
Answers
Answer:
b
Step-by-step explanation:
330 divided by 30 equals 11
Related Questions
Consider the solutions of the following equation over the interval 0 to 2π, or the interval 0° to 360°. Of the choices shown, which is not a solution to the equation? 3 cot² 0-1=0 O All of the cho
Answers
Answer:
Step-by-step explanation:
We can simplify the given equation as follows:
3 cot² θ - 1 = 0
3 cot² θ = 1
cot² θ = 1/3
Taking the square root of both sides, we get:
cot θ = ±1/√3
Using the definition of cotangent, we know that:
cot θ = cos θ / sin θ
So we can rewrite the above equation as:
cos θ / sin θ = ±1/√3
Multiplying both sides by √3 and simplifying, we get:
cos θ = ±sin θ / √3
Squaring both sides and using the identity sin² θ + cos² θ = 1, we get:
1/3 = sin² θ + (sin θ / √3)²
Multiplying both sides by 3, we get:
1 = 3 sin² θ + sin² θ
4 sin² θ = 1
sin θ = ±1/2
Therefore, the possible solutions for θ are:
θ = 30°, 150°, 210°, 330°
Now we can check the given choices to see which one is not a solution to the equation:
- 45°: not a solution, since sin 45° = √2/2 ≠ ±1/2
- 150°: a solution, since sin 150° = -1/2 and cos 150° = -√3/2
- 210°: a solution, since sin 210° = -1/2 and cos 210° = √3/2
- 330°: a solution, since sin 330° = 1/2 and cos 330° = -√3/2
Therefore, the choice that is not a solution to the equation is -45°.
Paco goes to the store and buys a carton of eggs. The carton has 4 rows of eggs. There are 6 eggs in each row. Then he buys 8 bagels. How many eggs and bagels does Paco have altogether? Its a? I got from school and I need help.
Answers
Answer:
32
Step-by-step explanation:
If there are 6 eggs in a row and there are 4 rows, the total number of eggs = 6 x 4 = 24 eggs
The sum of eggs and bagels = 24 + 8 = 32
Solve for w
−4 (w + 1) = −24
w =
Answers
-4w - 4 = -24
+4 +4
-4w = -20
-4w/-4 = -20/-4
w = 5
Answer:
The answer is w = 5.
Step-by-step explanation:
1) Divide both sides by -4.
\(w + 1 = \frac{ - 24}{ - 4} \)
2) Two negative numbers makes a positive.
\(w + 1 = \frac{24}{4} \)
3) Simplify 24/4 to 6.
\(w + 1 = 6\)
4) Subtract 1 from both sides.
\(w = 6 - 1\)
5) Simplify 6 - 1 to 5.
\(w = 5\)
Therefor, the answer is w = 5.
if 11 is subratecet from 4 times a number the result is 89 find the number
Answers
Answer:
25
Step-by-step explanation:
Answer:
25
Step-by-step explanation:
4x-11=89
4x=89+11
4x=100
x= 25
I hope this will help
In 2020, a total of 9559 Nissan Leafs were sold in the US. For the 12-month period starting January 2020 and ending December 2020, the detailed sales numbers are as follows: 651, 808, 514, 174, 435, 426, 687, 582, 662, 1551, 1295 and 1774 units.
before the Nissan plant in Smyrna, Tennessee, started to produce the Nissan Leaf they were imported from Japan. Although cars are now assembled in the US, some components still imported from Japan. Assume that the lead time from Japan is one weeks for shipping. Recall that the critical electrode material is imported from Japan. Each battery pack consists of 48 modules and each module contains four cells, for a total of 192 cells. Assume that each "unit" (= the amount required for an individual cell in the battery pack) has a value of $3 and an associated carrying cost of 30%. Moreover, assume that Nissan is responsible for holding the inventory since the units are shipped from Japan. We suppose that placing an order costs $500. Assume that Nissan wants to provide a 99.9% service level for its assembly plant because any missing components will force the assembly lines to come to a halt. Use the 2020 demand observations to estimate the annual demand distribution assuming demand for Nissan Leafs is normally distributed. For simplicity, assume there are 360 days per year, 30 days per month, and 7 days per week.
(a) What is the optimal order quantity?
