The amount of time it takes a car to travel a certain distance is shown in the table. Choose the statement below that best describes the appearance of the graph of the relationship between time traveled and distance traveled. *
10 points
Captionless Image
A. A straight line that passes through the origin.
B. A curved line that passes through the origin.
C. A curved line that does not pass through the origin.
D. A straight line that does not pass through the origin.
Answers
Answer:
Step-by-step explanation:
-Distance traveled is always the magnitude of the displacement vector. ... A car travels around a circular track clockwise (as viewed from above) at constant speed. ... Select all of the position versus time graphs below that could possibly correspond to this ... A straight line with a slope of 10 m/s that passes though the origin
Related Questions
chauncey billups, a current shooting guard for the los angeles clippers, has a career free-throw percentage of 89.4%. suppose he shoots six free throws in tonight's game. what is the standard deviation of free throws that billups will make
Answers
The standard deviation of the number of free throws that Chauncey Billups will make in tonight's game is approximately 0.726.
To calculate the standard deviation of free throws that Chauncey Billups will make in tonight's game, we need to use the following formula:
Standard Deviation (σ) = √(n * p * (1 - p))
where n is the number of trials (free throws) and p is the probability of success (making a free throw).
In this case, n = 6 (as Billups shoots six free throws) and p = 0.894 (as his career free-throw percentage is 89.4%).
Substituting the values into the formula, we get:
Standard Deviation (σ) = √(6 * 0.894 * (1 - 0.894))
Calculating this expression, the standard deviation is approximately 0.726.
Therefore, the standard deviation of free throws that Chauncey Billups will make in tonight's game is approximately 0.726.
To learn more about probability visit:
https://brainly.com/question/23417919
#SPJ11
3 friends ordered 2 pizzas of 6 slices each and ate equal amounts, how many slices did each person eat?
A 1
B 2
C 3
D 4
Answers
Answer:
Option D, 4
Step-by-step explanation:
2 pizzas x 6 slices per pizza = 12 slices of pizza
12 slices of pizza divided by 3 friends eating equal slices = 4 slices per friend
Option D, 4, is your answer
while logistic regression and classification and regression trees (cart) have the same end goal, each model approaches the goal in a different way. discuss the differences in the two models. provide a specific example of a situation where employing a cart model would be preferable to a logistic regression model. explain what makes the cart model superior in your example.
Answers
Logistic regression models the probability of a binary outcome, while CART models segment data into categories. For example, CART is preferable when data has complex interactions, as it can partition data into multiple categories.
Logistic regression and classification and regression trees (CART) are two different machine learning models used for binary classification problems. Logistic regression models the probability of one class or the other based on a linear combination of input variables. This makes it useful for predicting a binary outcome, such as whether a customer will purchase a product or not. On the other hand, CART is a decision tree model that divides data into categories. It uses a tree-like structure to split the data into segments based on the input features. This makes it useful for dealing with data with complex interactions, as it can partition data into multiple categories. For example, a CART model would be preferable to a logistic regression model if there are multiple underlying factors that affect the binary outcome. In this case, a CART model could more accurately identify the categories that are associated with a particular outcome. Overall, CART models are superior for dealing with data with complex interactions, whereas logistic regression is better for simpler data.
Learn more about probability here
https://brainly.com/question/11234923
#SPJ4
the radius of a circle is 14.2 m. Find the circumference to the nearest tenth.
Answers
Answer:
C=89.2
Step-by-step explanation:
The formula of the circumference of a circle is C=2piR (or C=piD). Now, when calculating, plug in the numbers, giving you C=2pi14.2. Multiply everything, you get a super long irrational number; just round. You will get 89.2.
