
Answers
Answer:
Step-by-step explanation:
To tackle this problem, you start with the simplest function y = |x| (the absolute value of x). This is a function that turns any negative number into a positive number while positive numbers stay positive.
For example, if x = -1, you would get y = 1.
Or if you have a x = -10, you would get y = 10.
Now let's say you have a positive number x = 5, then you'd also get a positive number y = 5.
That's why the graph of y = |x| is a V shaped graph that has the vertex at (0,0) which opens upwards. (see the attached photo1)
Now let's find out what happens when we change the function of y = |x| into y = |x+1|.
What happens is that the graph of the old function gets shifted 1 unit to the left. Thus the new vertex will be moved to (-1,0). (see the attached photo2)
Now let's see what happens when we put a negative sign to the function so it becomes y = -|x+1|.
Putting a negative sign on front of the function is equivalent by multiplying the function by -1 which makes your old positive y values turn into negative y values. That is why you'll see the new graph to be flipped (reflected) via the x-axis. Which means the V will now open downwards. (see the attached photo3)
Now let's find out what happens when we subtract 5 to the function so it becomes y = -|x+1| - 5.
Subtracting 5 to the function shifts the graph 5 units downwards. Hence the new vertex will now be placed at (-1,-5). (see the attached photo4)
Therefore the answer is the 4th choice which is:
a V shaped graph with vertex at (-1,-5), which points down.
- Ginno Pineda




Related Questions
solve for x. Express your answer as a proper or improper fraction in simplest terms,
-1/2= 4/9x+5/6
x=
Answers
Answer: x=-3
Step-by-step explanation:
A line passes through the points (7,6) and (8,8) What is its equation in slope intercept form?
Answers
Answer:
y = 2x - 8
Step-by-step explanation:
y = 2x + b
8 = 2(8) + b
8 = 16 + b
-8 = b
check work:
6 = 2(7) - 8
6 = 14-8
6 = 6
it should be correct
Solve the following
5x20
Answers
Answer:
100
Step-by-step explanation:
1
20
X 5
100
in the diagram above <1=135 find the measure of <3
Answers
What must be done to categorical variables in order to use them in a regression analysis?
Choose one answer.
a. categorical coding
b. nothing
c. problem coding
d. dummy coding
Answers
d. Dummy coding. Categorical variables need to be converted into numerical variables to be used in regression analysis. Dummy coding involves creating binary variables for each category of the categorical variable.
For example, if the categorical variable is "color" with categories "red," "green," and "blue," dummy coding would involve creating three binary variables: "red" (0 or 1), "green" (0 or 1), and "blue" (0 or 1). These binary variables can then be used in the regression analysis. In conclusion, to use categorical variables in regression analysis, dummy coding is necessary.
In order to use categorical variables in a regression analysis, they must be converted into numerical values. This process is called dummy coding (also known as one-hot encoding). Dummy coding involves creating new binary variables (0 or 1) for each category of the categorical variable. This allows the regression model to incorporate the categorical data while maintaining its numerical nature.
To use categorical variables in a regression analysis, you must apply dummy coding to convert them into numerical values.
To know more about variables visit:
https://brainly.com/question/17344045
#SPJ11
an event that increases the probability that a response will be repeated is called _____.
Answers
The term that describes an event that increases the likelihood of a response being repeated is known as reinforcement.
Reinforcement can be defined as any consequence that strengthens or increases the probability of a behavior occurring again in the future. This can include positive reinforcement, which involves adding a desirable consequence after a behavior, or negative reinforcement, which involves removing an aversive consequence after a behavior. Both types of reinforcement have been shown to be effective in increasing the likelihood of a behavior being repeated.
Overall, understanding the concept of reinforcement is essential in the field of psychology, particularly in the areas of behaviorism and behavior modification. By providing positive consequences after desired behaviors, individuals can be motivated to continue engaging in those behaviors, which can lead to long-term positive changes. Reinforcement can also be used to shape new behaviors or replace unwanted behaviors with more desirable ones.
To know more about positive changes visit:-
https://brainly.com/question/15411632
#SPJ11
A circle is centered at D(-1, 3). The point G(-10, 1) is on the circle.
Where does the point J(-3, 12) lie?