(b) What is the approximate time between orders?
Answers
(a)The optimal order quantity is 4609 units.
(b)The time between orders is 1.98 months.
To determine the optimal order quantity and the approximate time between orders, the Economic Order Quantity (EOQ) model. The EOQ model minimizes the total cost of inventory by balancing ordering costs and carrying costs.
Optimal Order Quantity:
The formula for the EOQ is given by:
EOQ = √[(2DS) / H]
Where:
D = Annual demand
S = Cost per order
H = Holding cost per unit per year
calculate the annual demand (D) using the 2020
sales numbers provided:
D = 651 + 808 + 514 + 174 + 435 + 426 + 687 + 582 + 662 + 1551 + 1295 + 1774
= 9559 units
To calculate the cost per order (S) and the holding cost per unit per year (H).
The cost per order (S) is given as $500.
The holding cost per unit per year (H) calculated as follows:
H = Carrying cost percentage × Unit value
= 0.30 × $3
= $0.90
substitute these values into the EOQ formula:
EOQ = √[(2 × 9559 × $500) / $0.90]
= √[19118000 / $0.90]
≈ √21242222.22
≈ 4608.71
Approximate Time Between Orders:
To calculate the approximate time between orders, we'll divide the total number of working days in a year by the number of orders per year.
Assuming 360 days in a year and a lead time of 1 week (7 days) for shipping, we have:
Working days in a year = 360 - 7 = 353 days
Approximate time between orders = Working days in a year / Number of orders per year
= 353 / (9559 / 4609)
= 0.165 years
Converting this time to months:
Approximate time between orders (months) = 0.165 × 12
= 1.98 months
To know more about quantity here
https://brainly.com/question/14581760
#SPJ4
What alternative term can be used to describe asymmetric cryptographic algorithms?
a. user key cryptography
b. public key cryptography
c. private key cryptography
d. cipher-text cryptography
Answers
The alternative term that can be used to describe asymmetric cryptographic algorithms is "public key cryptography," option b.
Asymmetric cryptography is a cryptographic approach that utilizes a pair of distinct keys, namely a public key and a private key.
The public key is openly shared, allowing anyone to encrypt messages intended for the owner of the corresponding private key.
Conversely, the private key remains secret and is used for decrypting the encrypted messages.
Public key cryptography is named as such because the public key can be freely distributed among users, enabling secure communication without the need for a shared secret key.
So the correct option is B.
Learn more about Cryptography here:
https://brainly.com/question/88001
#SPJ11
Suppose a business records the following values each day the total number of customers that day (X) Revenue for that day (Y) A summary of X and Y in the previous days is mean of X: 600 Standard deviation of X: 10 Mean of Y: $5000, Standard deviation of Y: 1000 Correlation r= 0.9 Calculate the values A,B,C and D (1 mark) Future value of X Z score of X Predicted y average of y+ r* (Z score of X)* standard deviation of y 595 A B 600 0 $5000 D 615 IC You will get marks for each correct answer but note you are encouraged to show working. If the working is correct but the answer is wrong you will be given partial marks
Answers
The predicted values of A, B, C, and D are: A = 595B = -0.5C = 600D = $6350, therefore, the correct option is IC.
Given,
Mean of X = 600
Standard deviation of X = 10
Mean of Y = $5000
Standard deviation of Y = 1000
Correlation r= 0.9
Future value of X = 595
Z score of X = (X- Mean of X) / Standard deviation of X= (595-600) / 10 = -0.5
Using the formula, Predicted y = average of y+ r* (Z score of X)* standard deviation of y
Predicted y = $5000 + 0.9 * (-0.5) * 1000 = $4750
The predicted value of Y for X = 595 is $4750.
Now, to find the values of A, B, C, and D; we need to calculate the Z score of X = 615 and find the corresponding predicted value of Y.
Z score of X = (X- Mean of X) / Standard deviation of X= (615-600) / 10 = 1.5
Predicted y = average of y+ r* (Z score of X)* standard deviation of y
Predicted y = $5000 + 0.9 * (1.5) * 1000 = $6350
The predicted value of Y for X = 615 is $6350.
