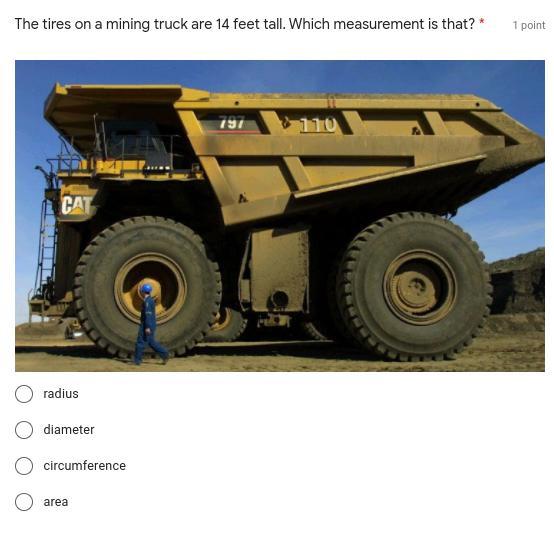
Answers
Answer:
B. Diameter is the answer.
Related Questions
i need to know who is correct or not in PART C, please help!!!

Answers
Answer:
Both are correct with respect to the final purchase price.
Lisa is correct, in terms of appropriate accounting procedure
Step-by-step explanation:
The total amount paid by Lisa's method and by Ross's method will be the same. The multiplication factors in each case are (1-0.15) = 0.85 and (1 +0.08) = 1.08. The commutative property of multiplication tells you the product is the same, regardless of the order in which the factors are applied.
The order of application of tax and discount does not matter for the final price.
__
As a practical matter, Lisa is correct. The store will owe sales tax to the government based on the net sales of the store. If the cash register records the sale as $495, then extra accounting steps are required so the store can avoid paying tax on that amount. However, if the cash register records the sale as 15% less than $495, the tax paid to the government is easily justified.
__
The attachment shows the intermediate computed values in both cases. The final value is the same.

MA.912.AR.2.5
23. A hot air balloon company charges for evening sunset flights are based on the function y = 25x + 100, where x is
the number of people traveling in the basket (note the basket capacity limit is 8) and y is the cost of the trip in dollars.
What is the base fee for the balloon ride before passengers are figured in? What does the 25 represent?
Answers
100$ before passengers. 25 is the price per person. 225 for 5 people to fly.
What are linear equation?One variable can be used to solve a linear equation by moving the variables to one side of the problem and the numerical component to the other. As an example, the equation x - 1 = 5 - 2x can be solved by moving the numerical components to the equation's right side while leaving the variables on the left. Consequently, we get x + 2x = 5 + 1. 3x = 6 as a result. Consequently, x = 2. A linear equation with two variables has the formula Ax + By + C = 0, where A and B are the coefficients, C is a constant term, and the two variables, x and y, each have a degree of one. 7x + 9y + 4 = 0, for instance, is a two-variable linear equation.
To know more about linear equation ,visit:
brainly.com/question/11897796
#SPJ13
An encryption machine uses a formula to encrypt words, by taking each letter and changing it to the letter that is just before it in the alphabet. If the letter is 'a', it changes it to 'z'. If you put the word ARMS into the machine, what would the output be?
A. ZSRA
B. ZOLR
C. SMRA
D. RMSA
Answers
Answer:
ZQLR
Step-by-step explanation:
Hope this helps!
The average McDonald's restaurant generates $3.7 million in sales each year with a standard deviation of 0.8. Sabrina wants to know if the average sales generated by McDonald's restaurants in New York is different than the worldwide average. She surveys 19 restaurants in New York and finds the following data (in millions of dollars): 5.3,6.3,4.5,3.7,5,3.9,4.4,3.6,4.3,5.8,3.3,4.9,4.7,4.7,3.9,5,5.7,3.4,5.3 Perform a hypothesis test using a 1% level of significance. Step 1: State the null and alternative hypotheses. H0 : Ha : (So we will be performing a test.) Step 2: Assuming the null hypothesis is true, determine the features of the distribution of point estimates using the Central Limit Theorem. By the Central Limit Theorem, we know that the point estimates are with distribution mean and distribution standard deviation Step 3: Find the p-value of the point estimate. P )=P(∣)= p-value = Step 4: Make a Conclusion About the null hypothesis.
