
Answers
(4x+2)=(5x-25)
4x-5x=-25-2
-x=-27
x-27
x = 27
4x + 2 = 5x - 25
First, you need to move the 2 to the other side of the equation to make it: 4x = 5x -25 - 2. Now evaluate what -25 - 2 is then you'll have: 4x= 5x + 27. Now move 5 to the other side of the equation: 5x-4x= 27 = x = 27
so, our answer is x = 27
Related Questions
pls help solve this question!

Answers
Answer:
Yes, by AA, since angle DEF is congruent to HEJ (vertical angles are congruent), and angle DFE is congruent to HJE.
So triangle DEF is similar to triangle HEJ.
find the slope of the line that passes through (3, 7.5) and (7,17.5)
Answers
Answer:
5/2
Step-by-step explanation:
formula for the slope, in this case, is 17.5-7.5 over 7-3.
10
---
2
The slope is 10/2.
Let me know if you need to know how to graph it too
---
hope it helps
suppose you have a function of two variables, nand k; for instance h(n, k).if you are told that h(n, k)
Answers
Given a function of two variables, n and k, denoted as h(n, k), the function describes a mathematical relationship or operation that depends on the values of both n and k. Further details about the specific function, its definition, or purpose are required to provide a more comprehensive explanation.
A function of two variables, h(n, k), typically represents a mathematical relationship or operation that involves two independent variables, n and k. The specific form and purpose of the function can vary widely depending on the context or problem at hand.
To understand the behavior and properties of the function h(n, k), additional information is needed. This may include the mathematical expression defining the function, any constraints or conditions on the variables, and the intended interpretation or application of the function.
The function h(n, k) could represent various scenarios, such as a cost function in economics, a probability distribution in statistics, or a mathematical model in a scientific context. Without more details, it is challenging to provide a specific explanation or analysis of the function and its implications.
Learn more about probability here:
https://brainly.com/question/32117953
#SPJ11
One rectangle is "framed" within another. Find the area of the shaded region if the "frame" is 3 units wide.

Answers
Answer: 84 square inches.
Step-by-step explanation:
Side A of shaded: 5+3+3 = 11
Side B of shaded: 3+3+3= 9
11x9= 99
99-(3x5{normal rectangle area})= 84
Use a calculator to find the mean of the data. {217, 230, 214, 227, 196, 235, 220, 224, 208, 209, 191, 205, 184, 214, 219, 208, 227, 194, 228, 186, 201, 239}
Answers
To find the mean you need to find the average and to do that you need to add all values and divide by the number of values. When you add all of those numbers, you get 4676. There are 22 values so you would divide 4676 by 22. This answer is 212.5454 repeating.
Find the number of ways to write 24 as the sum of at least three positive integer multiples of 3. For example, count 3+18+3, 18+3+3, and 3+6+3+9+3, but not 18+6 or 24.
help pls
Answers
Okay, here are the steps to solve this problem:
1) 24 is divisible by 3. So any sum of 3 multiples of 3 that adds to 24 will have at least one multiple that is 6 (2 x 3) or 9 (3 x 3).
2) We can represent the multiples as: 3n, 3n+1, 3n+2 where n is an integer.
3) The 3n terms can only be 3, 6, 9, 12, 15, 18, 21. The 3n+1 terms can be 4, 7, 10, 13, 16, 19, 22. And 3n+2 terms can be 5, 8, 11, 14, 17, 20, 23.
4) We need to count the number of combinations of these terms that add to 24. Some options are:
3 + 9 + 12 = 24
6 + 9 + 9 = 24
12 + 6 + 6 = 24
15 + 3 + 6 = 24
18 + 3 + 3 = 24
5) In total, there are 5 options with 3 terms.
6) Additionally, we could have 4 term sums like:
3 + 6 + 9 + 6 = 24
6 + 6 + 6 + 6 = 24
There are 2 four-term options.
7) In total, there are 5 + 2 = 7 number of ways to write 24 as a sum of at least 3 positive integer multiples of 3.
Does this help explain the steps? Let me know if you have any other questions!
Find the domain and range of the function. Use a graphing utility to verify your results. (Enter your answers using interval notation.) f(x)=9 x^{3}+4 x^{2}-4 domain range
Answers
The correct value of Domain: (-∞, +∞) and Range: (-∞, +∞)
To find the domain and range of the function\(f(x) = 9x^3 + 4x^2 - 4,\) we can analyze the nature of the function and determine the possible values for x and corresponding values for f(x).