IV Find the citical points at which profit (pie) is maximized given the total revenue TR=4700−302 and Total CostTC =320/10,500 (2pts) 1. Compute Marginal Revenue and Marginal Cost 2. Equate MR=MC to find Q
∗
3. Verify that Q* is a relative maximum point 4. Compute the maximum profit level (pie) )
∗
by establishing (pie)* =9( (pie) (Q
∗
)
Answers
To find the critical points at which profit is maximized given the total revenue TR = 4700 - 302 and total cost TC = 320/10,500, we need to compute the marginal revenue and marginal cost, equate MR = MC to find the optimal quantity Q∗, verify if Q∗ is a relative maximum point, and compute the maximum profit level (π) by evaluating π∗ = 9(π(Q∗)).
Marginal Revenue (MR) is the derivative of the total revenue function with respect to quantity (Q). In this case, MR = dTR/dQ. By taking the derivative of TR = 4700 - 302 with respect to Q, we can find the expression for MR.
Marginal Cost (MC) is the derivative of the total cost function with respect to quantity (Q). In this case, MC = dTC/dQ. By taking the derivative of TC = 320/10,500 with respect to Q, we can find the expression for MC.
To find the optimal quantity Q∗, we equate MR and MC by setting MR = MC and solve for Q. This is because profit is maximized when MR equals MC.
Once we have found Q∗, we need to verify if it is a relative maximum point. This can be done by checking the second derivative of the profit function and determining if it is negative at Q∗. If the second derivative is negative, it confirms that Q∗ is a relative maximum point.
Finally, to compute the maximum profit level (π∗), we evaluate π(Q∗) by substituting Q∗ into the profit function. In this case, we can multiply the value of π(Q∗) by 9 to obtain the maximum profit level (π∗).
Learn more about relative maximum point here:
https://brainly.com/question/32310828
#SPJ11
A population P is growing at the rate of 9% each year and the initial population is P0. Find, as a multiple of P0, the rate of change of population at time t=T when the population has doubled from its initial time?
(Explain why, thank you!

Answers
The solution is Option B.
The rate of change of population at time t = T when the population has doubled from its initial time is P' = 2P₀ ln ( 1.09 )
What is an Equation?
Equations are mathematical statements with two algebraic expressions flanking the equals (=) sign on either side.
It demonstrates the equality of the relationship between the expressions printed on the left and right sides.
Coefficients, variables, operators, constants, terms, expressions, and the equal to sign are some of the components of an equation. The "=" sign and terms on both sides must always be present when writing an equation.
Given data ,
Let the equation be represented as A
Now , the value of A is
The formula for the population at time t is
P ( t ) = P₀ ( 1 + 9/100 )^t
P ( t ) = P₀ ( 1 + 0.09 )^t
P ( t ) = P₀ ( 1.09 )^t
Now , when population is doubled from the initial population ,
P ( t ) = 2P₀
Substituting the values in the equation , we get
2P₀ = P₀ ( 1.09 )^t
Taking logarithm on both sides of the equation , we get
log ( 2 ) = t x log ( 1.09 )
Divide by log ( 1.09 ) on both sides of the equation , we get
t = log ( 2 ) / log ( 1.09 )
To find the rate of change , take the derivative
P'( t ) = P₀ ( 1.09 )^t ln ( 1.09 )
Now , we find P'(log(2)/log(1.09))
So , the equation will be
P′ ( log( 2 ) / log( 1.09 ) ) = 2P₀ln( 1.09 )
Hence , the equation will be A = 2P₀ln( 1.09 )
To learn more about equations click :
https://brainly.com/question/19297665
#SPJ1
please hurry Solve: -23 = x - 23 *
Answers
Answer:
x = 0
Step-by-step explanation:
add 23 on both side and x equals zero
substitute x for 0, and the equation is still correct
Hope this helps and merry Christmas!!
What is the linear function equation that best fits the data set? 1) y = -2x + 5. 2) y = 2x + 5. 3) y = -1/2x + 5. 4) y = 1/2x - 5.

Answers
Without specific information about the data set, it is not possible to determine which equation is the best fit.