Hence, the values of A, B, C, and D are: A = 595B = -0.5C = 600D = $6350
Therefore, the correct option is IC.
learn more about predicted value here:
https://brainly.com/question/29745404
#SPJ11
Using the integral test, find the values of p� for which the series [infinity]∑n=21n(lnn)p∑�=2[infinity]1�(ln�)� converges. For which values of p� does it diverge? Explain
Answers
The integral test states that if a series is a sum of terms that are positive and decreasing, and if the terms of the series can be expressed as the values of a continuous and decreasing function, then the series converges if and only if the corresponding improper integral converges.
Let's apply the integral test to the given series. We need to find a continuous, positive, and decreasing function f(x) such that the series is the sum of the values of f(x) for x ranging from 2 to infinity.
For the first series, we have:
∑n=2∞n(lnn)p
Let f(x) = x(lnx)p. Then f(x) is continuous, positive, and decreasing for x ≥ 2. Moreover, we have:
f'(x) = (lnx)p + px(lnx)p-1
f''(x) = (lnx)p-1 + p(lnx)p-2 + p(lnx)p-1
Since f''(x) is positive for x ≥ 2 and p > 0, f(x) is concave up and the trapezoidal approximation underestimates the integral. Therefore, we have:
∫2∞f(x)dx = ∫2∞x(lnx)pdx
Using integration by substitution, let u = lnx, then du = 1/x dx. Therefore:
∫2∞x(lnx)pdx = ∫ln2∞u^pe^udu
Since the exponential function grows faster than any power of u, the integral converges if and only if p < -1.
For the second series, we have:
∑n=2∞1/n(lnn)²
Let f(x) = 1/(x(lnx)²). Then f(x) is continuous, positive, and decreasing for x ≥ 2. Moreover, we have:
f'(x) = -(lnx-2)/(x(lnx)³)
f''(x) = (lnx-2)²/(x²(lnx)⁴) - 3(lnx-2)/(x²(lnx)⁴)
Since f''(x) is negative for x ≥ 2, f(x) is concave down and the trapezoidal approximation overestimates the integral. Therefore, we have:
∫2∞f(x)dx ≤ ∑n=2∞f(n) ≤ f(2) + ∫2∞f(x)dx
where the inequality follows from the fact that the series is the sum of the values of f(x) for x ranging from 2 to infinity.
Using the comparison test, we have:
∫2∞f(x)dx = ∫ln2∞(1/u²)du = 1/ln2
Therefore, the series converges if and only if p > 1.
In summary, the series ∑n=2∞n(lnn)p converges if and only if p < -1, and the series ∑n=2∞1/n(lnn)² converges if and only if p > 1. For values of p such that -1 ≤ p ≤ 1, the series diverges.
To find the values of p for which the series converges or diverges using the integral test, we will first write the series and then perform the integral test.
The given series is:
∑(n=2 to infinity) [1/n(ln(n))^p]
Now, let's consider the function f(x) = 1/x(ln(x))^p for x ≥ 2. The function is continuous, positive, and decreasing for x ≥ 2 when p > 0.
We will now perform the integral test:
∫(2 to infinity) [1/x(ln(x))^p] dx
To evaluate this integral, we will use the substitution method:
Let u = ln(x), so du = (1/x) dx.
When x = 2, u = ln(2).
When x approaches infinity, u approaches infinity.
Now the integral becomes:
∫(ln(2) to infinity) [1/u^p] du
This is now an integral of the form ∫(a to infinity) [1/u^p] du, which converges when p > 1 and diverges when p ≤ 1.
So, for the given series:
- It converges when p > 1.
- It diverges when p ≤ 1.
In conclusion, using the integral test, the series ∑(n=2 to infinity) [1/n(ln(n))^p] converges for values of p > 1 and diverges for values of p ≤ 1.
Learn more about trapezoidal here:- brainly.com/question/8643562
#SPJ11
At Sally's market the ratio of apples to oranges is 4 to 7. If there are 28 oranges at her market
then how many apples are there?
Answers
Answer:
16 apples
Step-by-step explanation:
If the original ratio is 4:7.
Then we multiply both numbers by 4. Since 7 x 4 is 28.