Domain:
The domain of a function refers to the set of all possible values of x for which the function is defined. In this case, there are no restrictions or limitations on the possible values of x. Therefore, the domain of f(x) = c\(9x^3 + 4x^2 - 4\)is (-∞, +∞) or all real numbers.
Range:
The range of a function represents the set of all possible values that the function can output or produce. To determine the range, we can analyze the behavior of the function as x approaches positive and negative infinity.
As x approaches negative infinity, the term \(9x^3\)dominates, resulting in f(x) becoming increasingly negative. As x approaches positive infinity, the term 9x^3 also dominates, causing f(x) to become increasingly positive. Therefore, we can conclude that the range of f(x) is (-∞, +∞), indicating that the function can take on any real value.
To verify these results, you can use a graphing utility or software to plot the function \(f(x) = 9x^3 + 4x^2 - 4\) and observe the shape of the graph. The graph will confirm that the function is defined for all real values of x and its range spans the entire real number line.
Learn more about function here:
https://brainly.com/question/11624077
#SPJ11
We test the hypotheses H0: μ = μ0 vs. Ha: μ ≠ μ0 based on SRS of size n from anormal population with unknown mean μ and known standard deviation σ. If wereject H0 when H0 is in fact true we commit a __________ error.a. Type I b. Type II c. Level α d. Type I error and Type II.
Answers
Option (A) Deviation from the normal distribution can also affect the likelihood of making a Type I error. If the population is not normally distributed, the assumptions of the test may not be met, which could lead to an increased likelihood of making a Type I error.
If we reject the null hypothesis (H0) when it is actually true, we commit a Type I error. This is also known as a false positive. A Type I error occurs when we conclude that there is a significant difference between the sample mean and the hypothesized population mean (μ0), when in fact there is not. The level of significance or alpha (α) is the probability of making a Type I error. It is typically set at 0.05 or 0.01.
It's important to note that a Type I error is related to the level of significance chosen for the test. The lower the level of significance, the less likely we are to make a Type I error. On the other hand, increasing the level of significance will increase the probability of making a Type I error.
Deviation from the normal distribution can also affect the likelihood of making a Type I error. If the population is not normally distributed, the assumptions of the test may not be met, which could lead to an increased likelihood of making a Type I error.
In conclusion, we need to be cautious when testing hypotheses and make sure we choose an appropriate level of significance, as well as ensuring that the assumptions of the test are met.
To know more about hypotheses visit :
https://brainly.com/question/29664127
#SPJ11
we would associate the term inferential statistics with which task?
Answers
Inferential statistics involves using sample data to make inferences, predictions, or generalizations about a larger population, providing valuable insights and conclusions based on statistical analysis.
The term "inferential statistics" is associated with the task of making inferences or drawing conclusions about a population based on sample data.
In other words, it involves using sample data to make generalizations or predictions about a larger population.
Inferential statistics is concerned with analyzing and interpreting data in a way that allows us to make inferences about the population from which the data is collected.
It goes beyond simply describing the sample and aims to make broader statements or predictions about the population as a whole.
This branch of statistics utilizes various techniques and methodologies to draw conclusions from the sample data, such as hypothesis testing, confidence intervals, and regression analysis.
These techniques involve making assumptions about the underlying population and using statistical tools to estimate parameters, test hypotheses, or predict outcomes.
The goal of inferential statistics is to provide insights into the larger population based on a representative sample.
It allows researchers and analysts to generalize their findings beyond the specific sample and make informed decisions or predictions about the population as a whole.
For similar question on population.
https://brainly.com/question/30396931
#SPJ8
the difference between hypothesis tests for two means with equal variances and with unequal variances is the:
Answers
The difference between hypothesis tests for two means with equal variances and with unequal variances lies in the assumption about the population variances.
When conducting a hypothesis test for two means with equal variances, the assumption is that the variances of the two populations from which the samples are drawn are equal. This is known as the equal variance assumption. In this case, a common pooled variance estimate is used to calculate the standard error of the difference in means.
On the other hand, when performing a hypothesis test for two means with unequal variances, there is no assumption of equal variances. The standard error of the difference in means is calculated separately for each sample, taking into account their respective variances. This approach, called the separate variances method, allows for more flexibility in situations where the population variances are not equal.
