85)50-i Once again, this can be solved using a computer, calculator, or binomial table. Using a binomial table, we can find that P(X > 45) = 0.056. Therefore, there is a 0.056 probability that more than 45 amplifiers will meet the company's quality standards.Overall, it can be concluded that the probability that less than 40 amplifiers will meet the company's quality standards is low, the probability that between 40 and 45 amplifiers inclusive will meet the company's quality standards is relatively high, and the probability that more than 45 amplifiers will meet the company's quality standards is relatively low.
To know more about amplifier visit:
https://brainly.com/question/32812082
#SPJ11
Julio spent 4.2 hours playing video games last week. What mixed number represents the amount of time Julio spent playing video games?
Answers
Answer:
4 1/5
Step-by-step explanation:
keep 4
0.2 can be written 2/10
2/10 is the same as 1/5
So 4 1/5
write 3/2 4/5 8/5 in decimal notation
Answers
Answer:
hope it will help you Mark me as a brilliant

TRUE/FALSE. descriptive statistics uses the data to make inferences and predictions about a population based on a sample of data taken from the population in question.
Answers
The given statement "descriptive statistics uses the data to make inferences and predictions about a population based on a sample of data taken from the population in question" is FALSE.
How is this false?
Descriptive statistics is a branch of statistics that studies and summarizes a set of data's main features. It aids in the interpretation of data and drawing conclusions about the population based on sample data. Descriptive statistics are used to provide a quick summary of the data set's key characteristics.
An inference is a statistical method of estimating the characteristics of a population based on a sample's data. It is a method of predicting data in a population based on the observations made in a sample. The primary goal of inferential statistics is to make predictions about a population based on data from a sample of that population.
Predictions are projections or guesses about what might occur in the future. When used in statistics, prediction refers to the use of current data to estimate what might occur later. A statistical model is usually used to make a prediction.
A population is the entire collection of items or individuals about which you want to learn in statistics. A population is made up of all of the objects or people who possess the qualities that the researcher is interested in researching.
A sample is a subset of a population that is used to collect data and conduct statistical analyses. The sample size is typically less than the population size, and data collected from a sample is used to make inferences about the population as a whole.
Learn more about Inferential Statistics.
brainly.com/question/30761414
#SPJ11
Solve algebraically for x:
3600 + 1.02x < 2000 + 1.04x
Answers
Answer:
\(x < 80000\)
Step-by-step explanation:
\(3600 + 1.02x < 2000 + 1.04x \\ \frac{ \: \: \: \: \: \: \: \: \: \: \: \: - 1.04x < \: \: \: \: \: \: \: \: \: \: \: \: \: - 1.04x}{3600 - 0.02x < 2000} \\ \\ 3600 - 0.02x < 2000 \\ \frac{ - 3600 \: \: \: \: \: \: \: \: \: < - 3600}{ - 0.02x < - 1600} \\ \\ \frac{ - 0.02x}{ - 0.02} < \frac{ - 1600}{ - 0.02} \\ \\ x < 80000\)
What is the average of the
data set displayed on the dol
plot?
Mean =