Answers
The average sales generated by McDonald's restaurants in New York is different from the worldwide average and the p-value is less than the significance level of 0.01
Step 1: State the null and alternative hypotheses.
The null hypothesis is that the average sales generated by McDonald's restaurants in New York is equal to the worldwide average of $3.7 million. The alternative hypothesis is that the average sales generated by McDonald's restaurants in New York is different from the worldwide average.
\(H_0: \mu = 3.7\)
\(H_A: \mu \neq 3.7\)
Step 2: Assuming the null hypothesis is true, determine the features of the distribution of point estimates using the Central Limit Theorem.
By the Central Limit Theorem, we know that the point estimates are normally distributed with mean \mu$ and standard deviation
\($\frac{\sigma}{\sqrt{n}}\)
. In this case, the mean is \(3.7\)\($\)and the standard deviation is
\(frac{0.8}{\sqrt{19}} = 0.22$.\)
Step 3: Find the p-value of the point estimate.
The p-value is the probability of obtaining a sample mean that is at least as extreme as the observed sample mean, assuming the null hypothesis is true. In this case, the observed sample mean is 4.5. The p-value can be calculated using the following steps:
1. Calculate the z-score of the sample mean.
2. Look up the z-score in a z-table to find the corresponding p-value.
The z-score is calculated as follows:
\(z = \frac{\bar{x} - \mu}{\sigma/\sqrt{n}} = \frac{4.5 - 3.7}{0.22} = 4.545\)
The p-value for a z-score of 4.545 is less than 0.001.
Step 4: Make a Conclusion About the null hypothesis.
Since the p-value is less than the significance level of 0.01, we can reject the null hypothesis. This means that there is sufficient evidence to conclude that the average sales generated by McDonald's restaurants in New York is different from the worldwide average.
Learn more about average with the given link,
https://brainly.com/question/130657
#SPJ11
during the 2000 season, the home team won 138 of the 240 regular season national football league games. is this strong evidence of a home field advantage in professional football? test an appropriate hypothesis and state your conclusion. be sure the appropriate assumptions and conditions are satisfied before you proceed.
Answers
A) The 95% confidence interval is:
0.58 ± 0.062
B) At the 0.01 probability value, there is neither substantial evidence of a home-field advantage in professional football (they won and over half of the games).
Now, According to the question:
A) Confidence interval is written as
Sample proportion ± margin of error
Margin of error = z × \(\frac{\sqrt{pq} }{n}\)
Where:
z = The z score corresponds to the amount of confidence.
p = sample proportion.
q = probability of failure
q = 1 - p
p = x/n
Where
n = the number of samples
x = the number of success
From the information given,
n = 240
x = 138
p = 138/240 = 0.58
q = 1 - 0.58 = 0.42
To determine the z score, The confidence level from 100% to get α
α = 1 - 0.95 = 0.05
α/2 = 0.05/2 = 0.025
Thus,
1 - 0.025 = 0.975
The z -score associated with the area just on z table approximately 1.96. Therefore, the z score with a 95% confidence level is 1.96.
As a result, the 95% confidence interval becomes
0.58 ± 1.96√(0.58)(0.42)/240
Confidence interval is
0.58 ± 0.062
B) Earning more than half of the games equates to winning 120 games or more.
p = 120/240 = 0.5
The hypothesis test will be
For the null hypothesis,
P ≥ 0.5
For the alternative hypothesis,
P < 0.5
Probability of success, p = 0.5
q = probability of failure = 1 - p
q = 1 - 0.5 = 0.5
Considering the sample,
Sample proportion, P = x/n
Where
x = number of success = 138
n = number of samples = 240
P = 138/240 = 0.58
We need to find the values of the test statistic which will be the z score
z = (P - p)/√pq/n
z = (0.58 - 0.5)/√(0.5 × 0.5)/240 = 2.48
Remember that this is a two-tailed test. We would use the normal distribution table to calculate the probability potential of the property to the right of both the z score.