To determine the linear function equation that best fits the data set, we need more information about the data set itself. Without the data points or any other details, we cannot accurately determine which linear function equation is the best fit.
However, I can provide a general explanation of the four options:
y = -2x + 5: This is a linear equation with a negative slope of -2. It represents a line that decreases as x increases. The y-intercept is 5.
y = 2x + 5: This is a linear equation with a positive slope of 2. It represents a line that increases as x increases. The y-intercept is 5.
y = -1/2x + 5: This is a linear equation with a negative slope of -1/2. It represents a line that decreases at a slower rate as x increases. The y-intercept is 5.
y = 1/2x - 5: This is a linear equation with a positive slope of 1/2. It represents a line that increases at a slower rate as x increases. The y-intercept is -5.
Without specific information about the data set, it is not possible to determine which equation is the best fit. The best fit would depend on how well the equation aligns with the actual data points.
for such more question on data set
https://brainly.com/question/27358262
#SPJ8
the more variable the data, the _______ accurate the sample mean will be as an estimate of the population mean.
Answers
The more variable the data, the less accurate the sample mean will be as an estimate of the population mean. In statistical analysis, accuracy is important. Statistical analysis is a method of gathering and examining data to uncover useful information.
A sample mean is a numerical estimate that represents a data set's central tendency. The population mean, on the other hand, is a statistical measure that represents the mean value of the entire population. The difference between the two lies in the fact that sample mean is computed on a subset of the population whereas population mean is calculated for the entire population. If the variability of the sample data is large, the sample mean becomes less accurate as an estimate of the population mean.
As a result, the more variable the data, the less accurate the sample mean will be as an estimate of the population mean.Therefore, it is essential to examine the variability of the data in order to better estimate the population mean. The greater the variability in the data, the more difficult it becomes to identify the true population mean and the less accurate the sample mean is as an estimator of the population mean.
To know more about variable visit:
https://brainly.com/question/15078630
#SPJ11
the advantage of using the work sampling approach during a training needs assessment is that the assessor:
Answers
The advantage of using the work sampling approach during a training needs assessment is that the assessor : sees the work actually being done , the correct option is (d) .
In the question ,
it is asked about the advantage of using the work sampling approach during the training .
we know that Assessing need special skills and experience to be competent.
Generally, evaluators or assessors need to have interpersonal skills and communicates effectively with students.
So , During the training if the work sampling approach is used then assessor will see the work actually being done before hand .
Therefore , the advantage is that the will see the work actually being done .
The given question is incomplete , the complete question is
The advantage of using the work sampling approach during a training needs assessment is that the assessor:
(a) sees the results of each person doing the work
(b) does not get heavily involved with any job
(c) actually does each job
(d) sees the work actually being done
Learn more about Assessment here
https://brainly.com/question/14480467
#SPJ4
The _____ _____, denoted , is given by the formula _____, where x is the number of individuals with a specified characteristic in a sample of n individuals.
Answers
The sample proportion denoted \(\hat{p}\) is given by the formula \(\hat{p} = \frac{x}{n}\), where, x is the number of individuals with a specified characteristic in a sample of n individuals.
What is a sample proportion?A sample proportion can be defined as the proportion of individuals in a sample that have a specified characteristic or trait.
