What is the solution to this equation? 1n(x + 6) - 1n(2x - 1) = 0
Answers
Answer:x=7 n=/0
Step-by-step explanation:
Related Questions
If a cheetah travels 50 miles per day, how many feet per hour does the cheetah travel?
HELP FAST
Answers
26400 is what they travel in feet in a day divide that by 24 and that should be your answer
Awnser this please i will give you 16

Answers
Answer:
Its EFBGCAHDI
Need help. How do you start?

Answers
Answer:
it is a right angle triangle therefore
h²=b²+p²
8²=4²+p²
64-16=p²
48=p²
under root 48 =p
6.928
so 6.93 is the answer
under which of the following conditions is it preferable to use stratified random sampling rather than simple random sampling?
Answers
Answer:
The population can be divided into strata so that the individuals in each stratum are as much alike as possible.
Step-by-step explanation:
In short, if you can group the population into subgroups and are interested in their sub properties, then use stratified random sampling. If not, and interested only in the entire population as a whole, then use simple random sampling.
Simple random sampling, as the name suggests, is simply sampling randomly from the population. It doesn't make any assumptions of sub-classifications about the given population and is only interested in sampling the population as a whole representative.
Stratified random sampling, as the name suggests, does sampling on strata( parts or subgroups divided in the population). The sampling then is done from each group proportionate to the group's size versus the population size.
One example is when you've got red, green and blue colored balls as the population and you want to sample the population based on colors, then the colored groups are strata and thus, the sampling will be done on subgroups and such type of sampling will be called as stratified random sampling.
Simple random sampling doesn't care about sub-properties in the population. It consider the population as whole and doesn't differentiate classes in the population, unlike stratified random sampling.
Learn more here:
https://brainly.com/question/4468092
Help please thanks! Keidbekdnsjsjsjsjsjs

Answers
Answer: where is the figure tot he right???
Step-by-step explanation:
The primary advantages of the average rate of return method are its ease of computation and the fact that: Question 19 options: it is especially useful to managers whose primary concern is liquidity there is less possibility of loss from changes in economic conditions and obsolescence when the commitment is short-term it emphasizes the amount of income earned over the life of the proposal rankings of proposals are necessary
Answers
The primary advantage of the average rate of return method is its ease of computation. Additionally, it emphasizes the amount of income earned over the life of the proposal.
The average rate of return method is a simple and straightforward method for evaluating investment proposals. It calculates the average annual income or return generated by an investment over its useful life. This method is advantageous because it is easy to calculate, requiring basic financial information such as initial investment and expected annual income.
Moreover, the average rate of return method focuses on the income earned over the life of the proposal, providing a comprehensive view of the investment's profitability. This is in contrast to other methods that may focus on specific time periods or cash flows. By considering the overall income, the average rate of return method helps in assessing the long-term financial viability of the investment.
To know more about average rate of return method, click here: brainly.com/question/17438238
#SPJ11
Which of the following statements is the most accurate about a binomial random variable?
A.It has a bell-shaped distribution.
B.It is a continuous random variable.
C.It counts the number of successes in a given number of trials.
D.It counts the number of successes in a specified time interval or region.
Answers
The most accurate statement about a binomial random variable is that it counts the number of successes in a given number of trials. This statement is represented by option C.
A binomial random variable is a discrete random variable that models the number of successes in a fixed number of independent Bernoulli trials. Each trial has two possible outcomes: success or failure. The probability of success remains constant across all trials, denoted by the parameter p. The number of trials is denoted by n.
The binomial distribution is characterized by its probability mass function (PMF), which calculates the probability of observing a specific number of successes in the given number of trials. The shape of the binomial distribution is not necessarily bell-shaped, as stated in option A, but rather exhibits a peaked or skewed distribution depending on the values of p and n.
Option B, stating that a binomial random variable is a continuous random variable, is incorrect. Binomial random variables are discrete, meaning they can only take on whole number values. Continuous random variables, on the other hand, can take on any value within a specified range.