Answers
Answer:
Mean=According to dot plot
=2+3+5+4+1
Step 2:Arrange in ascending order
=1+2+3+4+5
=15/5 :I divided it over how many they are
=3
\(\huge\text{Hey there!}\)
\(\large\text{The mean of a particular data plot is known as your average. To find}\\\large\text{the mean/average you have to ADD of the numbers \& DIVIDE them}\\\large\text{by the total numbers it has in the plot.}\)
\(\text{Here's the formula: }\rm{\dfrac{Sum\ of\ all\ your\ numbers\ in\ the\ plot}{Total\ number\ in\ the\ data\ plot}= your\ average/mean\)
\(\huge\text{LET'S SOLVE FOR THE QUESTION}\)
\(\large\text{The equation: }\bf{\dfrac{80 + 81 + 82 + 83 + 84 + 85 + 86}{7} = mean/average}\\\\\bf{= \dfrac{161 + 82 + 83 + 84 + 85 + 86}{7}}\\\\\bf{= \dfrac{243 + 83 + 84 + 85 + 86}{7}}\\\\\bf{= \dfrac{326 + 84 + 85 + 86}{7}}\\\\\bf{= \dfrac{410 + 85 + 86}{7}}\\\\\bf{= \dfrac{495 + 86}{7}}\\\\\bf{= \dfrac{581}{7}}\\\\\bf{= 581\div7}\\\\\bf{= 83}\)
\(\huge\textbf{Therefore, your answer is: \boxed{\mathsf{83}}}\huge\checkmark\)
\(\huge\text{Good luck on your assignment \& enjoy your day!}\)
~\(\frak{Amphitrite1040:)}\)
the total cost of an nintendo switch is $374.50 and it cost $350 before tax find the percent of sales tax
Answers
Answer:
7%
Step-by-step explanation:
\(\frac{374.50}{350}=\frac{x}{100}\\x = \frac{37450}{350} = 107\\107-100 = 7\)
An optical inspection system is used to distinguish among different part types. The probability of correct classification of any part is 0. 98. Suppose that three parts are inspected and that the classifications are independent. Let the random variable x denote the number of parts that are correctly classified. Determine the probability mass function and cumulative mass function of x.
Answers
The probability mass function (PMF) for x is {0.0004, 0.0588, 0.3432, 0.941192}, and the cumulative mass function (CMF) for x is {0.0004, 0.0592, 0.4024, 1.0}.
The probability mass function (PMF) and cumulative mass function (CMF) for the random variable x, which denotes the number of parts correctly classified in an optical inspection system, can be determined.
Since the classifications of the parts are independent, we can use the binomial probability distribution to model this scenario. The PMF gives the probability of obtaining a specific value of x, and the CMF gives the probability of obtaining a value less than or equal to x.
The PMF of x is given by the binomial probability formula:
P(x) = (n C x) * p^x * (1 - p)^(n - x)
where n is the number of trials (number of parts inspected), x is the number of successes (number of parts correctly classified), and p is the probability of success (probability of correct classification of any part).
In this case, n = 3 (three parts inspected) and p = 0.98 (probability of correct classification).
Let's calculate the PMF for x:
P(x = 0) = (3 C 0) * (0.98^0) * (1 - 0.98)^(3 - 0) = 0.0004
P(x = 1) = (3 C 1) * (0.98^1) * (1 - 0.98)^(3 - 1) = 0.0588
P(x = 2) = (3 C 2) * (0.98^2) * (1 - 0.98)^(3 - 2) = 0.3432
P(x = 3) = (3 C 3) * (0.98^3) * (1 - 0.98)^(3 - 3) = 0.941192
The PMF for x is:
P(x = 0) = 0.0004
P(x = 1) = 0.0588
P(x = 2) = 0.3432
P(x = 3) = 0.941192
To calculate the CMF, we sum up the probabilities up to x:
F(x) = P(X ≤ x) = P(x = 0) + P(x = 1) + ... + P(x = x)
Using the calculated probabilities, the CMF for x is:
F(x = 0) = 0.0004
F(x = 1) = 0.0592
F(x = 2) = 0.4024
F(x = 3) = 1.0
Therefore, the probability mass function (PMF) for x is {0.0004, 0.0588, 0.3432, 0.941192}, and the cumulative mass function (CMF) for x is {0.0004, 0.0592, 0.4024, 1.0}.
Learn more about probability here
https://brainly.com/question/25839839
#SPJ11
the gram-schmidt process produces from a linearly independent set {x1, x2, . . . , xp} an orthogonal set {v1, v2, . . . , vp} with the property that span{v1, . . . , vk}
Answers
The statement is true.
An orthogonal set with the same dimension as the initial collection of vectors is created by the Gram-Schmidt process.
Given that,
From a linearly independent collection of {x₁, x₂,..., xp}, the gram-Schmidt process creates an orthogonal set of {v₁, v₂,..., vp} with the feature that for each k, the vectors v₁...vk span the same subspace as that spanned by x₁...xk.
Whether the claim is true or false must be determined.
The statement is true.
An orthogonal set with the same dimension as the initial collection of vectors is created by the Gram-Schmidt process. An orthogonal set is further linearly independent. The orthogonal set produced by the Gram-Schmidt process and the original set will cover the same subspace if their dimensions are the same.
To learn more about orthogonal visit: https://brainly.com/question/2292926
#SPJ4
ASA, SSS, SAS
Define each postulate and give a well written and visual example of each term.
Include as much detail as possible
Answers
Answer:
In geometry, postulates are statements that are accepted as true without proof. The three postulates for congruent triangles are ASA, SSS, and SAS. These postulates are used to prove that two triangles are congruent.
ASA Postulate:
ASA stands for "Angle, Side, Angle." This postulate states that if two angles and the included side of one triangle are congruent to two angles and the included side of another triangle, then the two triangles are congruent.
Visual example:
In the above image, ΔABC and ΔDEF have ∠A ≅ ∠D, ∠B ≅ ∠E, and AB ≅ DE. Therefore, we can conclude that ΔABC ≅ ΔDEF by ASA postulate.
SSS Postulate:
SSS stands for "Side, Side, Side." This postulate states that if the three sides of one triangle are congruent to the three sides of another triangle, then the two triangles are congruent.
Visual example:
In the above image, ΔABC and ΔDEF have AB ≅ DE, BC ≅ EF, and AC ≅ DF. Therefore, we can conclude that ΔABC ≅ ΔDEF by SSS postulate.
SAS Postulate:
SAS stands for "Side, Angle, Side." This postulate states that if two sides and the included angle of one triangle are congruent to two sides and the included angle of another triangle, then the two triangles are congruent.
Visual example:
In the above image, ΔABC and ΔDEF have AB ≅ DE, BC ≅ EF, and ∠B ≅ ∠E. Therefore, we can conclude that ΔABC ≅ ΔDEF by SAS postulate.
Overall, the ASA, SSS, and SAS postulates are important tools in proving the congruence of triangles in geometry. They allow us to make logical deductions about the properties of triangles based on their corresponding angles and sides.
Answer:
They are different because ASA means that the two triangles have two angles and the side between the angles congruent. SAS means that two sides and the angle in between them are congruent
Step-by-step explanation:
and sss If all the three sides of one triangle are equivalent to the corresponding three sides of the second triangle, then the two triangles are said to be congruent by SSS rule.
a ______ is a way to organize qualitative data into categories and record the number of observations in each category.
Answers
Frequency distribution is a way to organize qualitative data into categories and record the number of observations in each category.
Differentiate between frequency distribution and relative frequency ?
A frequency distribution lists how frequently each category of data occurs, but a relative frequency analysis lists how frequently each types of information occurs.
One approach to organise data is to use a "frequency distribution," which can be done by listing the data, placing it in a table, or displaying it in a graph. Then, the list's entries (distinct values) are counted in terms of how frequently they have occurred.
Define relative frequency distribution
A "relative frequency distribution," on the other hand, refers to the percentage of the total number of observations that fall into a certain group. Divide each frequency by the total amount of data in the sample to obtain this.
what is qualitative data ?
Quantitative data are counts or measures, whereas qualitative data describe categories. Examples of qualitative data include eye colours and shoe brand names in a consumer survey. Examples of quantitative data are student heights and test results.
To know more about qualitative data visit :
https://brainly.com/question/14280756
#SPJ4
Please Answer This, the question is on the picture. it needs to be a fraction
will mark brainllest if its right, no links!
(for hamster dude)