P value will be = 1 - 0.9934 = 0.0066
Since alpha, 0.01 > the p value, 0.0066, then we would reject the null hypothesis.
The given question is incomplete, The complete question is this:
__"During the 2000 season, the home team won 138 out of 240 regular season National Football League games. (15 points) a) Construct a 95% confidence interval for the winning proportion of the home team during this season. b) At the 0.01 significance level, is there strong evidence of a home field advantage (they win more than half of the games) in professional football? State hypotheses, calculate the test statistic and p-value, and make a conclusion in context"__
Learn more about Confidence Interval at:
https://brainly.com/question/29680703
#SPJ4
6. A lighting fixture manufacturer has daily production costs of c=0.25n²-10n+800, where C is the total
daily cost in dollars and n is the number of light fixtures produced.
a) Is the manufacturer's cost increasing or decreasing when they produce between 10 and 15 light fixtures?
Prove your claim with math. (2 pts)
b) Is the manufacturer's cost increasing or decreasing when they produce between 20 and 25 light fixtures?
Prove your claim with math. (2 pts)
Answers
By finding the average rate of change, we can see that:
a) The cost decreases.
b) The cost increases.
How to know when the cost is increasing or decreasing?
To check that, we need to find the average rate of change on the interval.
Remember that for function f(x) on an interval (a, b), the average rate of change is:
R = (f(b) - f(a))/(b - a)
Here the cost function is:
c(n) = 0.25*n² - 10n + 800
a) In the interval [10, 15] the average rate of change is given by:
R = (c(15) - c(10)/(15 - 10)
Where:
c(15) = 0.25*15^2 - 10*15 + 800 = 706.25
c(10) = 0.25*10^2 - 10*10 + 800 = 725
Then the average rate of change is:
R = (706.25 - 725)/(15 - 10) = -3.75
This means that between 10 and 15 light fixtures, the cost is decreasing.
b) Now we have the interval [20, 25], so let's do the same ting:
c(20) = 0.25*20^2 - 10*20 + 800 = 700
c(25) = 0.25*25^2 - 10*25 + 800 = 706.25
Here the average rate of change is:
R = (706.25 - 700)/(25 - 20) = 1.25
It is positive, which means that the cost is increasing.
Learn more about average rate of change:
https://brainly.com/question/8728504
#SPJ1
are these answers right? if not tell me what number and the explanation thank you :)

Answers
Answer:
theyre correct
Step-by-step explanation:
you have nine different color paints. you want to paint five different pots such that no two pots have the same color. how many ways are there to paint the pots?
Answers
The number of ways to paint the pots can be found using permutations and is found to be 15120 ways.
What are permutations?
An arrangement of all or a portion of a collection of items, taking into account the arrangement's order, is referred to as a permutation.
Here, we know that there are 9 different paints to choose from, so we are required to find the number of ways we can paint 5 pots without repeating any color.
This can be given by \(9P_{5}\) ways.
\(=\frac{9!}{(9-5)!} \\=\frac{9!}{4!} \\=15120\space\ ways\).
Therefore, the number of ways to paint the pots is 15120 ways.
To learn more about permutations, visit the following link:
https://brainly.com/question/1216161
#SPJ4
A train travels 625 kiy north in 15 hours. What is the bus's velocity?
Answers
41.6666667
Step-by-step explanation:
Velocity = distance/time
Velocity = 625/15
Velocity = 41.6666667
Please explain!!