Mathematically, sample proportion can be calculated by using this formula:
\(\hat{p} = \frac{x}{n}\)
Where:
x is the number of individuals with a specified characteristic.n is the total number of individuals in a sample.Read more on sample proportion here: https://brainly.com/question/23838641
#SPJ1
at a certain grocery checkout counter, the average waiting time is 2.5 minutes. suppose the waiting times follow an exponential density function. (a) write the equation for the exponential distribution of waiting times. e(t) = graph the equation and locate the mean waiting time on the graph. webassign plot webassign plot webassign plot webassign plot (b) what is the likelihood that a customer waits less than 1 minutes to check out? (round your answer to one decimal place.) % (c) what is the probability of waiting between 4 and 6 minutes? (round your answer to one decimal place.) % (d) what is the probability of waiting more than 5 minutes to check out? (round your answer to one decimal place.) % need help? read it
Answers
a) The equation for the exponential distribution of waiting times is given by \(f(x) = \lambda e^{-\lambda x}\)
b) The probability of waiting less than 2 minutes to check out is 0.427
c) The probability of waiting between 4 and 6 minutes is 0.242
d) The probability of waiting more than 5 minutes to check out is 0.082
a. The equation for the exponential distribution of waiting times is given by:
\(f(x) = \lambda e^{-\lambda x}\)
where λ is the rate parameter of the distribution, and e is the natural logarithmic constant (approximately equal to 2.71828). The graph of the exponential distribution is a decreasing curve that starts at λ and approaches zero as x approaches infinity. The mean waiting time, denoted by E(X), is equal to 1/λ.
b. To find the probability that a customer waits less than 2 minutes to check out, we need to calculate the area under the exponential distribution curve between zero and 2 minutes. This can be expressed mathematically as:
P(X < 2) = \(\int_0^2 \lambda e^{-\lambda x} dx\)
Solving this integral yields:
P(X < 2) = 1 - \(e^{(-2\lambda)}\)
Substituting the given average waiting time of 2.5 minutes into the formula for the mean waiting time, we can calculate λ as:
E(X) = 1/λ
2.5 = 1/λ
λ = 0.4
Therefore, the probability of waiting less than 2 minutes to check out is:
P(X < 2) = 1 - \(e^{-2*0.4}\)
P(X < 2) ≈ 0.427
c. To find the probability of waiting between 2 and 4 minutes, we need to calculate the area under the exponential distribution curve between 2 and 4 minutes. This can be expressed mathematically as:
P(2 < X < 4) =\(\int_2^4 \lambda e^{(-\lambda x)} dx\)
Solving this integral yields:
P(2 < X < 4) = \(e^{(-2\lambda)} - e^{(-4\lambda)}\)
Substituting the value of λ obtained in part (b), we get:
P(2 < X < 4) = \(e^{(-20.4)} - e^{(-40.4)}\)
P(2 < X < 4) ≈ 0.242
d. To find the probability of waiting more than 5 minutes to check out, we need to calculate the area under the exponential distribution curve to the right of 5 minutes. This can be expressed mathematically as:
P(X > 5) = \(\int_5^{ \infty} \lambda e^{(-\lambda x)} dx\)
Solving this integral yields:
P(X > 5) = \(e^{(-5\lambda)}\)
Substituting the value of λ obtained in part (b), we get:
P(X > 5) = \(e^{(-5*0.4)}\)
P(X > 5) ≈ 0.082
To know more about probability here
https://brainly.com/question/11234923
#SPJ4
Find an equation of the line through (2,6) and parallel to y=2x+3
Answers
Step-by-step explanation:
We first Find the Slope of the line y=2x+3
The Slope Intercept Form of the equation of a given line is:
y=mx+c
where m is the Slope of that line, and c is the Y intercept.
For this line, the Slope is 2
So the Slope of the line PARALLEL to y=2x+3 will also be 2. And we are given that it passes through the point (2,6)
The Point-Slope form of the Equation of a Straight Line is:
(y−k)=m⋅(x−h)
m is the Slope of the Line
(h,k) are the co-ordinates of any point on that Line.
Here, we have been given the coordinates (h,k) of 1 point on that line as (2,6)
And the Slope m is 2
Substituting the values of h,k and m in the Point-Slope form, we get
(y−2)=(2)⋅(x−6)
(y−2)=2⋅(x-6)
y−2=2x -12
y=2x -12 +2
y=2x-10
The graph will look like
graph{y=2x -10 10 [10, -10, 5, - 5]}
A particle follows a trajectory or path described by x(t) = cos (t)and y(t) =
4sin2(t) . Sketch trajectory of this particle in the x-y plane.