So now you have (4x4):(7x4)
Your final ratio is 16 apples : 28 oranges
There are between 50and 60 eggs in a basket when mohammed counts by 3's,there are 2egg left left over when he counts by 5's there are 4 left over how many eggs are there in the basket
Answers
Answer: 59 eggs
Step-by-step explanation: Dividing 3 will get you 19 eggs with 2 left over. Dividing 59 by 5 will get you 11 eggs and 4 left over
PLEASEEE HELP 25 points
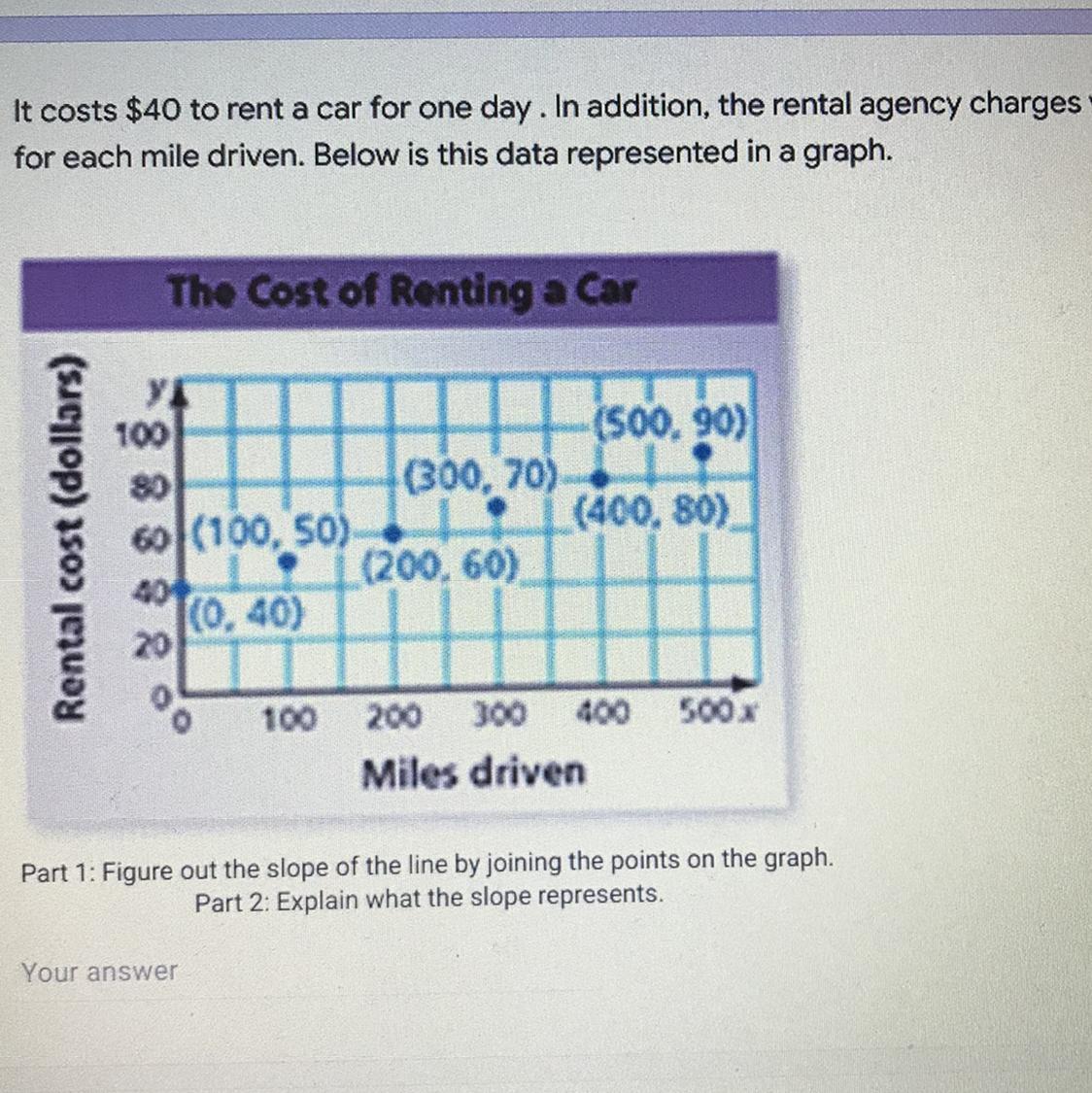
Answers
Answer:
slope= 1/10x and the slope represents the increase of the rental cost after x miles driven.