C=4 π
A=

Answers
Answer: 12.56unit
Step-by-step explanation:
Given three points, A(4,3,2),B(−2,0,5), and C(7,−2,1) : specify the vector A extending from the origin to point A
4a
x
+3a
y
+2a
z
2a
x
+3a
y
−3a
z
−3a
x
+a
y
+a
z
5a
x
−2a
y
−4a
z
QUESTION 2 Given the vectors M=−10a
x
+4a
y
−8a
z
and N=8a
x
+7a
y
−2a
z
, find: a unit vector in the direction of −M+2N
(0.92,0.36,0.14)
(26,10,4)
(16,14,4)
(−10,4,−8)
Answers
The vector A extending from the origin to point A(4, 3, 2) can be represented as: A = 4ax + 3ay + 2az, where ax, ay, and az represent the unit vectors in the x, y, and z directions, respectively. Therefore, the vector A can be written as (4, 3, 2) in terms of its components.
The vector A represents the displacement from the origin to point A in a three-dimensional coordinate system. It is determined by the differences in the x, y, and z coordinates between the origin and point A. In this case, the x-coordinate of point A is 4, the y-coordinate is 3, and the z-coordinate is 2. Therefore, the vector A can be expressed as (4ax + 3ay + 2az) in terms of its components.
The unit vectors ax, ay, and az represent the direction of the x, y, and z axes, respectively. By multiplying each unit vector by its respective coordinate value and summing them, we obtain the vector A. Thus, the vector A extending from the origin to point A can be specified as (4, 3, 2) in terms of its components.
Learn more about coordinate here:
https://brainly.com/question/32836021
#SPJ11
true or false? "Because in a randomized controlled trial (RCT), the assignment is random, therefore there is no coverage bias---by definition" g
Answers
The statement "Because in a randomized controlled trial (RCT), the assignment is random, therefore there is no coverage bias---by definition" g is false because, it is important to consider both randomization and other factors when assessing the potential for bias in an RCT.
Random assignment in an RCT can help to reduce selection bias, but it does not guarantee the absence of coverage bias.
Coverage bias can occur if the participants who are enrolled in the trial do not represent the population to which the results will be generalized.
For example, if the trial only includes participants who are healthier or more compliant than the typical patient, the results may not be applicable to the broader population.
Therefore, it is important to consider both randomization and other factors when assessing the potential for bias in an RCT.
for such more question on RCT
https://brainly.com/question/23819325
#SPJ11
the method of reduction of order can also be used for the nonhomogeneous equationa. trueb. false
Answers
The method of reduction of order is a technique used to find a second solution to a homogeneous linear differential equation when one solution is already known.
However, it cannot be directly used for nonhomogeneous linear differential equations. In nonhomogeneous equations, the method of undetermined coefficients or variation of parameters is typically used to find a particular solution.
Therefore, the statement "the method of reduction of order can also be used for the nonhomogeneous equation" is false. It is important to understand the different techniques for solving differential equations, and to choose the appropriate method based on the type of equation and boundary conditions given.
To know more about homogeneous linear differential equation visit:
https://brainly.com/question/31129559
#SPJ11
Z scores tell us how many standard deviations is any original score X away from the mean of the sample
True False
Answers
To calculate the Z-Score, subtract the mean from the score, then divide by the standard deviation.
True. Z-Scores tell us how many standard deviations away a score is from the mean. To calculate the Z-Score of a particular score, X, the following steps should be followed:
1. Calculate the mean, μ, of the sample.
2. Calculate the standard deviation, σ, of the sample.
3. Calculate the Z-Score of the particular score X by subtracting the mean from the score and dividing it by the standard deviation. The resulting number is the Z-Score.
For example, if we had a sample of 10 test scores with a mean of 70 and a standard deviation of 10, and we wanted to find the Z-Score of a particular score of 80, we would take the score of 80 and subtract the mean of 70 to get 10. We would then divide 10 by the standard deviation of 10 to get a Z-Score of 1. This means the score of 80 is one standard deviation away from the mean of 70.
Learn more about mean here
https://brainly.com/question/30094057
#SPJ4
plsssss help me i’m struggling so bad
Choose the definition for the function.
a.y={-2x +
1-2x + 1 x < 1
-x+ 2 x > 1
s-2x +1 x > 1
c. y =
.-x+2 x < 1
b. y =
-2x + 1
-x+ 2 2
x < 1
x > 1
r-2x + 1
-x+2
Enter

Answers
Answer:
a.