Hint: Find a direct relationship between x and y by eliminating t between the x and y and
obtain y as a function of x, you can then sketch the graph on the x-y plane. You can also
try to choose values of t , then plot the (x, y) positions at various values of t.
Answers
The trajectory of the particle is obtained by eliminating the variable t between the equations x(t) = cos(t) and y(t) = 4sin²(t). Plotting various (x, y) positions for different values of t helps visualize the trajectory in the x-y plane.
To sketch the trajectory, we need to eliminate t between the equations x(t) = cos(t) and y(t) = 4sin²(t) to obtain y as a function of x. Let's begin by expressing sin²(t) in terms of cos(t):
sin²(t) = (1 - cos²(t))
Substituting this back into the equation for y(t):
y(t) = 4(1 - cos²(t))
Now, we can substitute x(t) = cos(t) into the equation for y(t):
y(x) = 4(1 - x²)
This expression gives us y as a function of x, allowing us to sketch the trajectory in the x-y plane. By choosing different values of t, we can calculate the corresponding x and y positions and plot them. As t varies, the particle will move along the trajectory described by the graph of y(x) = 4(1 - x²). The resulting sketch will provide a visual representation of the particle's path in the x-y plane.
Learn more about variable here:
https://brainly.com/question/29583350
#SPJ11
A small family-owned business sets aside $2,000 to be used for holiday bonuses. If there are 8 employees and the owners
give the same amount of money to each employee, how much does each employee receive?
A. O $25
B. O $200
C. © $250
D. O $1,992
E. O $16,000
Answers
Answer:
C
Step-by-step explanation:
If 2,000$ is to be given equally to 8 employees, dividing the 2,000$ by 8, gives you 250$. To confirm this answer, you would do 250$ × 8, which would equal the 2,000$.
You can also cut out answers D & E, due to them being too high, and answer A for leaving too much money left over. This leaves B & C, from there, just figure out which rounds up closer, or do the math.
PLEASE HELP ME WHAT IS. THIS X^2+5x+4
Answers
Answer: (x+1)(x+4) is the solution
Step-by-step explanation:
Use the sum-product pattern
Common factor from the two pairs
Rewrite in factored form
Answer:
(x+1)(x+4)
Step-by-step explanation:
x²+5x+4
x²+4x+x+4
x(x+4)+1(x+4)
(x+1)(x+4)
Which best define quantitative research? A. During quantitive research the researcher collects documents and numerical data to address theresearch. B. Quantitative research explains a phenomenon by means collecting numerical data throughsurveys and observations. C. Quantitative research is subjective in nature and address the research within the interpretivist paradigm D. Quantitative research explains a phenomenon by means of collecting numerical data throughsurveys and observation and analysing the data with statistical procedures.
Answers
The statement that best defines quantitative research is Quantitative research explains a phenomenon by means of collecting numerical data through surveys and observation and analyzing the data with statistical procedures. Option d is correct.
Quantitative research is a type of research that involves the collection of data that can be analyzed numerically. It involves the collection and analysis of data using mathematical and statistical tools. This type of research is often used in the social sciences, such as psychology, sociology, and economics.
Quantitative research is objective in nature and involves collecting data that can be quantified. This type of research is often used to answer research questions that can be measured numerically, such as the number of people who use a particular product or service.
Quantitative research is a systematic, empirical approach to research that involves the collection of numerical data. This data is then analyzed using statistical procedures to draw conclusions about the research question or hypothesis being tested.
Therefore, d is correct.
Learn more about quantitative research https://brainly.com/question/30362816
#SPJ11
27) Suppose the price elasticity of supply for shampoo is 20. If the price of shampoo increases by 0.7%, what would we expect to happen to the quantity of shampoo supplied?
a) Increase by 27%
b) Increase by 14%)
e) Increase by 13%
d) Decrease by 13%
28)
e) Decrease by 27%
If pasta is a Giffen good, then....
a) pasta is also a normal good.
b) pasta is also a luxury good.
e) an decrease in the price of pasta will increase the quantity demanded. d) an increase in the price of pasta will increase the quantity demanded. e) pasta must make up a small portion of consumers' total expenditures.
20)
An inferior good in which the income effect dominates the substitution effect is called....
a) a normal good.
b) a luxury good.
30)
a) a Giffon good.
d) a mass-produced good.
e) a favored good.
The cross elasticity of demand measures the responsiveness of the quantity demanded of a particular good to changes in the prices of
a) its complements but not its substitutes.
b) Its substitutes but not ita complements.
c) its substitutes and its complements.
d) neither its substitutes nor its complements. e) None of the above..
Answers
In question 27, the price elasticity of supply for shampoo is given as 20, and the price of shampoo increases by 0.7%. The expected change in the quantity of shampoo supplied can be determined using the concept of price elasticity of supply. However, the specific percentage change in quantity supplied is not provided, so a precise answer cannot be given based on the given information.
In question 20, an inferior good in which the income effect dominates the substitution effect is referred to as a Giffen good. It is not classified as a normal good, luxury good, mass-produced good, or favored good.
In question 30, the cross elasticity of demand measures the responsiveness of the quantity demanded of a particular good to changes in the prices of its substitutes and complements. The correct answer is that the cross elasticity of demand measures the responsiveness to changes in both substitutes and complements.
In question 27, without the specific percentage change in quantity supplied, we cannot determine the exact outcome based on the given information. The price elasticity of supply of 20 suggests that the quantity supplied is highly responsive to changes in price, but the specific percentage change in quantity supplied cannot be calculated without additional data.
In question 28, the relationship between pasta being a Giffen good and other characteristics is not specified. While pasta being a Giffen good indicates that the quantity demanded increases as the price increases, it does not imply whether pasta is a normal good, luxury good, or how price changes affect quantity demanded.
To learn more about mass-produced good: -
What kind of function is f(x)?
A. Exponential
B. Logarithmic
C. Rational
D. Polynomial
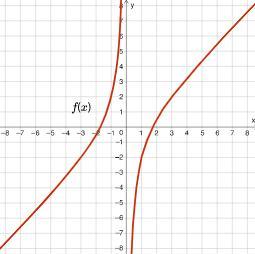
Answers
How do you write 2 more thank the difference of a number and 6 ?
Answers
Answer:
x=5
Step-by-step explanation:
so we know the final number is 6 so lets look at the rest of the question:
"twice the difference" so we are going to double the difference of two numbers, one we don't know (x) and the other is 2, so lets put this together and solve:
2(x-2)=6, x-2=3, x=5
7-23+8=6
How do you do this
Answers
7-23=(-16)
(-16)+8=(-8)
The answer should be (-8), if this is a true or false question its false.
Write the Pythagorean Equation (Pythagoras Formula).
Answers
Let's graph a right triangle to make it easier to understand
Where a and b are the legs and c is the hypotenuse.
So, the equation will be
\(c^2=a^2+b^2\)
. Show that the failure rate h(t) of the hypoexponential distribution has the property lim h(t) = min{lambda1,lambda2)
Answers
To show that the failure rate h(t) of the hypoexponential distribution has the property lim h(t) = min{λ₁, λ₂}, where λ₁ and λ₂ are the failure rates of the exponential components, we need to analyze the behavior of the failure rate as t approaches infinity.
The hypoexponential distribution is a mixture of exponential distributions with different failure rates. Let's assume we have two exponential components with failure rates λ₁ and λ₂, where λ₁ > λ₂.
The failure rate h(t) at time t is defined as the instantaneous rate at which failures occur given that the system has survived up to time t. It is calculated as the ratio of the probability density function (pdf) to the survival function.
The pdf of the hypoexponential distribution is given by:
\(f(t) = a_1e^(-a_1t) + a_2e^(-a_2t)\)
The survival function S(t) is given by:
S(t) = 1 - F(t)
where F(t) is the cumulative distribution function (CDF), which can be calculated as:
F(t) = 1 - S(t) = ∫[0 to t] f(u) du
To find the failure rate h(t), we take the derivative of the CDF with respect to time:
h(t) = d/dt [1 - S(t)] = d/dt [F(t)] = f(t)
Now, let's calculate the limit as t approaches infinity:
lim h(t) as t approaches infinity = lim f(t) as t approaches infinity
For t approaching infinity, the exponential terms \(e^(-a_1t) and e^(-a_2t)\)will tend to zero, as the exponential functions decay rapidly. Thus, only the term \(a_1e^(-a_1t)\)will dominate, and the failure rate becomes:
lim h(t) as t approaches infinity = lim \(a_1e^(-a_1t)\)as t approaches infinity
Since \(e^(-a_1t)\) approaches zero as t approaches infinity, the failure rate becomes:
lim h(t) as t approaches infinity = \(a_1\)
Therefore, the failure rate of the hypoexponential distribution approaches min{a₁, a₂} as t approaches infinity. This property holds regardless of the specific values of a₁ and a₂.
Learn more about statistics here:
https://brainly.com/question/29765147
#SPJ11
Find the missing angels
X=??

Answers
Answer:
x = 55°
Step-by-step explanation:
Since 35° + x° would be a right angle then you would subtract 35° from 90°
So x = 55°
Hope this helped :)
Please consider Brainliest :)
The graph represents the distribution of the lengths of play times, in minutes, for songs played by a radio station over one hour.
A graph shows the horizontal axis numbered 2.6 to x. The vertical axis is unnumbered. The graph shows an upward trend from 2.8 to 3.4 then a downward trend from 3.4 to 4.
Which statement is true about the songs played during the one-hour interval?
Most of the songs were between 3 minutes and 3.8 minutes long.
Most of the songs were 3.4 minutes long.
Most of the songs were less than 3.2 minutes long.
Most of the songs were more than 3.6 minutes long.
Answers
The correct statement is Most of the songs were between 3 minutes and 3.8 minutes long.
Based on the given information from the graph, we can determine the following:
The graph shows an upward trend from 2.8 to 3.4 on the horizontal axis.
Then, there is a downward trend from 3.4 to 4 on the horizontal axis.
From this, we can conclude that most of the songs played during the one-hour interval were between 3 minutes and 3.8 minutes long. This is because the upward trend indicates an increase in length from 2.8 to 3.4, and the subsequent downward trend suggests a decrease in length from 3.4 to 4.
Therefore, the correct statement is:
Most of the songs were between 3 minutes and 3.8 minutes long.
for such more question on minutes
https://brainly.com/question/25279049
#SPJ8
Answer:
A
Step-by-step explanation:
the transformation rule (x,y) - (0.95x, 0.95y) (x,y) - (0.95x, 0.95y) would ?

Answers
We can see that since the values that multiply each component (x & y) are less than an unit, the transformation rule would be a reduction.
Big Time Movers charges an initial fee of $24.50, plus $12.75 an hour for their moving services. On holidays, they charge 2.5 times their regular total amount. If they made $188.75 on a job on New Year’s Day, how many hours did they work?
This equation represents the data:
2.5(12.75x + 24.50) = 188.75
Big Time Movers worked ________ hours on New Year’s Day.
Answers
Big time movers worked 4 hours on New Year’s Day.
Show your work:
2.5 (12.75x +24.50) = 188.75
31.875x + 61.25 = 188.75
31.875x = 188.75 - 61.25
31.875x = 127.50
X = 127.50 / 31.875
X = 4....... 4 hours
Answer:
4 hours
Step-by-step explanation:
I did it on edg2020. Hope this helps
Drag the expressions to the correct functions. Not all expressions will be used.