Choose 1 answer:
A Inside the circle
B. On the circle
C. Outside the circle

Answers
i could be wrong but i think 12 is too far since (-10, 1) is on the circle
Compare the three data sets on the right: 11121314151617 111213- 151647 121314151617 Which data set has the greatest sample standard deviation? Dala set (iii) , because has more entries that are close Ine mean Data set (Ii) , because has more entries Ihat are farther avay from the mean Data set () because has [wo entrius that ar0 far away from tho moan; Which data set has the least sample standard deviatlon? Data set (iii) , because has more entries that are close Ine mean Data set (i), because has less entries that are farther away Irom the mean Data set (ii) . because has more entries Ihat are farther away from (he mean: (b) How are the data sets the same? How do they differ? rcan; modian and mode but have different standard doviabons: The three data sets have the same Samu standard deviations but have dilferent means The throo data sots have the same mean and modu but have diffaront medians standard deviabons.
Answers
The correct answer is as follows: a) The data set that has the greatest sample standard deviation is Data set (ii).
b) Data set (ii) has the largest mean and mode, but the smallest median and the largest standard deviation.
(a) The data set that has the greatest sample standard deviation is Data set (ii).
The sample standard deviation is a measure of the amount of variation or dispersion of a set of data values.
In this case, Data set (ii) has more entries that are farther away from the mean, which results in a larger standard deviation.
(b) The data sets are the same in terms of containing the same numbers (11, 12, 13, 14, 15, 16, and 17).
However, they differ in terms of the order in which these numbers are arranged.
In addition, they differ in terms of the mean, median, mode, and standard deviation.
For example, Data set (ii) has the largest mean and mode, but the smallest median and the largest standard deviation.
To learn more about standard deviation
https://brainly.com/question/475676
#SPJ11
What’s in between 10.3 and 12.1
Answers
Answer:
11.3
Step-by-step explanation:
Answer:
Step-by-step explanation:
10.4
Find the coordinates of B, C, and D given that AB=5 and BC = 10

Answers
Answer:
B = (3, -5)
D = (0, -1)
C = (3, 5)
Step-by-step explanation:
We want to find the coordinates of B, C, and D given that AB = 5 and BC = 10.
Because AB = 5 and BC = 10, we can find the slope of the line using the slope formula:
\(\displaystyle \begin{aligned} m & = \frac{\Delta y}{\Delta x} \\ \\ & = \frac{(10)}{(5)} \\ \\ & = 2 \end{aligned}\)
Point A(-2,-5) is on the line. Hence, the equation of the line is:
\(\displaystyle \begin{aligned} y-y_1 &= m(x-x_1) \\ \\& = y-(-5) = 2(x-(-2)) \\ \\ y + 5 & = 2x+4 \\ \\ y & = 2x-1 \end{aligned}\)
Because AB is 5, B is simply A shifted rightwards five units. Hence:
\(\displaystyle B = (-2+5, -5) = (3, -5)\)
At Point D, x = 0. Hence:
\(\displaystyle y = 2(0) -1 = -1\)
Thus, D is at (0, -1).
B and C are collinear. Hence, the x value of C is 3:
\(\displaystyle y = 3(2) - 1 = 5\)
Therefore, C is at (3, 5).
5. find an equation of the plane through the line of intersection of the planes and and perpendicular to the plane .
Answers
The equation of the plane through the line of intersection of the planes and and perpendicular to the plane is x - 2y + 15z - 51 = 0.
The line of intersection of the planes and can be found by setting the two equations equal to each other and solving for x, y, and z. Doing so gives:
3x - y + 2z = 1
2x + y - 3z = -4
Adding the two equations yields:
5x - z = -3
Solving for z, we get:
z = 5x + 3
Now we need to find a normal vector to the plane . The coefficients of x, y, and z in the equation of the plane give us the normal vector:
n = <1, 2, -3>
The dot product of the normal vector n and the vector parallel to the line of intersection gives us the direction of the plane we are looking for:
n . <5, 0, 1> = 1(5) + 2(0) + (-3)(1) = 2
Thus, the equation of the plane we are looking for is:
1(x - x0) + 2(y - y0) - 3(z - z0) = 0
where (x0, y0, z0) is a point on the line of intersection of the planes and . We can use the solution we found earlier to obtain:
z = 5x + 3
Substituting this into the equation of the plane gives:
x - 2y + 15z - 51 = 0
Thus, the equation of the plane through the line of intersection of the planes and and perpendicular to the plane is:
x - 2y + 15z - 51 = 0.