Option D, stating that a binomial random variable counts the number of successes in a specified time interval or region, is not accurate. Binomial random variables are concerned with counting successes in a fixed number of trials, not specifically related to a time interval or region.
In summary, the most accurate statement is that a binomial random variable counts the number of successes in a given number of trials, making option C the correct choice.
Learn more about probability mass function here: https://brainly.com/question/30765833
#SPJ11
Hi can someone help me with these 3 questions. Thanks :)

Answers
Answer:
a) 45° cause tan = sin/cos and sin 45 and cos 45 both give square root 2/2
b) 120°
c) sin = -1/2 = -30° or 330° both are same
Use the trig circle which i have included in the answer to better understand trig angles
hope that answers your question
I want to let you know that each angle has sets of coordinates the left number is cos and right is sin. Ex) sin of 30 is 1/2 and cos of 30 is square root 3/2 In case you dont fully understand dont hesitate to comment.
good luck!!

7(-2x+4)=-4x
plz answer my question to get brainly tag
Answers
♥️♥️♥️♥️♥️♥️♥️♥️♥️♥️♥️♥️♥️♥️
\(7( - 2x + 4) = - 4x\)
\( - 14x + 28 = - 4x\)
Add sides 4x
\( 4x - 14x + 28 = 4x - 4x\)
\( - 10x + 28 = 0\)
Subtract sides 28
\( - 10x + 28 - 28 = - 28\)
\( - 10x = - 28\)
Negatives simplifies
\(10x = 28\)
Divided sides by 10
\( \frac{10}{10}x = \frac{28}{10} \\ \)
\(x = 2.8\)
♥️♥️♥️♥️♥️♥️♥️♥️♥️♥️♥️♥️♥️♥️
2. The function ln(x)2 is increasing. If we wish to estimate √ In (2) In(x) dx to within an accuracy of .01 using upper and lower sums for a uniform partition of the interval [1, e], so that S- S < 0.01, into how many subintervals must we partition [1, e]? (You may use the approximation e≈ 2.718.)
Answers
To estimate the integral √(ln(2)) ln(x) dx within an accuracy of 0.01 using upper and lower sums for a uniform partition of the interval [1, e], we need to divide the interval into at least n subintervals. The answer is obtained by finding the minimum value of n that satisfies the given accuracy condition.
We start by determining the interval [1, e], where e is approximately 2.718. The function ln(x)^2 is increasing, meaning that its values increase as x increases. To estimate the integral, we use upper and lower sums with a uniform partition. In this case, the width of each subinterval is (e - 1)/n, where n is the number of subintervals.
To find the minimum value of n that ensures the accuracy condition S - S < 0.01, we need to evaluate the difference between the upper sum (S) and the lower sum (S) for the given partition. The upper sum is the sum of the maximum values of the function within each subinterval, while the lower sum is the sum of the minimum values.
Since ln(x)^2 is increasing, the maximum value of ln(x)^2 within each subinterval occurs at the right endpoint. Therefore, the upper sum can be calculated as the sum of ln(e)^2, ln(e - (e - 1)/n)^2, ln(e - 2(e - 1)/n)^2, and so on, up to ln(e - (n - 1)(e - 1)/n)^2.
Similarly, the minimum value of ln(x)^2 within each subinterval occurs at the left endpoint. Therefore, the lower sum can be calculated as the sum of ln(1)^2, ln(1 + (e - 1)/n)^2, ln(1 + 2(e - 1)/n)^2, and so on, up to ln(1 + (n - 1)(e - 1)/n)^2.
We need to find the minimum value of n such that the difference between the upper sum and the lower sum is less than 0.01. This can be done by iteratively increasing the value of n until the condition is satisfied. Once the minimum value of n is determined, we have the required number of subintervals for the given accuracy.
Learn more about integral here : brainly.com/question/31059545
#SPJ11
20 applicants from a pool of 90 applications will be hired. How many ways are there to select the applicants who will be hired?
Answers
The ways are the \(C_{20} ^{90}\) which are we there to select the applicants who will be hired with the help of combination.
According to the statement
we have to find that the number of ways are there to select the applicants who will be hired.