In summary, the difference between hypothesis tests for two means with equal variances and unequal variances is the assumption made about the population variances and the method used to calculate the standard error of the difference in means.
Know more about hypothesis tests here,
https://brainly.com/question/17099835
#SPJ11
Simplify the square root of 18

Answers
Answer:
18 has the square factor 9. 18 = 9 · 2. is now simplified.
So the Last one
Step-by-step explanation:
A bicycle wheel completes 20 cyc les in 5 min. (a) How many degrees has it completed? (b) How many radians has it completed?
Answers
The bicycle wheel has completed 7,200 degrees in 5 minutes. The wheel has completed 125.66 radians in 5 minutes.
(a) To determine the number of degrees the bicycle wheel has completed, we need to know the angle covered in one cycle. Since one cycle corresponds to a full revolution of 360 degrees, we can multiply the number of cycles by 360 to find the total number of degrees.
Number of degrees = 20 cycles * 360 degrees/cycle = 7,200 degrees
Therefore, the bicycle wheel has completed 7,200 degrees.
(b) To calculate the number of radians completed by the wheel, we need to convert degrees to radians. One radian is equal to π/180 degrees. We can use this conversion factor to find the total number of radians covered.
Number of radians = Number of degrees * (π/180)
Substituting the value of the number of degrees, we have:
Number of radians = 7,200 degrees * (π/180) ≈ 125.66 radians
Hence, the bicycle wheel has completed approximately 125.66 radians.
In summary, the bicycle wheel has completed 7,200 degrees and approximately 125.66 radians in 5 minutes.
Learn more about radians here:
brainly.com/question/27025090
#SPJ11
PLEASE HELP I NEED THE ANSWER TO BOTH QUESTIONS I GIVE BRAINLIEST

Answers
Answers: Angle ABE = 117 And DBE = 27
g etween two variables may be explained away by the presence of another variable that accounts for the original correlation. These relationships are known as
Answers
A spurious correlation is a correlation between two variables that appears to be causally linked but is actually due to the influence of a third variable that is not considered. The correct answer is spurious correlation.
Spurious correlations are correlations that exist between two variables, but they are not actually causally related to one another, despite the fact that they appear to be causally related at first glance. The relationship between two variables may be accounted for by a third variable that was previously overlooked or not considered, causing the original correlation to be explained away. Spurious correlations are commonly found in science and research, and they can lead to misleading results if not properly identified and accounted for. It is critical to account for all potential confounding variables in order to establish causal links between variables and avoid spurious correlations. Therefore, researchers must carefully consider all variables that might influence the relationship between two variables to avoid drawing inaccurate conclusions.
know more about spurious correlation
https://brainly.com/question/29361770
#SPJ11
Find the truth set of each predicate. (If your answer is an interval, enter it using interval notation; otherwise enter it using set-roster notation.) (a) Predicate: d
6
is an integer, domain: z (b) Predicate: d
6
is an integer, domain: z +
(c) Predicate: 1≤x 2
≤4, domain: R (d) Predicate: 1≤x 2
≤4, domain: z
Answers
(a) Predicate: d/6 is an integer, domain: Z
The truth set for this predicate is the set of integers that are divisible by 6. In set-roster notation, it can be written as:
{-12, -6, 0, 6, 12, ...}
(b) Predicate: d/6 is an integer, domain: Z+
The truth set for this predicate is the set of positive integers that are divisible by 6. In set-roster notation, it can be written as:
{6, 12, 18, 24, ...}
(c) Predicate: 1 ≤ x^2 ≤ 4, domain: R
The truth set for this predicate is the set of real numbers whose square lies between 1 and 4 (inclusive). In interval notation, it can be written as:
[-2, -1] ∪ [1, 2]
(d) Predicate: 1 ≤ x^2 ≤ 4, domain: Z
The truth set for this predicate is the set of integers whose square lies between 1 and 4 (inclusive). In set-roster notation, it can be written as:
{-2, -1, 1, 2}
Learn more about Integers here:
https://brainly.com/question/1768254
#SPJ11
Use the ungrouped data that you have been supplied with to complete the following: (a) Arrange the data into equal classes (b) Determine the frequency distribution (c) Draw the frequency histogram (d) Create a cumulative frequency table for the data (e) Draw the cumulative frequency graph (f) Use your graphs to determine if the data is normally distributed or not (9) Calculate: i. the mean and standard deviation ii. the median and mode iii. the upper and lower quartile values; iv. the inter-quartile range for the given data.