Learn more about line of intersection here
https://brainly.com/question/30655803
#SPJ11
The population of Lake Ronkonkoma, NY, is approximately 2 times 10 Superscript 4 Baseline people. The population of New York City, NY, is approximately 8 times 10 Superscript 6 Baseline people. Question How many times as great is the approximate population of New York City as the approximate population of Lake Ronkonkoma? Enter the answer in the box.
Answers
Answer:
The population of Lake Ronkonkoma is approximately 2 × 10^4 people, and the population of New York City is approximately 8 × 10^6 people. To find out how many times as great the population of New York City is compared to Lake Ronkonkoma, we need to divide the population of New York City by the population of Lake Ronkonkoma:
Population of New York City / Population of Lake Ronkonkoma = (8 × 10^6) / (2 × 10^4)
Simplifying the expression by canceling out the common factor of 10^4, we get:
Population of New York City / Population of Lake Ronkonkoma = (8 × 10^2) / 2
Dividing 8 by 2, we get:
Population of New York City / Population of Lake Ronkonkoma = 4
Therefore, the population of New York City is 4 times as great as the population of Lake Ronkonkoma.
(Please could you kindly mark my answer as brainliest and a follow to my account would be really helpful.)
The measure of the supplement of an angle is 25 degrees more than 7 times the measure of the angle. To the nearest hundredth, what is the measure of the angle?
Answers
Answer:
The measure of the angle is 19.38°.
Step-by-step explanation:
An angle is a supplement of another angle when its sum equals 180 degrees. In this case:
\(\alpha + \beta = 180^{\circ}\)
And according to the statement:
\(\beta = 7\cdot \alpha + 25^{\circ}\)
Where:
\(\alpha\) - Angle, measured in degrees.
\(\beta\) - Supplement, measured in degrees.
The following system of equations is formed:
\(\alpha + \beta = 180^{\circ}\)
\(7\cdot \alpha - \beta = -25^{\circ}\)
The solution of the system is \(\alpha \approx 19.38^{\circ}\) and \(\beta \approx 160.63^{\circ}\). And finally, the measure of the angle is 19.38°.
Using the formula A = l w, determine the area of a rectangle when l = 3.7 and w = 4. Group of answer choices A.) 4.1 B.) 7.7 C.) 12.7 D.) 14.8
Answers
Answer:
D 14.8
Step-by-step explanation:
A=L*W which means length times width. 3.7x4= 14.8
A friend of ours takes the bus five days per week to her job. The five waiting times until she can board the bus are a random sample from a uniform distribution on the interval from 0 to 10 min. Determine the pdf and then the expected value of the largest of the five waiting times.
Answers
The probability density function (pdf) of the largest of the five waiting times is given by: f(x) = 4/10^5 * x^4, where x is a real number between 0 and 10. The expected value of the largest of the five waiting times is 8.33 minutes.
The pdf of the largest of the five waiting times can be found by considering the order statistics of the waiting times. The order statistics are the values of the waiting times sorted from smallest to largest.
In this case, the order statistics are X1, X2, X3, X4, and X5. The largest of the five waiting times is X5.
The pdf of X5 can be found by considering the cumulative distribution function (cdf) of X5. The cdf of X5 is given by: F(x) = (x/10)^5
where x is a real number between 0 and 10. The pdf of X5 can be found by differentiating the cdf of X5. This gives: f(x) = 4/10^5 * x^4
The expected value of X5 can be found by integrating the pdf of X5 from 0 to 10. This gives: E[X5] = ∫_0^10 4/10^5 * x^4 dx = 8.33
Visit here to learn more about probability:
brainly.com/question/13604758
#SPJ11
How Solve the following questions (write all steps). Q1: Use the following data to find a recursive Nevill's method When interpdating table using Polynomial at x-4.1 f(x) X 36 1.16164956 3.8 080201036 4.0 0.30663842 4.2 035916618 -123926000. 4.4 Q2: Construct an approximation polynomial for the following data using Hermite method. 1 f(x) f'(x) x 1.2 2.572152 7.615964 1.3 3.60 2102 13-97514 1.4 5.797884 34.61546 1.5 14.101442 199.500 - Good Luck -
Answers
To find a recursive Nevill's method when interpolating a table using a polynomial at x = 4.1, we can use the following steps:
Step 1: Set up the given data in a table with two columns, one for f(x) and the other for x.