Step-by-step explanation:
Answer is a.
For the first line where x<=1, y= -2x+1. Slope is -2 as the line passes through (0,1) and (1,-1).
For the second line where x>1, y=-x+2. Slope is -1, as the line passes through ( 2,0) and (3,-1)
An English instructor asserted that students' test grades are directly proportional to the amount of time spent studying. Lisa studies 4 hr for a particular test and gets a score of 72. At this rate, how many hours would she have had to study to get a score of 96?
Answers
Answer:
12 hours.
Step-by-step explanation:
Parallel Lines Write an equation in slope-intercept form for the line that passes through the point and is parallel to the line.
line: y = 3x + 3 point: (0,3)
SHOW WORK!!
Answers
Answer:
y = 3x + 3
Step-by-step explanation:
Since the line we want to find is parallel to the given line, it will have the same slope as the given line, which is 3. Also, we know that the line passes through the point (0,3). We can use this information to write the equation of the line in slope-intercept form:
y = mx + b
where m is the slope and b is the y-intercept.
Using the values we know, we can substitute m = 3 and x = 0, y = 3 into the equation and solve for b:
3 = 3(0) + b
b = 3
So the equation of the line in slope-intercept form is:
y = 3x + 3
May anyone help me with this please

Answers
Answer:
x = - 8, x = - 4
Step-by-step explanation:
Given
x² + 15x + 30 = 3x - 2 ( subtract 3x - 2 from both sides )
x² + 12x + 32 = 0 ← in standard form
Consider the factors of the constant term (+ 32) which sum to give the coefficient of the x- term (+ 12)
The factors are + 8 and + 4 , since
8 × 4 = + 32 and 8 + 4 = + 12 , then
(x + 8)(x + 4) = 0 ← in factored form
Equate each factor to zero and solve for x
x + 8 = 0 ⇒ x = - 8
x + 4 = 0 ⇒ x = - 4
What if median is higher than mean skewed?
Answers
The distribution of the data is typically considered to be skewed to the right if the median is higher than the mean.
So the distribution of the data is typically considered to be skewed to the right if the median is higher than the mean (positively skewed). In other words, the distribution's tail is longer to the right than to the left. Take the following values, for instance, 1, 2, 3, 5, 100, as part of a dataset. This dataset has a mean of 22.2 and a median of 3, with the mean being (1 + 2 + 3 + 5 + 100) / 5 = 22.2. The distribution is positively skewed with a lengthy tail of high values in this instance because the median is significantly lower than the mean. If a few extreme values in the dataset are significantly higher than the remainder of the range, the distribution may be positively skewed.
Therefore, In other words, the distribution's tail is longer to the right than to the left. Take the following values, for instance, 1, 2, 3, 5, 100, as part of a dataset. This dataset has a mean of 22.2 and a median of 3, with the mean being (1 + 2 + 3 + 5 + 100) / 5 = 22.2.
Learn more about distribution here:
https://brainly.com/question/29062095
#SPJ4
PLEASE HELP! 20 question

Answers
Answer:
C
Step-by-step explanation:
So we have the following sequence:
-7, -3, 1, 5...
As given, the (direct) formula for any arithmetic sequence is:
\(a_n=a_1+d(n-1)\)
Where aₙ is the value of the nth term, a₁ is the value of the first term, and d is the common difference.
From the sequence, we can see that the initial/first term is -7. Thus, a₁ is -7.
And we can see that each subsequent number if 4 greater than the previous one. Thus, the common difference is +4.