Answers
To analyze the given ungrouped data, we will perform several steps. First, we will arrange the data into equal classes.
Then, we will determine the frequency distribution, construct a frequency histogram, and create a cumulative frequency table and graph. Using these graphs, we can assess if the data is normally distributed. Finally, we will calculate the mean, standard deviation, median, mode, upper and lower quartile values, and the inter-quartile range for the given data.
(a) To arrange the data into equal classes, we need to determine the range of the data and choose an appropriate class width to divide the range into intervals.
(b) Once the data is grouped into classes, we can determine the frequency distribution by counting the number of data points that fall into each class.
(c) With the frequency distribution at hand, we can construct a frequency histogram by plotting the classes on the x-axis and the corresponding frequencies on the y-axis, using bars of equal width.
(d) To create a cumulative frequency table, we add up the frequencies from the lowest class to the highest class. This table displays the total frequency up to each class.
(e) The cumulative frequency graph is then plotted using the cumulative frequencies as the y-values and the corresponding class boundaries as the x-values. This graph shows the cumulative total of frequencies.
(f) By examining the frequency histogram and cumulative frequency graph, we can determine if the data is normally distributed. A bell-shaped histogram and a cumulative frequency graph that approximates a straight line indicate normal distribution.
(g) To calculate the mean, we sum up all the data points and divide by the total number of data points. The standard deviation measures the spread of the data around the mean.
(h) The median is the middle value when the data is arranged in ascending order. The mode represents the value(s) that appear most frequently in the data.
(i) The upper quartile is the median of the upper half of the data, while the lower quartile is the median of the lower half. The inter-quartile range is the difference between the upper quartile and the lower quartile, which measures the spread of the middle 50% of the data.
To learn more about range click here:
brainly.com/question/29204101