f(x) x
36 1.16164956
3.80201036 4.0
0.30663842 4.2
0.35916618 -123926000.4
Step 2: Begin by finding the first-order differences in the f(x) column. Subtract each successive value from the previous value.
Δf(x) x
-32.19798964 1.16164956
-3.49537194 4.0
-0.05247276 4.2
Step 3: Repeat the process of finding differences until we reach a single value in the Δf(x) column. Continue subtracting each successive value from the previous one.
Δ^2f(x) x
29.7026177 1.16164956
3.44289918 4.0
Step 4: Repeat Step 3 until we obtain a single value.
Δ^3f(x) x
-26.25971852 1.16164956
Step 5: Calculate the divided differences using the values obtained in the previous steps.
Divided Differences:
Df(x) x
36 1.16164956
-32.19798964 4.0
29.7026177 4.2
-26.25971852 -123926000.4
Step 6: Apply the recursive Nevill's method to find the interpolated value at x = 4.1 using the divided differences.
f(4.1) = 36 + (-32.19798964)(4.1 - 1.16164956) + (29.7026177)(4.1 - 1.16164956)(4.1 - 4.0) + (-26.25971852)(4.1 - 1.16164956)(4.1 - 4.0)(4.1 - 4.2)
Solving the above expression will give the interpolated value at x = 4.1.
Q2: To construct an approximation polynomial using the Hermite method, we follow these steps:
Step 1: Set up the given data in a table with three columns: f(x), f'(x), and x.
f(x) f'(x) x
2.572152 7.615964 1.2
3.602102 13.97514 1.3
5.797884 34.61546 1.4
14.101442 199.500 1.5
Step 2: Calculate the divided differences for the f(x) and f'(x) columns separately.
Divided Differences for f(x):
Df(x) \(D^2\)f(x) \(D^3\)f(x)
2.572152 0.51595 0.25838
Divided Differences for f'(x):
Df'(x) \(D^2\)f'(x)
7.615964 2.852176
Step 3: Apply the Hermite interpolation formula to construct the approximation polynomial.
Learn more about polynomial here:
https://brainly.com/question/11536910
#SPJ11
10(x+12)=15x solve for x with how ?
Answers
Answer:
x = 24
Step-by-step explanation:
10(x+12)=15x (Given)
10x + 120 = 15x (Distributive property of equality)
-5x = -120 (Subtraction property of equality)
x = 24 (Division property of equality)
Which system of inequalities is shown?
AY
O A. y>x
y> 2
OB. y
y<2
OC. y
y> 2
OD. y> x
y< 2
119
-5
S

Answers
The correct answer is option C.Which is the inequalities that show the graphs are y < x and y > 2.
What is a graph?A graph is the representation of the data on the vertical and horizontal coordinates so we can see the trend of the data.
The inequality which is shown in the figure is y < x and y > 2.We can see in the graph when you plot y > 2 then it will cover all the values greater than 2 in the graph.
Similarly, if we plot the inequality y < x on the graph it will cover all the values of y which are less than x and intersect at the point ( 2, 2).
Therefore the correct answer is option C.Which is the inequalities that show the graphs are y < x and y > 2. The graph is attached with the answer below.