Therefore, plugging these into our equation, we have:
\(a_n=-7+4(n-1)\)
The answer is C.
if C = 5/9(f-32)find the value of f when c=30
Answers
The answer for this equation would be f = 86
What is √5times√12times√50
Answers
Answer:
Step-by-step explanation:
We can simplify the expression √5 × √12 × √50 as follows:
√5 × √12 × √50 = √(5 × 12 × 50)
To simplify the product under the square root, we can factor the numbers into their prime factors:
5 = 5
12 = 2^2 × 3
50 = 2 × 5^2
Therefore, 5 × 12 × 50 = 2^2 × 3 × 5^3 = 2^2 × 5^3
Substituting this back into the original expression, we get:
√5 × √12 × √50 = √(2^2 × 5^3)
Taking the square root of the product, we can simplify further:
√5 × √12 × √50 = √(2^2) × √(5^3) = 2 × 5√5^2 = 2 × 5 × 5 = 50
Therefore, √5 × √12 × √50 simplifies to 50.
work out the reskuts of these changes.
a) a crowd of 8000 people increases by 20%
(b) the price of a $43 000 car decreased by 6%
(c) the mass of a 3.20 kh baby uncreases by 80%
Answers
Answer:
a is the amount of people went up by 1600 so its 9600
b is it went down by $2580 so the price is now 40420
c so the baby went up by 2.56 kh and now weighs 5.76 kh
Step-by-step explanation:
a university charges students $2,300 less for tuition each year to encourage them to stay in school. the tuition for freshman year is $34,000. write a regression equation for this formula, with y
Answers
a regression equation for this formula, where x represents the number of years enrolled and y represents the tuition.
y = 34000 - 2300x
Regression is a statistical technique that connects one or more independent (explanatory) variables to a dependent variable. If there is a relationship between changes in one or more of the explanatory factors and changes in the dependent variable, it can be shown using a regression model.
The regression equation for this formula would be:
Y = 34,000 - 2,300x
where Y is the tuition cost and x is the number of years in school.
The equation states that the tuition cost for any year in school (x) is equal to the freshman year tuition cost (34,000) minus 2,300 multiplied by the number of years in school (x).For example, if x = 4 (4 years in school), then the tuition cost for that year would be 34,000 - 2,300(4) = 25,400.
learn more about regression here
https://brainly.com/question/28178214
#SPJ4
Given that \( z \) is a standard normal random variable, compute the following probabilities. Round your answers to 4 decimal places. a. \( P(0 \leq z \leq 0.59) \) b. \( P(-1.51 \leq z \leq 0) \) c.
Answers
The probability\(\( P(0 \leq z \leq 0.59) \)\) is approximately 0.2236.
To calculate this probability, we need to find the area under the standard normal curve between 0 and 0.59. We can use a standard normal distribution table or a calculator to find the corresponding z-scores and then calculate the probability?To calculate the probability, we need to find the area under the standard normal curve between 0 and 0.59. This can be done by using the standard normal distribution table or a calculator.
The table provides the cumulative probability up to a given z-value. For 0, the cumulative probability is 0.5000, and for 0.59, the cumulative probability is 0.7224. To find the probability between these two values, we subtract the cumulative probability at 0 from the cumulative probability at 0.59:
0.7224
−
0.5000
=
0.2224
0.7224−0.5000=0.2224. Rounded to four decimal places, the probability is approximately 0.2217.
Learn more about probability
brainly.com/question/31828911
#SPJ11
A total of 46 percent of the voters in a certain city classify themselves as Indepen-dents, whereas 30 percent classify themselves as Liberals and 24 percent say thatthey are Conservatives. In a recent local election, 35 percent of the Independents,62 percent of the Liberals, and 58 percent of the Conservatives voted. A voter ischosen at random. Given that this person voted in the local election what is theprobability that he or she is
Answers
Complete question :
A total of 46 percent of the voters in a certain city classify themselves as Indepen-dents, whereas 30 percent classify themselves as Liberals and 24 percent say thatthey are Conservatives. In a recent local election, 35 percent of the Independents,62 percent of the Liberals, and 58 percent of the Conservatives voted. A voter ischosen at random. Given that this person voted in the local election what is theprobability that he or she is Given that this person voted in the local election, what is the probability that he or she is (a) an Independent? (b) a Liberal? (c) a Conservative? (d) What fraction of voters participated in the local election?