So, For this purpose, we know that the
A combination is a mathematical technique that determines the number of possible arrangements in a collection of items where the order of the selection does not matter.
Here we use the combination.
And from the given information:
20 applicants from a pool of 90 applications will be hired.
And according to this the combination becomes:
\(C_{20} ^{90}\)
then solve it
\(C_{20} ^{90} = \frac{90!}{20! (70!)}\)
\(C_{20} ^{90} = \frac{90*89*88*87*86*85*84*83*82!}{20*19*18*17*16*15*14!}\)
Then after solve it
\(C_{20} ^{90} = \frac{89*11*87*43*14*83*82!}{19*14!}\)
Now open another factorial
\(C_{20} ^{90} = \frac{89*11*87*43*14*83*82*81*80*79*78*77*76*75*74*73*72*71}{19*14*13*12*11*10*9*8*7*6*5*4*3*2*1}\)
Now solve this then
\(C_{20} ^{90} = {89*11*87*43*83*82*79*15*74*73*71}\).
So, The ways are the \(C_{20} ^{90}\) which are we there to select the applicants who will be hired with the help of combination.
Learn more about combination here
https://brainly.com/question/11732255
#SPJ4
According to an article on yahoo!news, you should change your sheets every 7 days...at minimum. to investigate the sheet changing habits of adults, a random sample of 20 adults reported how often they change their sheets using an anonymous survey.
Answers
The sheet-changing habits of a sample of 20 adults were surveyed and analyzed to estimate the sheet-changing habits of the general population. The mean and standard deviation were calculated, and a 95% confidence interval was constructed.
First, we can calculate the mean of the sample to determine the average sheet-changing frequency among the adults surveyed. To do this, we add up the sheet-changing frequencies for each adult and divide by the total number of adults:
Mean sheet-changing frequency = (frequency for adult 1 + frequency for adult 2 + ... + frequency for adult 20)/20
= (7 + 14 + ... + 28)/20
= X/20
Next, we can calculate the standard deviation of the sample to determine the degree of variation in sheet-changing habits among the adults surveyed.
Sum of squares of differences = ∑(sheet-changing frequency - mean sheet-changing frequency)²
For each adult in the sample, we can calculate the difference between their sheet-changing frequency and the mean frequency:
Adult 1: 7 - X
Adult 2: 14 - X
.
.
.
Adult 20: 28 - X
The sum of squares of differences is then:
Sum of squares of differences \(= (7 - X)^2 + (14 - X)^2 + ... + (28 - X)^2\)
We can then divide the sum of squares by the degrees of freedom (20-1=19) and take the square root to calculate the standard deviation:
Standard deviation = √((sum of squares of differences)/(degrees of freedom))
= √((X)/19)
= Y
To calculate the confidence interval, we can use the following formula:
Confidence interval = mean ± (critical value * standard deviation/√(sample size))
The critical value can be obtained from a t-table based on the desired confidence level and degrees of freedom. For a 95% confidence interval with 19 degrees of freedom, the critical value is 2.093.
Plugging in the values for the mean, standard deviation, and critical value, we can calculate the 95% confidence interval for the population mean sheet-changing frequency:
Confidence interval = X ± (2.093 * Y/√20) = X ± Z
The confidence interval gives us an estimated range for the population mean sheet-changing frequency, with a 95% level of confidence. This can be useful in understanding the sheet-changing habits of the general adult population, based on the sample data collected.
To learn more about the standard deviation, visit:
brainly.com/question/23907081
#SPJ4
Complete the coordinate proof.
Given: A(1, 2), B(3, 3), C(1, -1), D(3, 0)
Prove: △AEB≅△DEC
(geometry) pls help !





Answers
Answer:
j RJ irjcirkcks he ed dew wh he x vhg
Step-by-step explanation:
jrjrirjcjrjifjrjfjjfwodoqldmfjrj
a sample consists of the following data: 7, 11, 12, 18, 20, 22, 43. Using the three standard deviation criterion, the last observation (x=43) would be considered an outlier
a. true
b. false
Answers
The statement "Using the three standard deviation criterion, the last observation (x=43) would be considered an outlier" is true.