Answers
Answer:
x = 27.2 or 27 1/5
Step-by-step explanation:
cos 54° = 16/x
x = 27.2 or 27 1/5
1. Which indicates the dilation of a figure in the coordinate plane?
A. (x,y) —> (kx,ky)
B. (x,y) —> (-y,x)
C. (x,y) —> (-x,-y)
D. (x,y) —> (x+h,y+v)
Answers
Answer:
A. \((x,y)\) ⇒ \((kx, ky)\)
Step-by-step explanation:
Because that's the dilation equation or formula
Define a relation J on all integers: For all x, y e all positive integers, xJy if x is a factor of y (in other words, x divides y). a. Is 1 J 2? b. Is 2 J 1? c. Is 3 J 6? d. Is 17 J 51? e. Find another x and y in relation J.
Answers
Here is the summary of the relation J on all integers:
a. 1 J 2 : No
b. 2 J 1 : Yes
c. 3 J 6 : Yes
d. 17 J 51 : No
e. Another example of x and y in relation J: 4 J 12 (4 is related to 12 under relation J)
What is the relation J defined on all positive integers, and determine whether the integers are related under J?To define a relation J on all positive integers is following:
a. No, 1 is not a factor of 2, so 1 does not divide 2.
Therefore, 1 is not related to 2 under relation J.
b. Yes, 2 is a factor of 1 (specifically, 2 divides 1 zero times with a remainder of 1), so 2 divides 1.
Therefore, 2 is related to 1 under relation J.
c. Yes, 3 is a factor of 6 (specifically, 3 divides 6 two times with a remainder of 0), so 3 divides 6.
Therefore, 3 is related to 6 under relation J.
d. No, 17 is not a factor of 51, so 17 does not divide 51.
Therefore, 17 is not related to 51 under relation J.
e. Let's choose x = 4 and y = 12.
Then we need to check if x divides y. We can see that 4 is a factor of 12 (specifically, 4 divides 12 three times with a remainder of 0), so 4 divides 12.
Therefore, 4 is related to 12 under relation J.
To summarize:
1 is not related to 2 under relation J2 is related to 1 under relation J3 is related to 6 under relation J17 is not related to 51 under relation J4 is related to 12 under relation JLearn more about positive integers
brainly.com/question/26051073
#SPJ11
What is the value of p in this proportion?
3 10/p=4 5/1 4
Enter your answer as a simplified fraction in the box. mhanifa please answer thhis
p =
Answers
Answer:
below
Step-by-step explanation:
that is the correct answer above