Step-by-step explanation:
i hope this helps :)
Find the values of a and b.The diagram is not to scale.
a.
b.
54°
a = 126, b = 54
a = 100, b = 80
100°
6°
c. a = 100, b = 54
d. a 126, b = 80
=

Answers
The value of the angles are; Option d. a 126, b = 80
How to determine the valuesTo determine the values of the variable, we need to know the properties of a trapezoid, we have;
The bases are parallel to each other.The median is parallel to both the bases and its length will be the average of the length of the bases.Sum of all the angles in a trapezoid is equal to 360 degreesThe sum of the angles on the same side is equal to 180 degreesFrom the information given, we have;
a + 54 = 180
collect like terms, we have;
a = 180 - 54
a = 126 degrees
Also,
b + 100 = 180
collect the like terms
b = 180 - 100
b = 80 degrees
Learn more about trapezoids at: https://brainly.com/question/1410008
#SPJ1
The water bottle sale for a music festival started at 5:00 P.M. The table shows the linear relationship between the number of water bottles remaining and the number of hours since 5:00 P.M.
Which equation can be used to determine y, the number of water bottles remaining at the music festival x hours after 5:00 P.M.?

Answers
The equation used to determine y, the number of water bottles remaining at the music festival x hours after 5:00 P.M will be;
⇒ y = - 500x + 5500
What is Equation of line?
The equation of line in point-slope form passing through the points
(x₁ , y₁) and (x₂, y₂) with slope m is defined as;
⇒ y - y₁ = m (x - x₁)
Where, m = (y₂ - y₁) / (x₂ - x₁)
Given that;
The table shows the linear relationship between the number of water bottles remaining and the number of hours since 5:00 P.M.
Now,
Find the linear equation for the given table as;
Take number of hours = x
And, Number of remaining bottles = y
So, Two points for the linear equation as;
⇒ (x, y) = (1, 5000) , (2, 4500)
Thus, The linear equation for the table is,
⇒ y - y₁ = (y₂ - y₁) / (x₂ - x₁) (x - x₁)
⇒ y - 5000 = (4500 - 5000) / (2 - 1) (x - 1)
⇒ y - 5000 = - 500 (x - 1)
⇒ y - 5000 = - 500x + 500
⇒ y = - 500x + 500 + 5000
⇒ y = - 500x + 5500
Thus, The equation used to determine y, the number of water bottles remaining at the music festival x hours after 5:00 P.M will be;
⇒ y = - 500x + 5500
Learn more about the equation of line visit:
https://brainly.com/question/18831322
#SPJ1
factorise: 3 a^3+4a-3
Answers
Answer:
Non of the REMAINDERS is ZERO and as such the expression is not factorable.
Step-by-step explanation:
Systolic Blood Pressure (SBP) of 13 workers follows normal distribution with standard deviation 10. SBP are as follows: 129, 134, 142, 114, 120, 116, 133, 142, 138, 148 , 129, 133, 140_ Find the 99%0 confidence interval for the mean SBP level: (124.84 (129.84 (126.84 (125.84 139.16) 139.16) 137.16) 138.16)
Answers
Answer:The 99% confidence interval is
To find the 99% confidence interval for the mean systolic blood pressure (SBP) level, we use the formula:
CONFIDENCE INTERVAL = Mean ± Z * (Standard Deviation / √n)
Where:
Mean is the sample mean of SBP
Z is the Z-score corresponding to the desired confidence level
Standard Deviation is the population standard deviation
Explanation:
Given that the sample size is 13 and the standard deviation is 10, we need to calculate the sample mean and the Z-score for the 99% confidence level.
First, we calculate the sample mean:
Mean = (129 + 134 + 142 + 114 + 120 + 116 + 133 + 142 + 138 + 148 + 129 + 133 + 140) / 13
= 1724 / 13
≈ 132.62
Next, we need to determine the Z-score for a 99% confidence level. The Z-score can be found using a Z-table or a statistical calculator. For a 99% confidence level, the Z-score is approximately 2.576.