#SPJ11
The heights of 200 adults were recorded and divided into two categories.6' or overUnder 6Male1488Female2Which two-way frequency table correctly shows the marginal frequencies?6' or overUnder 6TotalMale1488100O A.Female298100Total16186200Total6' or overUnder 61488Male102B.
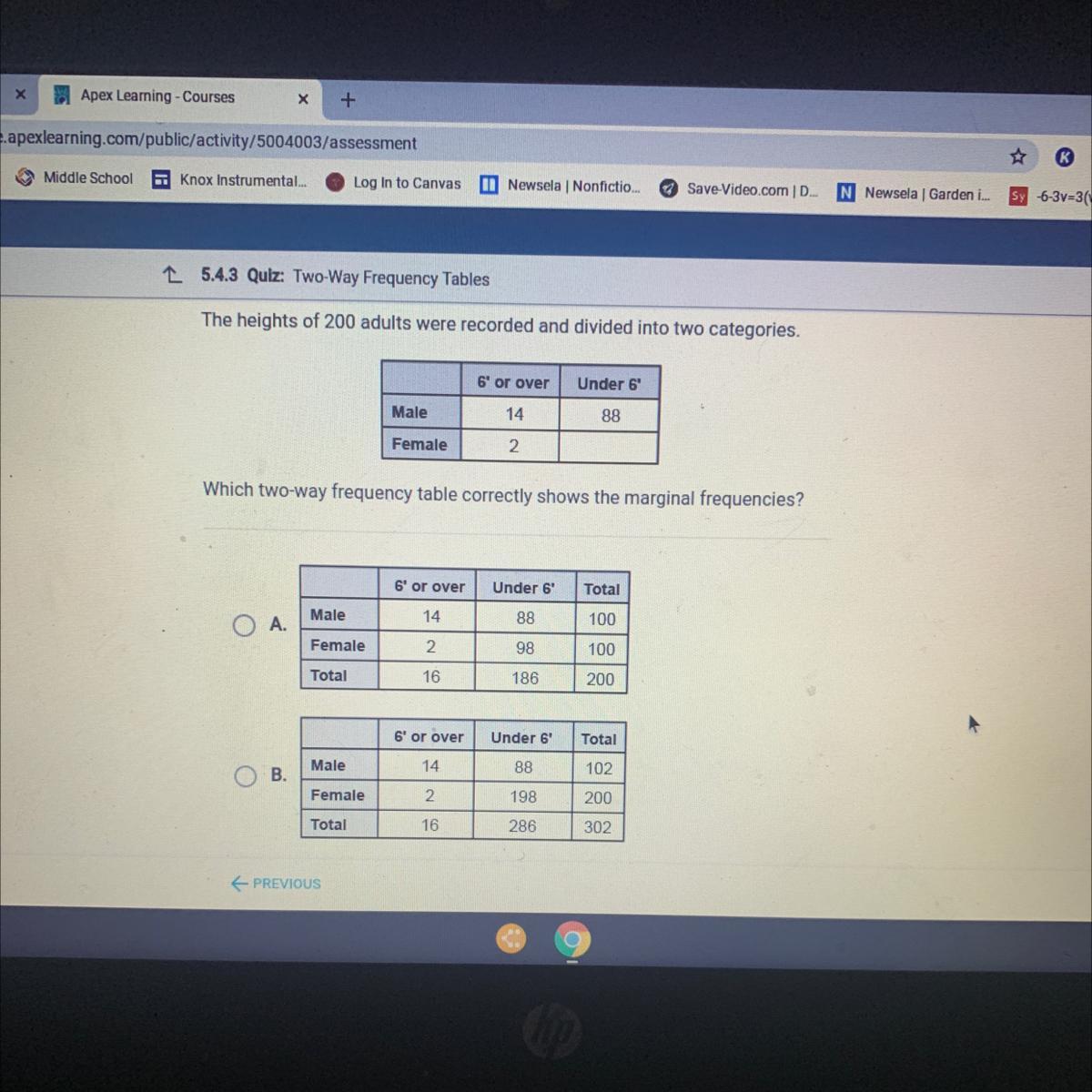
Answers
Answer:
6' or over under 6' Total
Male 14 88 102
Female 2 96 98
Total 16 184 200
Explanation:
The initial table is:
6' or over under 6'
Male 14 88
Female 2
Then, to complete the table, we need to subtract all these values from the total number of adults, so:
200 - 14 - 88 - 2 = 96
Therefore, there are 96 females under 6' and the complete table is:
6' or over under 6'
Male 14 88
Female 2 96
Now, we can find the marginal frequencies as follows:
6' or over under 6' Total
Male 14 88 14 + 88 = 102
Female 2 96 2 + 96 = 98
Total 14+2=16 88+96=184
Therefore, the final table is:
6' or over under 6' Total
Male 14 88 102
Female 2 96 98
Total 16 184 200
What is the answer to X^2 + 7=16
Answers
Answer:
Step-by-step explanation:
x^2+7=16
-7 -7
x^2=9
x=\(\sqrt{9\)
x=3
Determine the algebraic degree of the following (7,7)-function, where a is a primitive element of F27. Is it linear, affine, quadratic or cubic? Explain your answer. (5%)
F(x) = alpha ^ 49 * x ^ 37 + alpha ^ 52 * x ^ 28 + alpha ^ 81 * x ^ 13 + alpha ^ 26 * x ^ 9 + alpha ^ 31 * x
Answers
The highest exponent of x in F(x) is 37, which means the algebraic degree of the function is 37.
The function F(x) is a cubic function.
Here, we have,
given function is:
F(x) = α⁴⁹ * x³⁷ + α⁵² * x²⁸ + α⁸¹ * x¹³ + α²⁶ * x⁹ + α³¹ * x
To determine the algebraic degree of the given (7,7)-function F(x), we need to find the highest exponent of x in the function.
F(x) = α⁴⁹ * x³⁷ + α⁵² * x²⁸ + α⁸¹ * x¹³ + α²⁶ * x⁹ + α³¹ * x
The algebraic degree of a polynomial function corresponds to the highest exponent of the variable in the function.
Linear functions have an algebraic degree of 1, affine functions have an algebraic degree of 1 or 0, quadratic functions have an algebraic degree of 2, and cubic functions have an algebraic degree of 3.
so, we get,
The highest exponent of x in F(x) is 37, which means the algebraic degree of the function is 37.
Therefore, the function F(x) is a cubic function.