Consider the functions fand g.
= 4x² + 1
g(x) =
Perform the function compositions:
x² - 3
Answers
The function composition exists an operation " ∘ " that brings two functions f and g, and has a function h = g ∘ f such that h(x) = g(f(x)).
Let the functions be f(x) = 4x² + 1 and g(x) = x² - 3
The correct answer is (f o g)(x) = 4x⁴ - 96x + 37 and
(g o f)(x) = 16x⁴ + 8x² - 2.
What is composition function?The function composition exists an operation " ∘ " that brings two functions f and g, and has a function h = g ∘ f such that h(x) = g(f(x)). In this operation, the function g exists used for the outcome of applying the function f to x.
Given:
f(x) = 4x² + 1 and g(x) = x² - 3
a) (f o g)(x) = f[g(x)]
f[g(x)] = 4(x² - 3)² + 1
substitute the value of g(x) in the above equation, and we get
= 4(x⁴ - 24x + 9) + 1
simplifying the above equation
= 4x⁴ - 96x + 36 + 1
= 4x⁴ - 96x + 37
(f o g)(x) = 4x⁴ - 96x + 37
b) (g o f)(x) = g[f(x)]
substitute the value of g(x) in the above equation, and we get
g[f(x)] = (4x² + 1)²- 3
= 16x⁴ + 8x² + 1 - 3
simplifying the above equation
= 16x⁴ + 8x² - 2
(g o f)(x) = 16x⁴ + 8x² - 2.
Therefore, the correct answer is (f o g)(x) = 4x⁴ - 96x + 37 and
(g o f)(x) = 16x⁴ + 8x² - 2.
To learn more about the function refer to:
https://brainly.com/question/26709985
#SPJ9
-3 Let M = (1 Find ₁ and ₂ such that M² + c₁M + c₂I2 = 0, where I₂ is the identity 2 x 2 matrix and 0 is the zero matrix of appropriate dimension. C1 = C2 =
Answers
The value of c₁ = -1 and c₂ = 0 satisfy the equation M² + c₁M + c₂I₂ = 0.
To find the values of c₁ and c₂ such that the equation M² + c₁M + c₂I₂ = 0 holds, we need to solve for them.
Given that M = 1, we can substitute this value into the equation:
(1)² + c₁(1) + c₂I₂ = 0
1 + c₁ + c₂I₂ = 0
Since I₂ is the identity matrix of size 2x2, it can be written as:
I₂ = [[1, 0], [0, 1]]
1 + c₁ + c₂[[1, 0], [0, 1]] = 0
This equation needs to hold for any matrix M, which means that the coefficients of each element must be zero.
Therefore, we have the following equations:
1 + c₁ = 0 (for the (1,1) element)
c₂ = 0 (for the (1,2) and (2,1) elements)
1 + c₁ = 0 (for the (2,2) element)
Solving these equations:
1 + c₁ = 0
c₁ = -1
c₂ = 0
Therefore, c₁ = -1 and c₂ = 0 satisfy the equation M² + c₁M + c₂I₂ = 0.
Learn more about Matrix here:
https://brainly.com/question/17329018
#SPJ4
Dividir 254 en tres partes tales que la segundasea el triplo de la primera y 40 unidades mayor que la tercera
Answers
Responder:
x = 40
y = 120
z = 80
Explicación paso a paso:
Número dividido = 240
Las 3 partes:
x, y, z
y = 3x
Z = 3x - 40
x + y + z = 240
x + 3x + 3x - 40 = 240
7x - 40 = 240
7x = 240 + 40
7x = 280
x = 280/7
x = 40
y = 3 (40)
y = 120
z = 3x - 40
z = 3 (40) - 40
z = 120 - 40
z = 80