Now, we can calculate the confidence interval:
Confidence Interval = 132.62 ± 2.576 * (10 / √13)
132.62 ± 2.576 * (10 / 3.6056)
≈ 132.62 ± 2.576 * 2.771
≈ 132.62 ± 7.147
Therefore, the 99% confidence interval for the mean SBP level is approximately (125.47, 139.77).
1. A revenue of $2000 is obtained from the sales of item A at $40 each and item B at $35 each. Write an
equation that shows the relationship between the numbers of items sold.
2. A revenue of $3000 is obtained from the sales of item A at $50 each and item B at $80 each. Write an equation that shows the relationship between the numbers of items sold.
Answers
Answer:
Step-by-step explanation:
Hi vengefull, :0 like that show on Netflix about revenge, huh :0 anyway, back to math.
the equation 1):
40*A+ 35*B=2000
the equation 2):
50*A + 80*B=3000
A
-4
Which of the following is the
graph of
(x + 1)² + (y − 2)² = 4 ?
2
-2 0
-2
•
2 4
B
-6 -4
+2
-2 0
2
C
-4
2
-2 0
-2
2

Answers
Answer:
graph B
Step-by-step explanation:
(x+1)²+(y-2)²=4
comparing the equation with equation of circle
(x-h)²+(y-k)²=r²
we get
h=(-1), k=2, r=2
point(-1,2) is the center of circle
radius=2
point(-1,2) and radius=2 satisfies the graph B
A sample survey interviews SRSs of 500 female college students and 550 male college students. Each student is asked whether he or she worked for pay last summer. In all, 410 of the women and 484 of the men say "yes".Take Pm and Pf to be the proportions of all college males and females who worked last summer. We conjectured before seeing the data that men are more likely to work. The hypotheses to be test are:a. H₀: Pm - Pf = 0 vs. Hₐ: Pm - Pf ≠ 0b. H₀: Pm - Pf = 0 vs. Hₐ: Pm - Pf > 0c. H₀: Pm - Pf = 0 vs. Hₐ: Pm - Pf < 0d. H₀: Pm - Pf > 0 vs. Hₐ: Pm - Pf = 0e. H₀: Pm - Pf ≠ 0 vs. Hₐ: Pm - Pf = 0
Answers
The correct hypotheses to be tested based on the given information are H₀: Pm - Pf = 0 vs. Hₐ: Pm - Pf < 0 (option c).
These hypotheses reflect the conjecture that men are more likely to work than women. In hypothesis testing, the null hypothesis (H₀) typically represents the assumption of no difference or no effect, while the alternative hypothesis (Hₐ) represents the claim or hypothesis we want to support.
In this case, the null hypothesis states that there is no difference between the proportions of male and female college students who worked last summer (Pm - Pf = 0). The alternative hypothesis states that the proportion of male college students who worked last summer is greater than the proportion of female college students who worked (Pm - Pf < 0).
By testing these hypotheses using appropriate statistical methods, we can determine if the observed data supports the claim that men are more likely to work than women or if there is no significant difference between the two proportions. The correct option is c.
To know more about hypotheses:
https://brainly.com/question/32562440
#SPJ4
Select the correct answer.
You're given three angle measurements of 30° 70°, and 80°. How many triangles can you construct using these measurements?
OA 0
OB.
OC 2
OD. infinitely many
Reset
Next
Edmentum. All rights reserved.
Answers
Answer:
infinitely many
Step-by-step explanation:
All triangles that you can construct will be "similar", in that they have the same angles, but different sizes. The angles have to add up to 180, and they do in the measurements that you're given.