To learn more on function click:
brainly.com/question/21145944
#SPJ4
PLZ NEED HELP ASAP WILL GIVE BRAINLIEST

Answers
Answe quik tha 2nd one
Step-by-step explanation:
do it
A and B are two events. Let P(A) = 0.65, P (B) = 0.17, P(A|B) = 0.65 and P(B|4) = 0.17 Which statement is true?
1. A and B are not independent because P(A|B) + P(A) and P(B|4) + P(B).
2. A and B are not independent because P (A|B) + P(B) and P(B|4) + P(A)
3. A and B are independent because P (A|B) = P(A) and P(BIA) = P(B).
4. A and B are independent because P (A|B) = P(B) and P(B|A) = P(A).
Answers
Answer:
the statement that is true is: A and B are not independent because P(AIB) + P(B) is not equal to P(BIA) + P(A)
Step-by-step explanation:
ur welcome
pls answer. On a coordinate plane, a line with a 90-degree angle crosses the x-axis at (negative 4, 0), turns at (negative 1, 3), crosses the y-axis at (0, 2) and the x-axis at (2, 0). What is the range of the function on the graph? all real numbers all real numbers less than or equal to –1 all real numbers less than or equal to 3 all real numbers less than or equal to 0

Answers
Range: All real numbers greater than or equal to 3. The Option C.
What is the range of the function on the graph formed by the line?To find the range of the function, we need to determine the set of all possible y-values that the function takes.
Since the line crosses the y-axis at (0, 2), we know that the function's range includes the value 2. Also, since the line turns at (-1, 3), the function takes values greater than or equal to 3.
Therefore, the range of the function is all real numbers greater than or equal to 3.
Read more about Range
brainly.com/question/14209611
#SPJ1
Find the length of the line segment joining pair of points ( 4, -1) and (5, 5)

Answers
Answer:
b I believe I just take it
A company promises to release a new smartphone model every month.Each models battery life will be 3% longer than the previous models. If the current models battery life is 684.0 minutes , what will the latest models battery life be 7 months from now ?
Answers
Using an exponential function, it is found that the latest models battery life will be of 841 minutes 7 months from now.
What is an exponential function?An increasing exponential function is modeled by:
\(A(t) = A(0)(1 + r)^t\)
In which:
A(0) is the initial value.r is the decay rate, as a decimal.In this problem, considering that the current battery life is of 684 minutes, and it should increase by 3% each month, the equation for the battery life after t months is given by:
\(A(t) = 684(1.03)^t\)
Then, in 7 months, it will be given by:
\(A(7) = 684(1.03)^7 = 841\)
More can be learned about exponential functions at https://brainly.com/question/25537936
inverso aditivo de +3x
Answers
Answer:
inverso aditivo de +3x
Ok so wala ko kasabot nimo baah
From the top of a 70 meter high building, a l kilogram ball is thrown directly downward with an initial speed of 10 meters per second. If the ball reaches the ground with a speed of 30 meters per second, the energy lost to friction is most nearly
Answers
Estimated energy lost to friction if the ball hits the ground at a speed of thirty meters per second is most nearly 286 Joules.
Explain about the friction?The tiny bumps press against each other as two surfaces slide onto each other. A surface is subject to a force from friction that opposes the direction of the surface's motion. Use of lubricants can reduce friction.Non-conservative forces are distinguished by the fact that their work is influenced by the object's course of movement. Moreover, the non-conservative forces' work results in a change in the system's mechanical energy.Given data:
Mass of the ball M = 1 Kg,initial speed of ball u = 10 m/sHeight travelled by ball h = 70 mFinal Speed of ball v = 30 m/sLet Potential Energy be P.E
Let Kinetic Energy be K.E
Energy lost due to friction = Initial ( P.E + K.E) - Final ( P.E + K.E)
ΔE = mgh + 1/2 mu² - 1/2 mv²
ΔE = 1*9.8*70 + 1/2*1*10*10 - 1/2*1*30*30
On solving.
ΔE = 286 Joules
Thus, Estimated energy lost to friction if the ball hits the ground at a speed of thirty meters per second is most nearly 286 Joules.
Know more about the friction
https://brainly.com/question/24338873
#SPJ1
hi i’ll give brainliest if anyone answers this right

Answers
Answer:
48°
Step-by-step explanation:
pls mark me as brainlist
Over the interval [0, 2pi), what are the solutions to cos(2x) = cos(x)? Check all that apply.