Given data:
7, 11, 12, 18, 20, 22, 43.
To find out whether the last observation is an outlier or not, let's use the three standard deviation criterion.
That is, if a data value is more than three standard deviations from the mean, then it is considered an outlier.
The formula to find standard deviation is:
S.D = \sqrt{\frac{\sum_{i=1}^{N}(x_i-\bar{x})^2}{N-1}}
Where, N = sample size,
x = each value of the data set,
\bar{x} = mean of the data set
To find the mean of the given data set, add all the numbers and divide the sum by the number of terms:
Mean = $\frac{7+11+12+18+20+22+43}{7}$
= $\frac{133}{7}$
= 19
Now, calculate the standard deviation:
$(7-19)^2 + (11-19)^2 + (12-19)^2 + (18-19)^2 + (20-19)^2 + (22-19)^2 + (43-19)^2$= 1442S.D
= $\sqrt{\frac{1442}{7-1}}$
≈ 10.31
To determine whether the value of x = 43 is an outlier, we need to compare it with the mean and the standard deviation.
Therefore, compute the z-score for the last observation (x=43).Z-score = $\frac{x-\bar{x}}{S.D}$
= $\frac{43-19}{10.31}$
= 2.32
Since the absolute value of z-score > 3, the value of x = 43 is considered an outlier.
Therefore, the statement "Using the three standard deviation criterion, the last observation (x=43) would be considered an outlier" is true.
Learn more about Standard Deviation from the given link :
https://brainly.com/question/475676
#SPJ11
Let
Ф(u, v) = (3u + 9v, 9u + 9v). Use the Jacobian to determine the area of
Ф(R) for: (a)R = [0,91 × [0, 6]
(b)R = [2,20] × [1, 17]
(a)Area (Ф(R)) =
(b) Area (Ф(R)) =
Answers
a) Area (Ф(R)) = 5184 (b) Area (Ф(R)) = 25920
Let J be the Jacobian of Ф. We have J = det(DФ) = det([3 9; 9 9]) = -72.
(a) For R = [0,9] × [0,6], we have
Ф(R) = {(3u+9v,9u+9v) | 0 ≤ u ≤ 9, 0 ≤ v ≤ 6}.
The area of Ф(R) is given by the double integral over R of the Jacobian:
Area (Ф(R)) = ∬R |J| dudv
= ∫0^9 ∫0^6 72 dudv
= 5184.
Therefore, the area of Ф(R) is 5184.
(b) For R = [2,20] × [1,17], we have Ф(R) = {(3u+9v,9u+9v) | 2 ≤ u ≤ 20, 1 ≤ v ≤ 17}. The area of Ф(R) is given by the double integral over R of the Jacobian:
Area (Ф(R)) = ∬R |J| dudv = ∫2^20 ∫1^17 72 dudv = 25920.
Therefore, the area of Ф(R) is 25920.
To learn more about integral click here
brainly.com/question/18125359
#SPJ11
expert was wrong posting
again
Consider a prism whose base is a regular \( n \)-gon-that is, a regular polygon with \( n \) sides. How many vertices would such a prism have? How many faces? How many edges? You may want to start wit
Answers
If a prism's base is a regular \(n\)-gon, then the prism has 2 regular \(n\)-gon faces, n squares, 3n edges, and 2n vertices. This is because a prism has a top face, a bottom face, and n square faces.
1. If a prism's base is a regular \(n\)-gon, then it has \(n\) vertices on the base.
2. If the base has n vertices, then there will be n edges connecting those vertices.
3. The prism has two regular n-gon faces and n square faces. Therefore, it has 2n vertices and 3n edges.
4. A prism with base a regular n-gon has 2n + n = 3n faces, where 2n are the bases and n are the square faces. Therefore, it has n square faces.
If a prism has a regular polygon as its base with n sides, it will have n vertices, n edges, and n squares. A prism is a solid object that has a top face, a bottom face, and other flat faces that are usually parallelograms or rectangles.