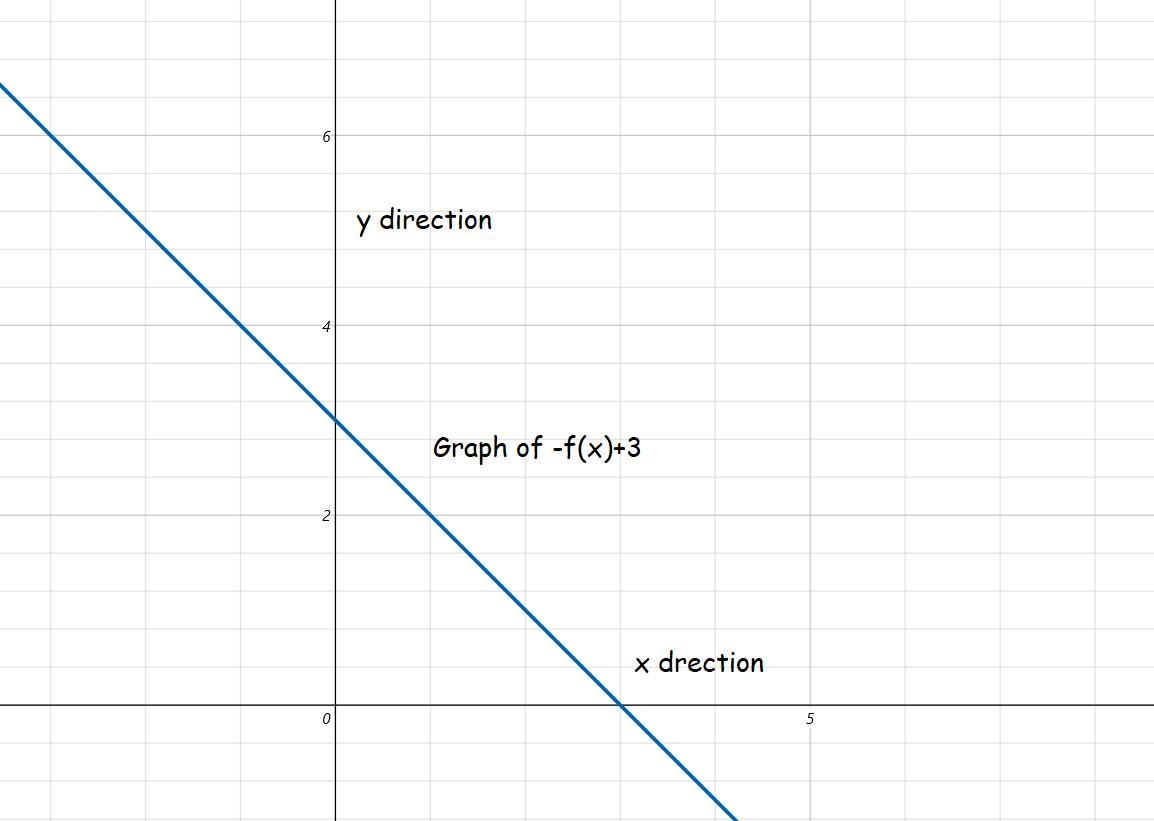
Which is the graph of y = -f(x) + 3?
Answers
The graph of y = -f(x) + 3 is a graph that has a negative slope and is attached.
What is graph of equation of a straight line?A graph is a representation of data using the coordinate system. There are different types of graph each defining the required data.
The graph of equation of a straight line is one of the types of graphs. The graph of the form y = mx + c represents the equation of a straight line. The terms are defined as follows
m =slope of the linec = y interceptThe slope is a function of x and from the question it is negative.
The graph is plotted and attached
Read more on graphs here: https://brainly.com/question/19040584
#SPJ1
Please help my work is almost due and I have no clue

Answers
Answer:
4 = x
Step-by-step explanation:
64 = x^3
Take the cube root of each side
64^ (1/3) = x^3 ^ (1/3)
4 = x
Explain how to modify the graphs F(x) and g(x) to graph the solution to set the following system of inequalities. How can the solution set be identified? Y>x^2-1
Y<-x^2+4

Answers
The following rigid transformations are applied:
Reflection around the line y = -1.Translation 5 units in the +y direction.The solution set is found by the fact that the domain of quadratic functions is the entire real domain.
How to apply rigid transformations to understand the differences between two given functions
According to the Euclidean geometry, rigid transformations are those transformations applied on geometrical loci such that Euclidean distances are conserved in every point of the loci. Reflections and translations are sound examples of rigid transformations.
In this question we must derive all needed rigid transformations to turn f(x) into g(x), both quadratic functions. After a careful analysis we conclude that the following rigid transformations are applied:
Reflection around the line y = -1.Translation 5 units in the +y direction.The solution set is represent by all x-values such that the function exists. According to real algebra we remember that the domain of quadratic functions is the real domain. Thus, the solution sets of f(x) and g(x) are the real domain.