Answer:
2/3
Step-by-step explanation:
I understand what you were trying to ask, cuz I am taking the test rn :)

The sum of a number $x$ and 4 equals 12.
An equation that represents this sentence is
.
Answers
Answer:
(3 x 1) x 4 = 12
The useful life of an electrical component is exponentially distributed with a mean of 1000 hours a. What is the probability the circuit will last more than 2000 hours?
Answers
Answer:
0.865
Step-by-step explanation:
To solve for the probability we would be using the formula:
F(x) = 1 - e^−λx
Therefore, P(x > 2000) = F(x) = 1 - e^−λx
Mean = 1000 hours
λ = 1/mean = 1/1000 hours
x= 2000 hours
F(x) = 1 - e^−(1/1000)2000
F(x) = 1 - e^−2
= 0.8646647168
Therefore, the probability the the circuit will last at least 2000 hours = 0.865
Select "equivalent" or "not equivalent" for each pair of expressions.
Expressions
equivalent or not equivalent?
5x - 7+ 3x and 3x - 7+ 5x equivalent not equivalent
4y+9+ 3y and 3y+9+ 4y equivalent not equivalent
6z - 2z + 4 and 4 + 22 - 6z equivalent not equivalent

Answers
Answer:
1 and 2 are equivalent and 3 is not equivalent because rhe numbers are are just swapped you have to pay attention to the signs.
Answer:
1 and 2 are equivalent and 3 is not equivalent
Step-by-step explanation:
What is the effect on the graph of f(x) = x when it is transformed to
h(x) = 3x2 - 7?
A. The graph of f(x) is vertically stretched by a factor of 3 and shifted
7 units down.
B. The graph of f(x) is horizontally compressed by a factor of 3 and
shifted 7 units to the right.
C. The graph of f(x) is horizontally stretched by a factor of 3 and
shifted 7 units down.
D. The graph of f(x) is vertically stretched by a factor of 3 and shifted
7 units to the right
Answers
As f(x) = x changes to h(x) = 3x² - 7, the graph of f(x) is vertically stretched by a factor of 3 and shifted 7 units down.
What is transformation of graph?Graph transformation is the process by which an existing graph, or graphed equation, is modified to produce a variation of the proceeding graph.
Given is a graph of f(x) = x which is transformed into h(x) = 3x² - 7.
The graph of a the equation -
f(x) = x
is a straight line. When it is squared and multiplied by 3, we get -
h(x) = 3x²
which is a parabola stretched by a factor of 3 in vertical direction along
+ y axis.
When 7 is subtracted, it will shift the graph down by 7 units.
h(x) = 3x² - 7
Therefore, as f(x) = x changes to h(x) = 3x² - 7, the graph of f(x) is vertically stretched by a factor of 3 and shifted 7 units down.
To solve more questions on Graph transformation, visit the link below-
https://brainly.com/question/2542251
#SPJ5

determinant of matrix in python giving wrong answers true or false
Answers
The statement "determinant of matrix in Python giving wrong answers" is generally false, as long as you're using the correct method for calculation and providing a valid input matrix. It
What's determinant of a matrixThe determinant of a matrix is a scalar value that can be used to determine if a matrix is invertible or not.
In Python, the NumPy library provides a function to calculate the determinant of a matrix. However, if the input matrix is not a square matrix, the function will return an error.
Additionally, if the matrix is singular, the determinant will be zero, but due to the limitations of floating-point arithmetic, the function may return a very small non-zero value instead.
This can lead to the function giving wrong answers, either indicating that a matrix is invertible when it is not, or vice versa. It is important to check the validity of the matrix before calculating its determinant, and to be aware of the limitations of floating-point arithmetic.
One possible solution is to use symbolic computation libraries like SymPy to calculate the exact determinant of a matrix.
Learn more about PyThon at
https://brainly.com/question/30427047
#SPJ11