To know more about graphs follow
https://brainly.com/question/25020119
#SPJ1
Please help!!! will give crown
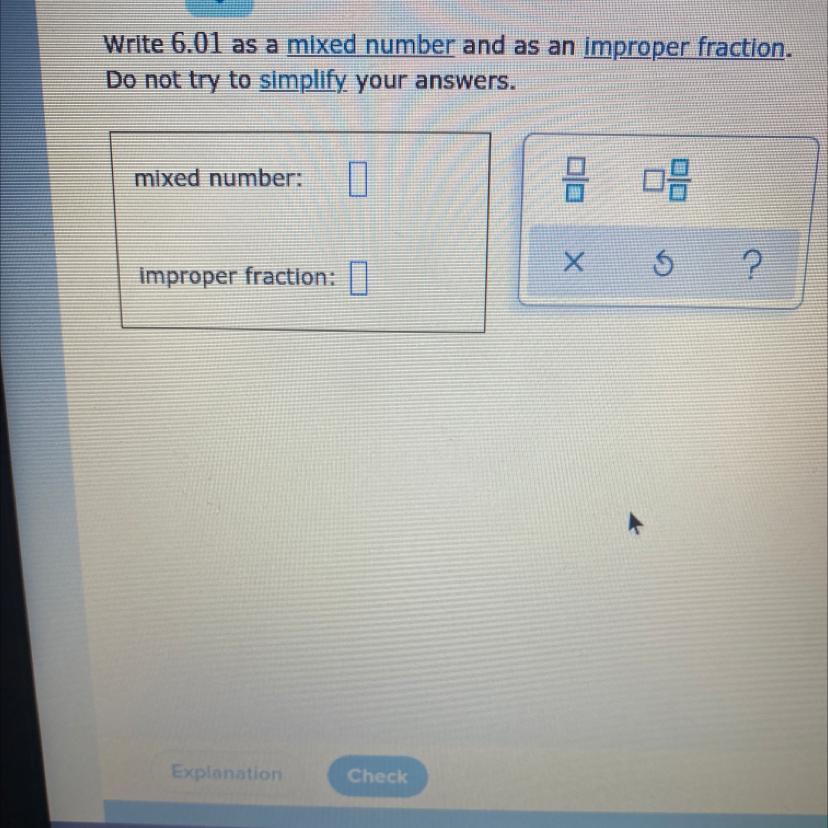
Answers
Answer:
Mixed number: 6 1/100
Improper Fraction: 601/100
Step-by-step explanation:
Hope this helps!
Answer:
Mixed number: \(6\frac{1}{100}\)
Improper fraction: \(\frac{601}{100}\)
Step-by-step explanation:
A mixed number is a fraction that contains an integer and fraction part. An improper fraction is a fraction where the numerator is larger than the denominator.
\(6.01\) can be written in the from \(\frac{601}{100}\). This is an improper fraction since the numerator is greater than the denominator.
The mixed number is \(6\frac{1}{100}\) since \(100\) goes into \(601\) six full times with \(1\) as the remainder.
Hope this helps :)
ind ∂w ∂v when u=0, v=0 if w=x2 y x, x=5u−5v 1, y=4u v−6.
Answers
The value of partial derivative ∂w/∂v when u=0, v=0 is 0.
To find ∂w/∂v when u=0, v=0, we can use the partial derivative formula:
∂w/∂v = (∂w/∂x) * (∂x/∂v) + (∂w/∂y) * (∂y/∂v)
First, let's find the partial derivatives of w with respect to x and y:
∂w/∂x = 2xy
∂w/∂y = x^2
Next, let's find the partial derivatives of x and y with respect to v:
∂x/∂v = 5(-1) = -5
∂y/∂v = 4u = 0 (since u=0)
Now we can plug in the values we have:
∂w/∂v = (2xy × ∂x/∂v) + (x^2 × ∂y/∂v)
At u=0, v=0, we have x=5u-5v=0 and y=4uv-6=0. Plugging in these values gives:
∂w/∂v = (2(0)(0)× -5) + ((0)^2×0) = 0
Click the below link, to learn more about the partial derivative formula:
https://brainly.com/question/30560681
#SPJ11
5/8(16d+24)=6(d-1)+1
Answers
To solve this equation, we need to distribute the 5/8 to the terms inside the parentheses. The solution to the equation is d = -5.
5/8(16d+24) = (5/8)(16d) + (5/8)(24)
Simplifying this expression, we get:
10d + 15 = 6d - 5
Now we can solve for d by isolating the variable on one side of the equation. First, we'll subtract 6d from both sides:
4d + 15 = -5
Next, we'll subtract 15 from both sides:
4d = -20
Finally, we'll divide both sides by 4:
d = -5
Therefore, the solution to the equation 5/8(16d+24)=6(d-1)+1 is d = -5.