To learn more on rigid transformations, we kindly invite to check this verified question: https://brainly.com/question/1761538
Is it A,B,C or D I´m stuck on this..

Answers
Answer d
Step-by-step explanation:d
Answer:
c. 51
Step-by-step explanation:
A traffic helicopter descended 140 meters to observe road conditions. if the original altitude was 400 meters, what was the ending altitude?
Answers
Answer: 360
Step-by-step explanation:
400 meters to start and descending 140
400-140=360
You have three sticks. Each stick has one red side and one blue side. You throw the sticks 10 times and record the results. Use the table to find the experimental probability of the event.

Answers
Answer:
4 + 4 + 2 = 10
3) 3/10 or 0.3
4) 2/10 = 1/5 or 0.2
5) 4/10 = 2/5 or 0.4
6) 2 + 4 + 0 = 6 so 6/10 = 3/5 or 0.6
i think its this. i hop i helped?
Step-by-step explanation:
is -√9 an irrational or rational number?
please help!
Answers
Answer:
no it is not
Step-by-step explanation:
Answer:
Irrational Number
Step-by-step explanation:
Irrational number: A number that can't be written as a fraction.
- Non Recurring numbers, and non terminating numbers fall into the irrational category
70% of which number gives me 300?
Answers
Answer:
428 4/7 ≈ 428.6
Step-by-step explanation:
You want to find a number such that ...
70% × number = 300
The solution is found by dividing by the coefficient of the number:
number = 300/0.70 = 428 4/7
70% of 428 4/7 gives me 300.
how similar is the code for doing k-fold validation for least-squares regression vs. logistic regression
Answers
The code for k-fold validation in least-squares and logistic regression involves splitting the dataset into k folds, importing libraries, preprocessing, splitting, iterating over folds, fitting, predicting, evaluating performance, and calculating average performance metrics across all folds.
The code for performing k-fold validation for least-squares regression and logistic regression is quite similar. Both methods involve splitting the dataset into k folds, where k is the number of folds or subsets. The code for both models generally follows the same steps:
1. Import the necessary libraries, such as scikit-learn for machine learning tasks.
2. Load or preprocess the dataset.
3. Split the dataset into k folds using a cross-validation function like KFold or StratifiedKFold.
4. Iterate over the folds and perform the following steps:
a. Split the data into training and testing sets based on the current fold.
b. Fit the model on the training set.
c. Predict the target variable on the testing set.
d. Evaluate the model's performance using appropriate metrics, such as mean squared error for least-squares regression or accuracy, precision, and recall for logistic regression.
5. Calculate and store the average performance metric across all the folds.
While there may be minor differences in the specific implementation details, the overall structure and logic of the code for k-fold validation in both least-squares regression and logistic regression are similar.
To know more about logistic regression Visit:
https://brainly.com/question/32505018
#SPJ11
HELPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPP

Answers
Answer:
57.18
Step-by-step explanation:
C = 2πr
C = 2(π)(9.1)
C = 57.18
.
=2×22/7×12
=75.42in
And
d=18.2cm
\(c = \pi \: d\)
= 22/7×18.2
=57.2cm
A basketball coach plotted data about her shooting guard’s playing time and point scoring in a scatterplot. Shooting Guard Minutes Played and Points Scored A graph has minutes played on the x-axis, and points scored on the y-axis. A line goes through points (8, 6) and (30, 21). Which is the equation of the line of best-fit? y = StartFraction 15 Over 22 EndFraction x + StartFraction 6 Over 11 EndFraction y = StartFraction 15 Over 22 EndFraction x + StartFraction 43 Over 11 EndFraction y = StartFraction 22 Over 15 EndFraction x minus StartFraction 86 Over 15 EndFraction y = StartFraction 22 Over 15 EndFraction x minus four-fifths
Answers
Answer:
The answer is y = StartFraction 15 Over 22 EndFraction x + StartFraction 6 Over 11 EndFraction → y = 15/22x + 6/11
Answer:
it a
Step-by-step explanation: