Suppose a mouse is placed in the maze at the right. if each desicion about direction is made at random, create a simulation to determine the probability that the mouse will find its way out before coming to a dead end or going out in the opening.
Answers
The probability of the mouse finding its way out before reaching a dead end or going out in the opening can be estimated by dividing the number of successful outcomes by the total number of trials in the sample.
To create a simulation to determine the probability that the mouse will find its way out before coming to a dead end or going out in the opening, we can follow these steps:
Create a model of the maze in a programming language such as Python.Define the starting position of the mouse as the position on the right side of the maze.Define the exit position of the maze as the position on the left side of the maze.Randomly choose a direction for the mouse to move in (up, down, left or right).Check if the chosen direction leads to a dead end or out of the maze. If it does, return a failure outcome.If the chosen direction leads to a viable path, move the mouse to that position and repeat steps 4-6 until the mouse either reaches the exit or gets stuck in a dead end.Repeat steps 2-6 multiple times to generate a sufficient sample size.Calculate the proportion of successful outcomes (i.e. the mouse finding its way out before reaching a dead end or going out in the opening) from the generated sample.The probability of the mouse finding its way out before reaching a dead end or going out in the opening can be estimated by dividing the number of successful outcomes by the total number of trials in the sample. This simulation approach can help us understand the probability of success in a random maze environment, and also explore the impact of various factors such as maze complexity, size and starting position of the mouse on the outcome.
To know more about simulation, refer to the link below:
https://brainly.com/question/28564990#
#SPJ11
Related Questions
the number of toy cars that ray has is a multiple of . when he loses two of them, the number of cars that he has left is a multiple of . if is a positive even integer less than , then how many possible values are there for ?
Answers
we need to find the positive even integers less than k that satisfy the condition nx divided by x leaves a remainder of 2.
To solve this problem, we need to use the information given and work step by step. Let's break it down:
1. The number of toy cars that Ray has is a multiple of x. This means the number of cars can be represented as nx, where n is a positive integer.
2. When Ray loses two cars, the number of cars he has left is a multiple of x. This means (nx - 2) is also a multiple of x.
3. If x is a positive even integer less than k, we need to find the possible values for x.
Now, let's analyze the conditions:
Condition 1: nx - 2 is a multiple of x.
To satisfy this condition, nx - 2 should be divisible by x without a remainder. This means nx divided by x should leave a remainder of 2.
Condition 2: x is a positive even integer less than k.
Since x is even, it can be represented as 2m, where m is a positive integer. We can rewrite the condition as 2m < k.
To find the possible values for x, we need to find the positive even integers less than k that satisfy the condition nx divided by x leaves a remainder of 2. The number of possible values for x depends on the value of k. However, without knowing the value of k, we cannot determine the exact number of possible values for x.
To know more about remainder visit:
brainly.com/question/29019179
#SPJ11
Consider the following statements. A. There exists an FA that accepts the nonregular language {a n
b n+1
where n 3
1}. B. The nonregular language {a n
b n
where n 3
0} can be written as the regular expression a ⋆
b ⋆
. C. The language accepted by an FA can be a nonregular language. D. The reductio ad absurdum approach can be used to prove that a language is not regular. Which one of the following correctly identifies true statements about nonregular languages? 1. Only D is true. 2. All the statements are true. 3. Only A, B, and C are true. 4. None of the statements is true.
Answers
The true statements about nonregular languages are as follows:Option 3. Only A, B, and C are true.
The statement A says that there exists an FA that accepts the nonregular language {a^n b^n+1 where n ≥ 3}. It is a true statement. Because the language {a^n b^n+1 where n ≥ 3} is not a regular language. It can be proved by using the pumping lemma. Hence the statement A is true.
The statement B says that the nonregular language {a^n b^n where n ≥ 3} can be written as the regular expression a*b*. This statement is false because the language {a^n b^n where n ≥ 3} is not a regular language and it can not be written as the regular expression a*b*. Hence statement B is false.
The statement C says that the language accepted by an FA can be a nonregular language. It is a true statement. Because there exists a nonregular language that can be accepted by an FA. For example, the language {a^n b^n where n ≥ 0} is not a regular language. But it can be accepted by an FA. Hence statement C is true.
The statement D says that the reductio ad absurdum approach can be used to prove that a language is not regular. It is a true statement. Because the reductio ad absurdum approach is one of the methods to prove that a language is not regular. Hence statement D is true.
Therefore, the true statements about nonregular languages are A, C, and D. Hence option 3 is correct.
To know more about nonregular languages refer here :
https://brainly.com/question/15288866#
#SPJ11
what is the condition for the first dark fringe through a single slit of width w?
Answers
The condition for the first dark fringe through a single slit of width w is when the path difference between the light waves at the edges of the slit equals a half wavelength= (λ/2).
This can be expressed mathematically as:
w * sin(θ) = (m + 1/2) * λ, where m = 0 for the first dark fringe, w is the slit width, θ is the angle of the dark fringe from the central maximum, and λ is the wavelength of light.
When light passes through a single slit, it diffracts and creates an interference pattern with alternating bright and dark fringes on a screen. The dark fringes occur when light waves from the edges of the slit interfere destructively, which means their path difference must be an odd multiple of half a wavelength (λ/2).
For the first dark fringe, we set m = 0 in the equation:
w * sin(θ) = (0 + 1/2) * λ
So, the condition for the first dark fringe is:
w * sin(θ) = λ/2
Hence, The condition for the first dark fringe through a single slit of width w is when the path difference between the light waves at the edges of the slit equals a half wavelength (λ/2). This can be represented by the equation w * sin(θ) = λ/2.
learn more about first dark fringe click here:
https://brainly.com/question/27548790
#SPJ11
A car travels 30 km in 5.5 hours and 400 km in 5.5 hours find the average speed of the car during the entire journey
Answers
Answer:
This is your answer

Answer: 39.09 km per hour average
Step-by-step explanation:
add total distance and divide by total time
(30+400)/(5.5+5.5)
430/11=39.0909
A rectangle with a move from a right triangle to create the shaded region show but showing
below find the area of the shaded region we should include the correct unit for your answer
Answers
The area of the shaded region will be 8 square unit as per the given figure.
The rectangle has dimensions 2 x 4, so its area is:
Area of rectangle = length x width = 2 x 4 = 8 square units
The triangle has dimensions 4 x 8, so its area is:
Area of triangle = (1/2) x base x height = (1/2) x 4 x 8 = 16 square units
To find the area of the shaded region, we need to subtract the area of the triangle from the area of the rectangle.
Area of shaded region = Area of the triangle - Area of rectangle
Area of shaded region = 16-8
Area of shaded region = 8
The area of the shaded region will be 8 square units.
Learn more about Area here:
https://brainly.com/question/27683633
#SPJ1
Complete question:

in the standard curve for nitrophenol generated for use in this experiment, what is reported on the x-axis?
Answers
In the standard curve for nitrophenol generated for use in this experiment, the nitrophenol concentration is reported on the x - axis.
What is standard curve?
A calibration curve, sometimes referred to as a standard curve, is a common technique used in analytical chemistry to compare an unknown sample to a group of standard samples with known chemical concentrations.
In order to calculate the nitrophenol concentration in mole/ml based on absorbance readings, the standard curve is drawn.
Based on the optical density, or OD410, or absorbance at 410 nm, this standard curve of absorbance is used to calculate the quantity of nitrophenol.
Therefore, the nitrophenol concentration is displayed on the x axis of the standard curve.
To know more about the standard curve, click on the link
https://brainly.com/question/13445467
#SPJ4
he ratio of yes votes to no votes was to . if there were no votes, what was the total number of votes?
Answers
The given ratio of yes votes to no votes is 3:4
Then,
The ratio of yes votes: to no votes = 3:4
Yes votes = 2721,
Now,
2721/3 = 907
907 × 4 = 3628.
Hence, there were 3628 no votes.
To calculate the ratio, use this formula:
Ratios equate two numbers, usually by dividing them. If you are comparing one data point (x) to any other data point (y), your formula would be x/y. This means you are dividing information x by information y.
For example, if A is 50 and B is 100, your ratio will be 50/100 the ratio will be 1:2.
Learn more about ratios:
brainly.com/question/2328454
#SPJ4
A binomial experiment with probability of success p=0.63 and n=11 trials is conducted. What is the probability that the experiment results in 10 or more successes? Do not round your intermediate computations, and round your answer to three decimal places (if necessary consulta list of formes.)
Answers
To find the probability of getting 10 or more successes in a binomial experiment with p = 0.63 and n = 11 trials, we can use the cumulative probability function.
P(X ≥ 10) = 1 - P(X < 10)
Using a binomial probability formula, we can calculate the probability of getting exactly k successes:
P(X = k) = C(n, k) * p^k * (1 - p)^(n - k)
where C(n, k) represents the binomial coefficient.
Let's calculate the probability for each value from 0 to 9 and subtract it from 1 to get the probability of 10 or more successes:
P(X < 10) = P(X = 0) + P(X = 1) + P(X = 2) + ... + P(X = 9)
P(X < 10) = Σ[C(11, k) * p^k * (1 - p)^(11 - k)] for k = 0 to 9
Using this formula, we can calculate the probability:
P(X < 10) ≈ 0.121
Therefore, the probability of getting 10 or more successes in the binomial experiment is:
P(X ≥ 10) ≈ 1 - P(X < 10) ≈ 1 - 0.121 ≈ 0.879
Rounding to three decimal places, the probability is approximately 0.879.
Learn more about Probability here -:brainly.com/question/13604758
#SPJ11
Analysis of variance is used to test for equality of several population? means. standard deviations. proportions. variances.
Answers
Analysis of variance is used to test for equality of several population means.
ANOVA could also be utilized to predict the dependent variable of even more with around 2 categories and seems to be compared to the general population extra influential throughout this circumstance.
Throughout addition, ANOVA variants typically include covariates that encourage somebody to manipulate numerically for confounding factors as well as to recognize interactions wherein the factor progressives the implications of some other factor.
ANOVA (Analysis of Variance) was developed by Ronald Fisher.
ANOVA means the Analysis of Variance, is collection of statistical models & linked estimation processes, like variation among & between groups. It is used in analyzing differences among various means.
Therefore, Analysis of variance is used to test for equality of several population means.
Learn more about the ANOVA here:
https://brainly.com/question/23638404
#SPJ4
Find the missing side. Round to the nearest tenth.
15
32°
X
Answers
T/F: if the slope (b) of ŷ is positive, then the correlation coefficient (r) must also be positive.
Answers
True. The correlation coefficient (r) must also be positive, indicating a strong positive linear relationship between the two variables.
The correlation coefficient (r) measures the strength and direction of the linear relationship between two variables. It ranges from -1 to 1, where a value of -1 indicates a perfectly negative linear relationship, a value of 1 indicates a perfectly positive linear relationship, and a value of 0 indicates no linear relationship. If the slope (b) of ŷ is positive, it means that as the independent variable increases, the dependent variable also increases.
In addition to the above explanation, it is important to note that while a positive slope (b) of ŷ indicates a positive linear relationship between two variables, it does not necessarily mean that the correlation coefficient (r) will always be positive. For example, if there is a weak positive linear relationship between two variables, the correlation coefficient (r) may still be positive but not as strong as if there was a strong positive linear relationship. Similarly, there may be situations where the correlation coefficient (r) is positive but the slope (b) of ŷ is not positive, such as in a curvilinear relationship where the relationship between the two variables is not linear.
To know more about correlation coefficient visit :-
https://brainly.com/question/29978658
#SPJ11
Please help me on my question It’s all one question

Answers
It is given that:
\(f(x)=\frac{2}{x};g(x)=3x+12\)1) f(g(x)) will be:
\(f(g(x))=\frac{2}{g(x)}=\frac{2}{3x+12}\)2)The domain will be all real numbers except x=-4.
\(\text{Domain of f(g(x))=(-}\infty,-4)\cup(-4,\infty)\)3)g(f(x)) will be:
\(\begin{gathered} g(f(x))=3f(x)+12 \\ =3(\frac{2}{x})+12 \\ =\frac{6+12x}{x} \end{gathered}\)4) The domain of g(f(x)) is:
\((-\infty,0)\cup(0,\infty)\)5) f(f(x)) is given by:
\(f(f(x))=\frac{2}{f(x)}=\frac{2}{\frac{2}{x}}=x\)6)The domain of f(f(x)) is:
\((-\infty,\infty)\)7) g(g(x)) is calculated as:
\(\begin{gathered} g(g(x))=3(g(x))+12=3(3x+12)+12 \\ =9x+36+12 \\ =9x+48 \end{gathered}\)8)The domain of g(g(x)) is:
\((-\infty,\infty)\)When his first child was born, a father put $3000 in a savings account that pays 4% annual interest, compounded quarterly. How much will be in the account on the child's 18th birthday? Answer rounded to the whole number
Answers
Answer:
$6141
Step-by-step explanation:
We can use the formula for compound interest to find the amount in the account after 18 years:
A = P(1 + r/n)^(nt)
Where:
A = the amount in the account after 18 years
P = the principal amount (initial deposit) = $3000
r = the annual interest rate = 4% = 0.04
n = the number of times the interest is compounded per year = 4 (quarterly)
t = the time in years = 18
Plugging in these values, we get:
A = 3000(1 + 4%/4)^(4*18)
A = 3000(1.01)^72
A = 3000*2047
A = 6141
Rounding to the nearest whole number, we get:
A = $6141
Therefore, there will be $6141 in the account on the child's 18th birthday.
when sampling from a population with , which of the following sample means is more surprising? why? sample a: a random sample of 9 pell grant recipients with a mean award amount of $2750. sample b: a random sample of 36 pell grant recipients with a mean award amount of $2750. group of answer choices sample a is more surprising because there is less variability in smaller samples. sample a is more surprising because there is more variability in smaller samples sample b is more surprising because there is less variability in larger samples. the samples are equally surprising because the sample means are equal.
Answers
Sample a is more surprising because there is more variability in smaller samples, making it less likely to obtain a sample mean that is as extreme as $2750.
Sample A is more surprising because there is more variability in smaller samples. The variability of sample means decreases as the sample size increases due to the central limit theorem.
The central limit theorem states that as the sample size increases, the distribution of sample means becomes more normal, with a mean equal to the population mean and a standard deviation equal to the population standard deviation divided by the square root of the sample size.
Therefore, sample A, which has a smaller sample size of 9, has a larger standard deviation and more variability in the mean award amount compared to sample B, which has a sample size of 36. It is less likely to obtain a sample mean of $2750 from a smaller sample with more variability than from a larger sample with less variability. Thus, sample A is more surprising than sample B.
Learn more about population mean
https://brainly.com/question/19538277
#SPJ4
in the analysis of a two-way factorial design, how many main effects are tested?
Answers
In a two-way factorial design analysis, there are two main effects tested.
A two-way factorial design involves the simultaneous manipulation of two independent variables, each with multiple levels, to study their individual and combined effects on a dependent variable. The main effects in such a design represent the effects of each independent variable independently, ignoring the influence of the other variable.
When conducting a two-way factorial design analysis, there are two main effects tested, corresponding to each independent variable. The main effect of one variable is the difference in the means across its levels, averaged over all levels of the other variable. Similarly, the main effect of the other variable is the difference in the means across its levels, averaged over all levels of the first variable.
Testing the main effects allows researchers to determine the individual impact of each independent variable on the dependent variable, providing insights into their overall influence. By analyzing the main effects, researchers can assess the significance and directionality of the effects, aiding in the interpretation of the experimental results and understanding the relationship between the independent and dependent variables in the factorial design.
Learn more about independent variable here:
https://brainly.com/question/1479694
#SPJ11
Help me plsss pls psl

Answers
it’s not A because it’s not percentages it’s decimals using boxes as an example
Answer: A, B, D
it can’t be “C” because that would be equal to 40%
What are the zeros of the quadratic function f(x) = (x + 9)(x – 5)?
Answers
Answer:
x=-9 and x=5
Step-by-step explanation:
x+9=0 and x-5=0
x=-9 or x=5
What is the minimum thickness of a nonreflecting film coating (n = 1.30) on a glass lens (n = 1.50) for wavelength 500 nm?
Answers
The thickness of the non-reflective coating layer is 9.62 x 10¯⁸ m or 96.2 nm.
From the question we know that :
n = 1.30
λ = 500nm = 5 x 10¯⁷m
The non-reflective coating system is applied on glass and the refractive index of that system should be nair < ncoating < nglass. The light travels across the air and is refracted by coating film and then refracted again by the glass. For preventing the light got reflected by glass, the thickness of the layer should obey this equation :
2nt = λ/2
t is the thickness of the layer, λ is the wavelength and n is the refractive index of the film.
By substituting the following equation we get
2nt = λ/2
t = 1/4 . ( λ / n )
t = 1/4 . ( 5 x 10¯⁷ / 1.3)
t = 9.62 x 10¯⁸ m
Hence, the thickness of the non-reflective coating layer is 9.62 x 10¯⁸ m or 96.2 nm.
Find out more on non-reflective coating at: https://brainly.com/question/17205515
#SPJ4
Do the ratios 12/8 and 2/1 form a proportion
Answers
Answer:
No, the cross products to not equal
Step-by-step explanation:
\(\frac{12}{8}\) = \(\frac{2}{1}\)
12(1) = 8(2)
12 \(\neq\) 16
Or make them both into decimals
12/8 = 1.5
\(\frac{2}{1}\) = 2 They do not equal each other.
find the equation of a line whose intercepts on the x-axis is -2 and parallel to 2y + x - 1=0
Answers
Answer:
y = -1/2x-1 would have a x-intercept of -2 when graphed!
A large population has mean 100 and standard deviation 16. What is the probability that the sample mean will be within plusminus 2 of the population mean if the sample size is n = 100? What is the probability that the sample mean will be within plusminus 2 of the population mean if the sample size is n = 400? What is the advantage of a larger sample size?
Answers
The probability that the sample mean will be within plus minus 2 of the population mean if the sample size is n = 100 between z-scores of 0 and 2.5 using a z-table.
The standard deviation of the sample distribution, commonly known as the standard error, can be computed using the formula given that the population mean is 100 and the standard deviation is 16:
Standard Error = Standard Deviation / sqrt(sample size)
Let's determine the likelihoods for sample sizes of n = 100 and n = 400:
For n = 100:
Standard Error = 16 / sqrt(100) = 16 / 10 = 1.6
We can determine the z-scores for the upper and lower boundaries to establish the likelihood that the sample mean will be within plus or minus 2 of the population mean:
Lower Bound z-score = (Sample Mean - Population Mean) / Standard Error
Lower Bound z-score = (100 - 100) / 1.6
Lower Bound z-score = 0
Upper Bound z-score = (Sample Mean - Population Mean) / Standard Error
Upper Bound z-score = (104 - 100) / 1.6
Upper Bound z-score = 4 / 1.6
Upper Bound z-score = 2.5
We can calculate the region under the normal distribution curve between z-scores of 0 and 2.5 using a z-table or statistical software. This shows the likelihood that the sample mean will be within +/- 2 standard deviations of the population mean.
For n = 400:
Standard Error = 16/√400
Standard Error = 16/20
Standard Error = 0.8
We determine the z-scores by following the same procedure as above:
Lower Bound z-score = (Sample Mean - Population Mean) / Standard Error
Lower Bound z-score = (100 - 100) / 0.8
Lower Bound z-score = 0
Upper Bound z-score = (Sample Mean - Population Mean) / Standard Error
Upper Bound z-score = (104 - 100) / 0.8
Upper Bound z-score = 4 / 0.8
Upper Bound z-score = 5
Once more, we may determine the region under the normal distribution curve between z-scores of 0 and 5 using a z-table or statistical software.
A larger sample size, like n = 400, has the benefit of a lower standard error. The sampling distribution of the sample mean will be more constrained and more closely resemble the population mean if the standard error is less.
As a result, there is a larger likelihood that the sample mean will be within +/- 2 of the population mean. In other words, the estimate of the population mean gets more accurate and dependable as the sample size grows.
To learn more about population mean link is here
brainly.com/question/30324262
#SPJ4
what the slope of (19,-12) (5, 16)
Answers
Answer:
The slope is -28/14


Determine whether the statement is true or false. A system composed of two linear equations must have at least one solution if the straight lines represented by these equations are nonparallel.
a. True
b. False
Answers
True
The statement "A system composed of two linear equations must have at least one solution if the straight lines represented by these equations are nonparallel," is true.
What is a system of linear equations?
In algebra, a system of linear equations is a collection of two or more linear equations with the same variables.
If these linear equations represent two or more lines that aren't parallel, the equations are said to form a system of equations with at least one solution.
The intersection of the lines is the location where an equation system has a solution.
Two lines are parallel if they have the same slope and never intersect.
If two lines have different slopes, they are nonparallel and intersect at a point.
How can one tell if a statement is true or false?
If a claim can be verified by evidence, logic, or reason, it can be considered true.
On the other hand, a statement is false if it is inaccurate or misleading, or if it contradicts existing facts, logic, or reason.
Learn more about system of linear equations, visit here
https://brainly.com/question/24085666
#SPJ11
A submarine sits at -300 meters in relation to sea level. Then it descends 115 meters. What is its new position in relation to sea level.
Answers
Answer:
-415
Step-by-step explanation:
Answer:
A is correct answer
Step-by-step explanation:
The Central Fabric Company purchases surplus bolts of fabric from two large textile mills, A and B. These fabrics are then sold to the public through bolts fabric stores, discount stores and direct mail. When Central receives the bolts, it separates them according to the market in which they are sold. Of the fabrics received from the textile mill A, 40 percent are sold to fabric stores, 10 percent in discount stores, and 30 percent by direct mail. The fabric received from textile mill B are 20 percent for fabric stores, 20 percent for discount stores, and 40 percent for direct sales. Of the total purchases made from either mill A or mill B, 20 percent of the bolts are unusable and thrown away. For every 1,000 bolts purchased from mill A, Central Fabric realizes a profit of P8,000; for every 1,000 bolts purchased from mill B, it realizes a profit of P6,000. The sales department forecasts that, at most, 1,600 bolts can be sold through fabric shops, 2,800 through discount stores, and 2,600 through direct mail in the coming year. Determine the most profitable numbers of bolts which Central Fabric should purchase from mills A and B using the graph method.
Answers
Using the graph method, Central Fabric should determine the most profitable numbers of bolts to purchase from mills A and B by considering profit calculations, supply and demand constraints, and plotting a profit graph.
To determine the most profitable numbers of bolts that Central Fabric should purchase from mills A and B using the graph method, we need to create a profit graph based on the given information.
Start by calculating the total available supply for each market channel:
Fabric Stores: (0.40 * Total Bolts from Mill A) + (0.20 * Total Bolts from Mill B)
Discount Stores: (0.10 * Total Bolts from Mill A) + (0.20 * Total Bolts from Mill B)
Direct Mail: (0.30 * Total Bolts from Mill A) + (0.40 * Total Bolts from Mill B)
Determine the maximum number of bolts that can be sold in each market channel:
Fabric Stores: 1,600 bolts
Discount Stores: 2,800 bolts
Direct Mail: 2,600 bolts
Calculate the profit for each combination of bolts purchased from mills A and B:
Profit from Mill A: (0.60 * Total Bolts from Mill A - 0.20 * Total Bolts from Mill A) * P8,000
Profit from Mill B: (0.80 * Total Bolts from Mill B - 0.20 * Total Bolts from Mill B) * P6,000
Plot the profit graph by considering different combinations of Total Bolts from Mill A and Total Bolts from Mill B, while taking into account the constraints of available supply and market demand.
Find the combination of Total Bolts from Mill A and Total Bolts from Mill B that maximizes the profit while satisfying the supply and demand constraints. This point on the graph represents the most profitable numbers of bolts to purchase from mills A and B.
To know more about profit graph,
https://brainly.com/question/3308246
#SPJ11
A six-sided die is rolled 100 times. Using the normal approximation, find the probability that the face showing a six turns up between 15 and 20 times. Find the probability that the sum of the face values of the 100 trials is less than 300.
Answers
The probability of obtaining the face showing a six between 15 and 20 times out of 100 rolls of the die ≈ 0.3106 and the probability of the sum of the face values of the 100 trials being less than 300 ≈ 0.1635.
To cumulate the probability of the face showing a six turns up between 15 and 20 times when rolling a six-sided die 100 times, we can use the normal approximation to the binomial distribution.
The probability of rolling a six on a fair six-sided die is 1/6, and the probability of not rolling a six is 5/6.
Let's define a random variable X as the number of times a six appears when rolling the die 100 times.
X follows a binomial distribution with parameters n = 100 (number of trials) and p = 1/6 (probability of success).
To use the normal approximation, we need to calculate the mean (μ) and standard deviation (σ) of the binomial distribution:
μ = n * p = 100 * 1/6 = 16.67
σ = √(n*p*(1 - p)) = √(100 * 1/6 * 5/6) = 4.08
Now, we can standardize the values 15 and 20 using the normal distribution:
z1 = (15 - μ) / σ = (15 - 16.67) / 4.08 ≈ -0.41
z2 = (20 - μ) / σ = (20 - 16.67) / 4.08 ≈ 0.81
Using a standard normal distribution table or a calculator, we can find the cumulative probabilities for these z-values:
P(15 ≤ X ≤ 20) ≈ P(-0.41 ≤ Z ≤ 0.81)
From the table or calculator, we find that P(-0.41 ≤ Z ≤ 0.81) is approximately 0.3106.
Therefore, the probability that the face showing a six turns up between 15 and 20 times when rolling the die 100 times is approximately 0.3106.
To cumulate the probability that the sum of the face values of the 100 trials is less than 300, we need to consider the distribution of the sum of independent rolls of a six-sided die.
The sum of the face values of the 100 trials will follow an approximately normal distribution due to the Central Limit Theorem.
The mean (μ) of the sum is 100 * (1+2+3+4+5+6)/6 = 350.
The standard deviation (σ) of the sum is:
√(100 * (1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2)/6) ≈ 50.99.
Now, we can standardize the value 300 using the normal distribution:
z = (300 - μ) / σ = (300 - 350) / 50.99 ≈ -0.98.
Using a standard normal distribution table or calculator, we can find the cumulative probability for this z-value:
P(X < 300) ≈ P(Z < -0.98) ≈ 0.1635.