5/8(16d+24)=6(d-1)+1. Here's a step-by-step explanation:
1. First, distribute 5/8 to both terms inside the parentheses on the left side:
(5/8 * 16d) + (5/8 * 24) = 6(d - 1) + 1
2. Simplify the terms on the left side:
(10d) + (15) = 6(d - 1) + 1
3. Next, distribute 6 to both terms inside the parentheses on the right side:
10d + 15 = 6d - 6 + 1
4. Simplify the terms on the right side:
10d + 15 = 6d - 5
5. Now, move all terms with 'd' to the left side and constants to the right side by subtracting 6d from both sides and subtracting 15 from both sides:
10d - 6d = -5 - 15
6. Simplify both sides of the equation:
4d = -20
7. Finally, solve for 'd' by dividing both sides by 4:
d = -5
So, the solution to the equation is d = -5.
Learn more about parentheses at: brainly.com/question/28146414
#SPJ11
Pumpkin pie p(t) write an expression
Answers
As mentioned in the previous answer, an expression for the amount of pumpkin pie, p(t), as a function of time, t, using an exponential function is:
p(t) = p_0 e^(-kt)
where:
p_0 is the initial amount of pumpkin pie at time t = 0k is the decay rate constant, which determines how quickly the pumpkin pie decays over timee is the mathematical constant equal to approximately 2.71828, the base of the natural logarithmTo illustrate the use of the exponential function, we can work through an example:
Suppose that the initial amount of pumpkin pie is 1000 grams, and the decay rate constant is k = 0.01 per minute. We can write the expression for the amount of pumpkin pie as:
p(t) = 1000 e^(-0.01t)
To evaluate the amount of pumpkin pie, p(t), after 30 minutes, we substitute t = 30 into the equation:
p(30) = 1000 e^(-0.01*30)
p(30) = 740.82 grams
This means that after 30 minutes, the amount of pumpkin pie remaining is approximately 740.82 grams.
\(\huge{\colorbox{black}{\textcolor{lime}{\textsf{\textbf{I\:hope\:this\:helps\:!}}}}}\)
\(\begin{align}\colorbox{black}{\textcolor{white}{\underline{\underline{\sf{Please\: mark\: as\: brillinest !}}}}}\end{align}\)
\(\textcolor{blue}{\small\texttt{If you have any further questions,}}\) \(\textcolor{blue}{\small{\texttt{feel free to ask!}}}\)
\({\bigstar{\underline{\boxed{\sf{\textbf{\color{red}{Sumit\:Roy}}}}}}}\\\)
What is the world record for digits of pi memorized?.
Answers
The world record for memorizing and reciting the most digits of pi is held by Rajveer Meena from India. He recited 50,000 decimal places of pi in 2020, which is the current recognized world record.
Pi (π) is a mathematical constant that represents the ratio of a circle's circumference to its diameter. It is an irrational number, which means it cannot be expressed as a finite decimal or a fraction. The decimal representation of pi is non-repeating and goes on indefinitely without a pattern. The value of pi is approximately 3.14159, but it is commonly approximated as 3.14 for simplicity in mathematical calculations. However, the exact value of pi has been calculated to trillions of digits using various computational methods. The quest to calculate more digits of pi continues to this day, and the computation of pi serves as a benchmark for testing the performance of supercomputers and computational algorithms. The current record for calculating the most digits of pi is trillions of digits, achieved through the use of powerful computers and advanced algorithms.
learn more about pi here:
https://brainly.com/question/31502190
#SPJ11
You must decide whether to buy new machinery to produce product X or to modify existing machinery. You believe the probability of a prosperous economy next year is 0.7. Prepare a decision tree and use it to calculate the expected value of the buy new option. The payoff table is provided below (+ for profits and - for losses).
When entering the answer, do not use the $ symbol. Do not enter the thousand separator. Enter up to 2 decimal places after the decimal point. For example, $6,525.35 must be entered as 6525.35
N1: Prosperity ($) N2: Recession ($)
A1 (Buy New) $1,035,332 $-150,000
A2(Modify) $823,625 $293,648
Answers
The expected value of the "Buy New" option is 724732.60.