The base is the shape that is repeated in the prism, and it can be any polygon. In this case, we're talking about a regular polygon, which is a polygon with all sides and angles equal in measure.
A regular polygon with n sides has n vertices. Therefore, a prism with a regular n-gon base has n vertices. The number of edges in a prism is found by counting the edges on the base and the edges that connect the corresponding vertices of the base.
So, a prism with a regular n-gon base has n edges on the base and n more edges that connect the corresponding vertices of the base, giving a total of 2n edges.The number of faces in a prism is the sum of the top and bottom faces and the number of lateral faces.
A prism with a regular n-gon base has two n-gon faces and n square faces. Therefore, the total number of faces is 2n + n = 3n faces.
Thus, we have that if a prism's base is a regular n-gon, then the prism has 2 regular n-gon faces, n squares, 3n edges, and 2n vertices.
To learn more about regular polygon
https://brainly.com/question/29722724
#SPJ11
Does anyone know the answer so this question

Answers
Step-by-step explanation:
f(3)= -2*3^2 +3 -5
= -2*9 +3 -5
= 16
Find the measure.........

Answers
Answer:
I believe that the proper answer you would be looking for is...
Step-by-step explanation:
the measure of angle 2 would make this a prime factor of the factor tree and than you would use the 3 which is also a prime factor to make sure that 132 is prime if it is not prime you can not find the measure of angle 2.
but actually its congurent to 132 so its 132
When analyzing the relationship in non-linear data as a linear association, when should the strategy of ignoring outliers be used?
If ignoring half of the data points allows the remaining data to be represented by a curved line.
If ignoring one or two data points allows the remaining data to be represented by a straight line.
If ignoring half of the data points allows the remaining data to be represented by a straight line.
If ignoring one or two data points allows the remaining data to be represented by a curved line.
Answers
Explanation:
An outlier is typically one or two points that differ greatly from the rest of the data. If ignoring these outliers contributes to the ability to identify non-linear data as a linear association, then a straight line should still be present regardless of these two points.
Hector purchased a used car and the graph below shows the number of miles on the car since he bought it. Which of these is a correct statement based on the graph

Answers
Answer:
the answer is C
Step-by-step explanation:
on the graph when the x axes is at 0 the y axes is already at 2 so he bought it without 2000 miles on it already
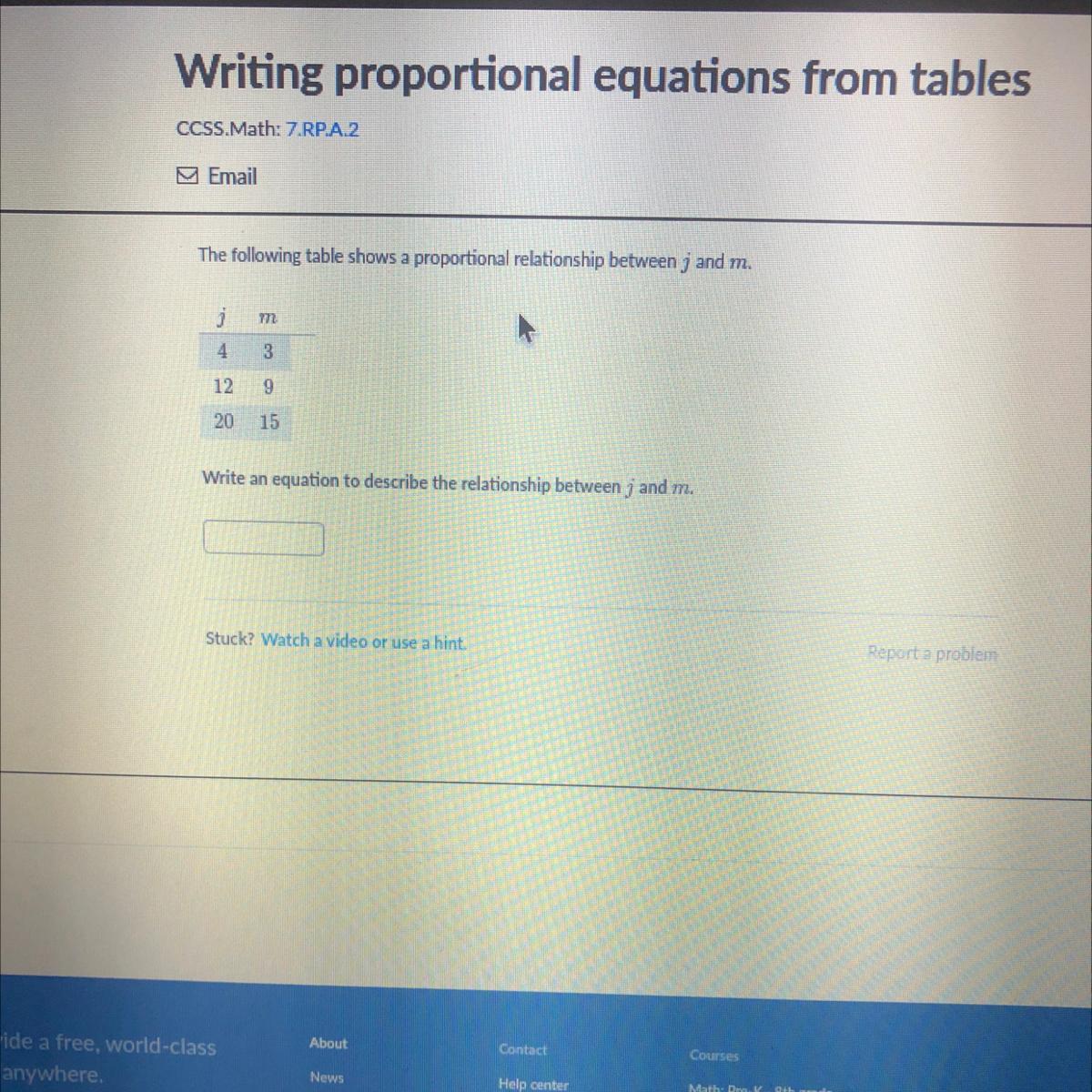
Writing proportional equations from tables
CCSS.Math: 7.RP.A.2
Email
The following table shows a proportional relationship between j and m?
j
m
4
3
12
9
20
15
Write an equation to describe the relationship between j and m.
Answers
Answer:
4+12+20=j
3+9+15=m
j(answer) + m(answer)
Step-by-step explanation:
what should you do if you are driving 65 mph in the far left lane of a highway and everyone else in the lane is going 70 mph and above?
Answers
So as mentioned in the condition we have to go on the same lane then have to increase out speed by 5mph or more to drive safely on the lane or else you can go to other lane where others speeds is same as or less than you speed.
You are technically in violation of the law. However, concurrently... You are a roadblock and will put other drivers in greater risk than you would by "flowing with the flow" if the average speed of traffic is 70 mph or more and you insist on driving at 65 mph.
Many vehicles are approaching you at 5 mph or more. A rear-end collision that may involve numerous cars might happen in the span of a split second of inattention.
The letter of the law and common sense are two different things.
If you're uncomfortable keeping up with the traffic flow... Take a different path. or else go speed up to go with others flow .
To know more about average speed click on link below:
https://brainly.com/question/9834403#
#SPJ4
g(a) = 2a - 1
hla) = 3a – 3
Find (g. h)(-4)
Answers
Step-by-step explanation:
(g. h)(-4) = g(4).h(4)
= [2(4)-1].[3(4)-1]
=7×11
=77
What is the common difference of the sequence below?
-7, -11, -15, -19, ...
a) d = 4
Go to station 3
Go to station 7
b) d = 5
|
c) d= -4
Go to station 5
d) d = -5
Go to station 9
Answers
Answer:83999955 because of the gravity
Step-by-step explanation:
What is the solution to –2|2.2x – 3.3| = –6.6?
x = –3
x = 3
x = –3 or x = 0
x = 0 or x = 3
Answers
Answer:
D
Step-by-step explanation:
the monthly utility bills in a city are normally distributed, with a mean of $100 and a standard deviation of $15. Find the probability that a randomly selected utility bill is (a) less than $68, (b) between $81 and $90, and (c) more than $120.