It’s 1, 2, 4, 6

Answers
The solutions that satisfy Sin(2x) = Sin(x) are 0,π/3, π, 5π/3. The options that satisfy the condition are 1,2,4 and 6 as per the given interval.
What is meant by a trigonometric ratio?In mathematics, trigonometric functions (also known as circular functions, angle functions, or goniometric functions) are real functions that relate an angle of a right-angled triangle to ratios of two side lengths. They are widely used in all geophysical sciences, including navigation, solid mechanics, celestial mechanics, geodesy, and many others. They are among the simplest periodic functions, and as such, they are widely used for studying periodic phenomena using Fourier analysis.
Given,
The interval is [0, 2pi)
Sin(2x) = Sin(x)
By checking all the options,
1) Sin 2(0)=sin0
Sin0=Sin0
Therefore, option 1 is correct
2) Sin 2x= Sin x
2Sin x Cos x= Sin x
2 Cos x=1
Cos x=1/2
Cos x= Cos π/3
x=π/3
Therefore, option 2 is correct.
3) Sin2(2π/3) = Sin(2π/3)
Sin(4π/3)=Sin(2π/3)
Sin 240°=Sin 20°
-√3/2≠√3/2
Therefore, option 3 is wrong
4) Sin(2π)=Sinπ
2Sinπ Cosπ=Sinπ
2×0×(-1)=0
0=0
Therefore, option 4 is correct
5) Sin 2(4π/3)= Sin(4π/3)
Sin 480°=Sin 240°
2 Sin 240° Cos 240°= Sin 240°
2(-√3/2)(-1/2)= -√3/2
√3/2≠-√3/2
Therefore, option 5 is wrong
6) Sin 2(5π/3)= Sin(5π/3)
2 Sin(5π/3)Cos (5π/3)=Sin(5π/3)
Cos(5π/3)=1/2
1/2=1/2
Therefore, option 6 is correct.
Therefore, the solutions that satisfy Sin(2x) = Sin(x) are 1,2,4,6 options.
To know more about trigonometric ratios, visit;
https://brainly.com/question/25122825
#SPJ1
Identify the type of observational study (cross-sectional, retrospective, or prospective) described below. A research company uses a device to record the viewing habits of about 25002500 households, and the data collected todaytoday will be used to determinenbsp the proportion of households tuned to a particular newsnews program.. Which type of observational study is described in the problem statement?
Answers
Answer:
Cross Sectional
Step-by-step explanation:
A cross sectional is one in which an association is developed between a risk factor or an outcome.
In the given question the device is used to record the viewing habits of about 2500 households, and the data collected today will be used to determine the proportion of households tuned to a particular news program. There will be risk factor in today's research with the future developed program which will the outcome.
For example there are 20 students in my class who cannot write. So I develop a program to help them write. But the next year there may not be any student who would require such help.So there's a risk factor associated with the outcome.
Cross sectional results are recorded in a two ways table showing do's and don'ts.
how many terms of the series do we need to add in order to find the sum to the indicated accuracy? \sum_{n=1}^\infty\frac{(-1)^{n-1}}{ n^2 } , \quad {\rm error}\le 0.008.
Answers
We need to add at least 11 terms of the series to get a sum that is accurate to within 0.008.
To find the number of terms we need to add to get the sum of the series with an error of no more than 0.008, we will use the alternating series error bound theorem, which states that for an alternating series with decreasing terms, the error between the sum of the series and its partial sum is less than or equal to the absolute value of the next term in the series.
In this case, the terms are decreasing in absolute value and the series is alternating. Thus, the error of the partial sum Sn is given by:
|S - Sn| <= |aₙ ₊ ₁|,
where S is the sum of the series and a{n+1} is the next term after the nth term.
So, we need to find the smallest value of n such that |a{n+1}| is less than or equal to 0.008. We have:
aₙ ₊ ₁ = 1 / (aₙ ₊ ₁)²
so we want to solve the inequality:
1 / (aₙ ₊ ₁)² <= 0.008.
Taking the square root of both sides and solving for n, we get:
n >=√(1/0.008) - 1 = 10.95
Since n must be a whole number, we round up to n=11.
Therefore, we need to add at least 11 terms of the series to get a sum that is accurate to within 0.008.
Learn more about terms at https://brainly.com/question/28204215
#SPJ11