Decision Tree:
To solve the given problem, the first step is to create a decision tree. The decision tree for the given problem is shown below:
Expected Value Calculation: The expected value of the "Buy New" option can be calculated using the following formula:
Expected Value = (Prob. of Prosperity * Payoff for Prosperity) + (Prob. of Recession * Payoff for Recession)
Substituting the given values in the above formula, we get:
Expected Value for "Buy New" = (0.7 * 1,035,332) + (0.3 * -150,000)Expected Value for "Buy New" = 724,732.60
Therefore, the expected value of the "Buy New" option is 724,732.60.
Conclusion:
To conclude, the decision tree is an effective tool used in decision making, especially when the consequences of different decisions are unclear. It helps individuals understand the costs and benefits of different choices and decide the best possible action based on their preferences and probabilities.
The expected value of the "Buy New" option is 724,732.60.
For more questions on expected value
https://brainly.com/question/14723169
#SPJ8
What is the absolute value of Point B labelled on the number line? A number line with point A at coordinate negative 2.2, point B at coordinate negative 1.6, and point C at coordinate 1.2. Drag and drop the answer into the box to match the correct statement. HELP PLEASE
Answers
Answer:
The absolute value of point B on the number line is 2.2.
Step-by-step explanation:
A number line is given with point A at coordinate negative 2.2, point B at coordinate negative 1.6, and point C at coordinate 1.2.
So, on the number line, all the points having negative value are on the left side of zero.
Position of the point A is -2.2,
Position of the point B is -1.6,
Position of the point C is -1.2.
The absolute value of any point on the number line is the distance of that point from zero.
So, the absolute value of point B on the number line is the distance of point B from zero which is |-2,2|=2.2.
Find the y-intercept of the parabola
y=x^2-6x+8
Type a coordinate point like (9,-5) with no spaces.
Show your work.
Answers
Vertex is at (3,−1) ; y-intercept is at (0,8) and x-intercepts are at (2,0) and (4, 0)
We know the equation of parabola in vertex form is y = a(x - h)² + k where vertex is at (h,k). Here y = x² - 6x + 8 = (x - 3)² - 9 + 8 = (x - 3)² - 1 ∴ Vertex is at (3,-1) we find y-intercept by putting x = 0 in the equation. So y = 0 - 0 + 8 = 8 and x-intercept by putting y=0 in the equation. So x² - 6x + 8 = 0 or (x - 4)(x - 2) = 0 or x = 4; x = 2 graph{x^2-6x+8 [-20, 20, -10, 10]}
A pencil is `120` millimeters long.
A marker is `9\%` longer than the pencil.
How long is the marker?
Answers
Given the length of the pencil, the length of the marker is 130.8 millimeters.
What are percentages?Percentage can be described as a fraction of an amount expressed as a number out of hundred. Percentages are represented %.
How long is the marker?Length of the marker = (1 + percentage) x length of the pencil
(1.09) x 120 = 130.8 millimeters
To learn more about percentages, please check: https://brainly.com/question/25764815
Which measure is equivalent to 65 kilograms?