Answers
The probability that a randomly selected utility bill is,
a) P(X < 68) ≈ 0.016 or 1.6%
b) P(81 < X < 90) ≈ 0.1476 or 14.76%
c) P(X > 120) ≈ 0.0912 or 9.12%
To find the probability in each case, we can use the standard normal distribution by converting the given values into z-scores.
a) To find the probability that a randomly selected utility bill is less than $68, we need to find P(X < 68). First, we calculate the z-score using the formula z = (x - μ) / σ, where x is the value, μ is the mean, and σ is the standard deviation.
z = (68 - 100) / 15 = -2.1333
Using a standard normal distribution table or a calculator, we can find the corresponding cumulative probability for z = -2.1333, which is approximately 0.016. Therefore, the probability P(X < 68) is approximately 0.016 or 1.6%.
b) To find the probability that a randomly selected utility bill is between $81 and $90, we need to find P(81 < X < 90). We calculate the z-scores for both values:
z1 = (81 - 100) / 15 = -1.2667
z2 = (90 - 100) / 15 = -0.6667
Using the standard normal distribution table or a calculator, we find the cumulative probability for z1 and z2: P(z1) ≈ 0.1038 and P(z2) ≈ 0.2514. Then, we subtract P(z1) from P(z2) to find the probability between the two values:
P(81 < X < 90) ≈ P(z1 < Z < z2) ≈ P(z2) - P(z1) ≈ 0.2514 - 0.1038 ≈ 0.1476 or 14.76%.
c) To find the probability that a randomly selected utility bill is more than $120, we need to find P(X > 120). We calculate the z-score:
z = (120 - 100) / 15 = 1.3333
Using the standard normal distribution table or a calculator, we find the cumulative probability for z = 1.3333, which is approximately 0.9088. Since we want the probability of X to be greater than 120, we subtract this value from 1:
P(X > 120) ≈ 1 - P(z) ≈ 1 - 0.9088 ≈ 0.0912 or 9.12%.
Learn more about probability at
https://brainly.com/question/31828911
#SPJ4
Enter the number that belongs in
the green box.

Answers
Answer:
60°
Step-by-step explanation:
All triangles have internal angles that add up to 180°.
180° / 3 = 60° each.
Answer:
=56p explanation:
Step-by-step
Susie bought 4 pairs of pants. Her total bill, including tax was
$110.16. If each pair of pants cost $25.50 before tax was added,
what tax rate did Susie pay on the pants?
Answers
Answer:
($8.16 is the taxes) ($110 is how much she paid without taxes)
Step-by-step explanation:
Susie bought 4 pairs of pants. Her total bill, including tax was
$110.16. If each pair of pants cost $25.50 before tax was added,
what tax rate did Susie pay on the pants?
Susie buys 4 pairs of pants. And individually each pair costed $25.50. What I did was multiply 25.50 by 4, and I got 102. Now subtract the 110.16 and 102 and u get 8.16 which that's the taxes.
84192÷67÷2?por favor no tengo ni idea
Answers
Answer:
628.298507463
Step-by-step explanation:
Answer:
628.298507463
brainliest? XD
diana had 41 stickers she put them in 7 equal groups she put as many possible in each group she gave the leftover stickers to her sister how many stickers did diana give to her sister
Answers
6 number of stickers diana given to her sister.
What is Division?A division is a process of splitting a specific amount into equal parts.
Diana had 41 stickers and she put them in 7 equal groups. To find out how many stickers she put in each group, we can divide 41 by 7:
41 ÷ 7 = 5 with a remainder of 6
This means that Diana put 5 stickers in each of the 7 groups, and she had 6 stickers leftover.
She gave the leftover stickers to her sister, so she gave her sister 6 stickers.
Hence, 6 number of stickers diana given to her sister.
To learn more on Division click:
https://brainly.com/question/21416852
#SPJ1