Answer:
A) 0.331 ; B) 0.383 ; C) 0.286 ; D) 0.4862
Step-by-step explanation:
Given the following :
P(Independent(I)) = 46/100 = 0.46
P(Liberal(L)) = 30/ 100 = 0.3
P(Conservative(C)) = 24 / 100 = 0.24
Election participation (EP) :
P(EP | I) = 35 / 100 = 0.35
P(EP | L) = 62/100 = 0.62
P(EP | C) = 58/100 = 0.58
P(EP) = P(EP | L)*P(L) + P(EP | I)*P(I) + P(EP | C)*P(C)
P(EP) = (0.62*0.3) + (0.35*0.46) + (0.58*0.24)
P(EP) = 0.186 + 0.161 + 0.1392 = 0.4862
A) probability of Independent given that the person participated in election:
P(I Given EP) = [P(EP | I) * P(I)] / P(EP)
= (0.35 * 0.46) / 0.4862
= 0.161 / 0.4862
= 0.331
B) probability of Liberals given that the person participated in election:
P(L Given EP) = [P(EP | L) * P(L)] / P(EP)
= (0.62 * 0.3) / 0.4862
= 0.186 / 0.4862
= 0.383
C.) P(C Given EP) = [P(EP | C) * P(C)] / P(EP)
= (0.58 * 0.24) / 0.4862
= 0.1392 / 0.4862
= 0.286
There are 9 members on a board of directors. if they must elect a chairperson, a secretary, and a treasurer, how many different slates of candidates are possible? a. 504 c. 729 b. 84 d. 362,880
Answers
Answer:
A. 504
Step-by-step explanation:
on edge 2022
Answer:
A.
Step-by-step explanation:
EDG 2022
A car is traveling on Michigan Street towards Ward Street. The car plans to turn right onto Ward Street. What is the anglemeasure of the turn?85Ward St.The angle measure of the turn isMichigan St.Pennsylvania St

Answers
Given:
A car is traveling on Michigan Street towards Ward Street.
Required:
We need to find the measure of the angle when the car plans to turn right onto Ward Street.
Explanation:
We need to find the angle x marked in the given diagram.
Michigan Street road and Pennsylvania street road are parallel.
\(\angle OPN\text{ and }\angle MNQ\text{ are corresponding angles.}\)\(\angle OPN\text{ = }\angle MNQ=85\degree\)The angles MNQ and PNQ are linear pairs.
The sum of the linear pair is 180 degrees.
\(\angle MNQ+\text{ }\angle PNQ=180\degree\)\(85\degree+x=180\degree\)Subtract 85 from both sides of the equation.
\(85\degree+x-85\degree=180\degree-85\degree\)\(x=95\degree\)Final answer:
95 degrees angle measure the turn.


describe the difference between the standard deviation of the sampling distribution (standard error) and the standard deviation of each sample distribution as they apply to uncertainty.
Answers
The standard deviation of the sampling distribution, also known as the standard error, measures the amount of variability or uncertainty in the estimates of a population parameter (such as the mean) based on a sample. It is calculated as the standard deviation of the sample means (or other statistics) over all possible samples of the same size from the population.
The standard deviation of each sample distribution, on the other hand, measures the amount of variability or spread within the individual sample itself. It is calculated as the standard deviation of the individual observations within the sample.
Standard Deviation ComparisonIn general, the standard deviation of the sampling distribution decreases as the sample size increases, and it is used to estimate the uncertainty of the sample statistics. The standard deviation of the each sample distribution does not change with the sample size.
Learn more about Standard Deviation Comparison here:
https://brainly.com/question/29388631
#SPJ4
Sophia wants to foster creativity in her organization. She finds an online training program that claims to teach people how to approach workplace challenges in a more creative way. Sophia is skeptical but decides to give it a try. She randomly selects 40 employees and randomly assigns half of them to complete the online training program (n
Answers
The type of test that will be required in the organization is a two samples test assuming unequal variance.
What is a hypothesis?It should be noted that a hypothesis simply means a statement of expectation that will be tested by research.
From the complete question, the type of test that will be required in the organization is a two samples test assuming unequal variance. This is performed on the data of two random samples.
Learn more about hypothesis on:
https://brainly.com/question/11555274