659
6509
65000
65,0000
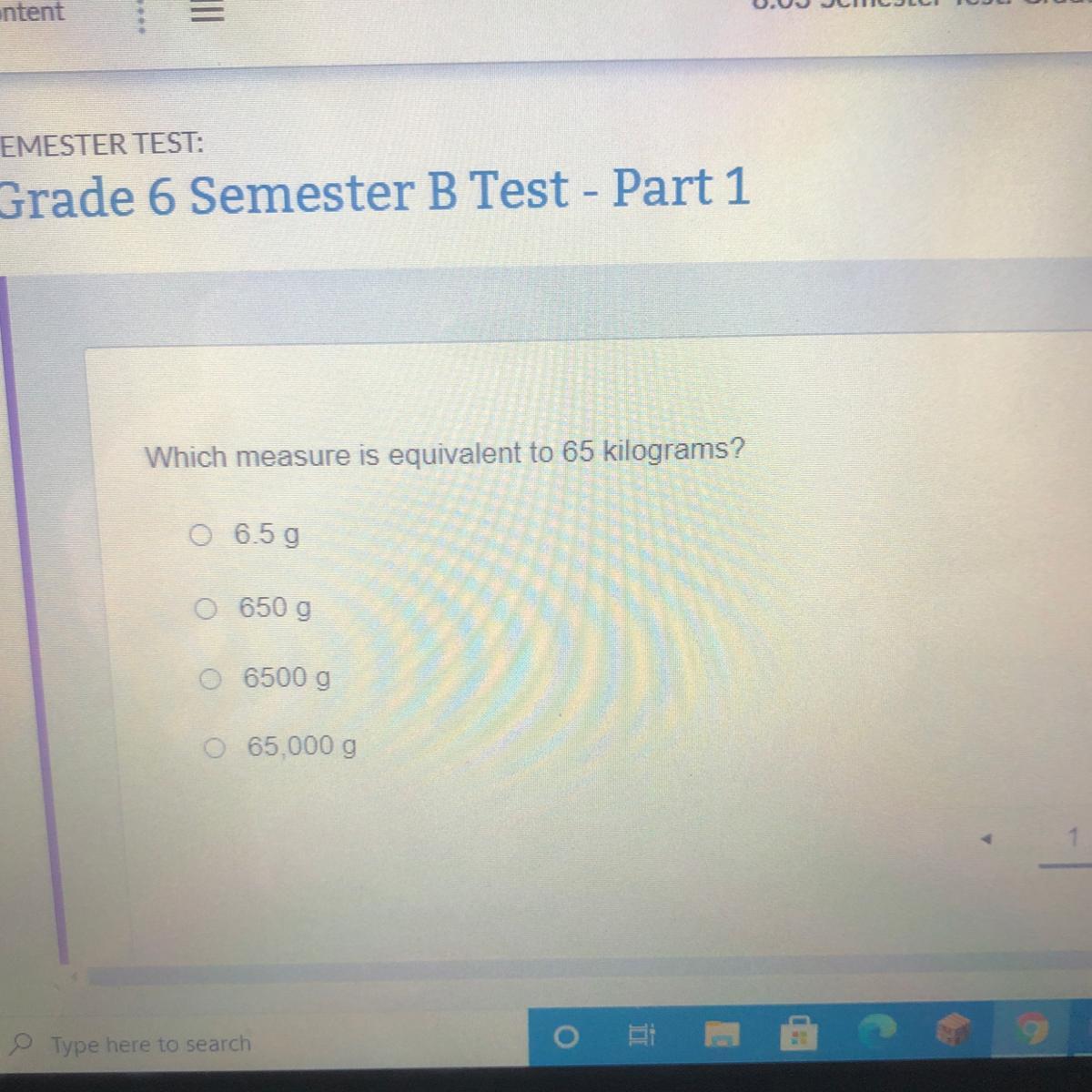
Answers
Answer:
65,000 grams
Step-by-step explanation:
Because 1000 grams is in 1 kilogram, you would multiply the 65 kilograms by 1,000 to convert it to grams.
So to convert 65 kilograms to grams you would do:
65 * 1,000 = 65,000 grams
HELP PLEASE
write down a formula for the nth term of these patterns. The first term is n = 1.
14 ,23 ,32 ,41, 50 = nth term = ?????????
-4, -11, -18, -25, -32 = nth term = ???????????
Answers
Answer:
1st one= n9+5
2nd one=n×-7+3
Which equations have a lower unit rate than the rate represented in this table?
х у
6 2
12 4
18 6
y=3/11x
y=2/5x
y=9/23x
y=4/13x
y=3/8x
Answers
Answer:
A and DStep-by-step explanation:
Find the unit rate of the data in the table:
y = kx2 = 6kk = 2/6k = 1/3The equation is:
y = 1/3xCompare this with the others:
A. 3/11 < 1/3 = 3/9 ⇒ yesB. 2/5 > 1/3 = 2/6 ⇒ noC. 9/23 > 1/3 = 9/27 ⇒ noD. 4/13 < 1/3 = 4/12 ⇒ yesE. 3/8 > 1/3 = 3/9 ⇒ noFind. rate
m=4-2/12-6m=2/6m=1/3Only first one and 4the one have lower unit rate
y=3/11xy=4/13x