Hence, the probability that the sum of the face values of the 100 trials is less than 300 ≈ 0.1635.
To know more about probability refer here:
https://brainly.com/question/32560116#
#SPJ11

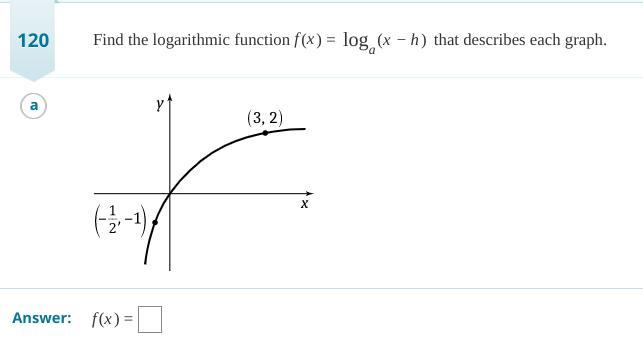
Find the logarithmic function f(x) = log a (x-h) that describes the graph *image included*
Answers
The logarithmic function that describes the graph is given as follows:
\(f(x) = \log_2{(x + 1)}\)
How to define the logarithmic function?The parent logarithmic function is defined as follows:
f(x) = log(x).
Which, no matter the base, has the vertical asymptote given as follows:
x = 0.
The vertical asymptote of the graphed function is given as follows:
x = -1.
Hence:
\(f(x) = \log_a{(x + 1)}\)
When x = 3, f(x) = 2, hence the base a is obtained as follows:
\(2 = \log_a{(4)}\)
Meaning that:
a² = 4.
a = 2.
And the function is then defined as follows:
\(f(x) = \log_2{(x + 1)}\)
More can be learned about logarithmic functions at https://brainly.com/question/28596566
#SPJ1
CC has the following beginning balances in its stockholders' equity accounts on January 1, 2012: Common Stock, $100,000; Additional Paid-in Capital, $4,100,000; and Retained Earnings, $3,000,000. Net income for the year ended December 31, 2012, is $800,000. Court Casuals has the following transactions affecting stockholders' equity in 2012:
May 18 Issues 25,000 additional shares of $1 par value common stock for $40 per share.
May 31 Repurchases 5,000 shares of treasury stock for $45 per share.
July 1 Declares a cash dividend of $1 per share to all stockholders of record on July 15. Hint: Dividends are not paid on treasury stock.
July 31 Pays the cash dividend declared on July 1.
August 10 Reissues 2,500 shares of treasury stock purchased on May 31 for $48 per share.
Taking into consideration all the entries described above, prepare the statement of stockholders' equity for the year ended December 31, 2012.
Answers
Total stockholders’ equity 7,800,000
Statement of stockholders’ equity for CC for the year ended December 31, 2012:Particulars Amount ($)
Common Stock 100,000
Additional Paid-in Capital 4,100,000
Retained Earnings (Opening Balance) 3,000,000
Add: Net Income for the year ended December 31, 2012 800,000
Total retained earnings 3,800,000
Less: Cash Dividend Declared on July 1 and paid on July 31 (200,000)
Retained earnings (Closing balance) 3,600,000
Total stockholders’ equity 7,800,000
Explanation:The given information is as follows:Common Stock on January 1, 2012 = $100,000Additional Paid-in Capital on January 1, 2012 = $4,100,000
Retained Earnings on January 1, 2012 = $3,000,000Net Income for the year ended December 31, 2012 = $800,000Cash Dividend Declared on July 1 and paid on July 31 = $200,000
To prepare the statement of stockholders’ equity for the year ended December 31, 2012, we will begin by preparing the opening balances of each of the equity accounts. We will then add the net income to the retained earnings account.
The closing balance for retained earnings is then computed by subtracting the cash dividend declared and paid from the total retained earnings. Finally, the total stockholders' equity is calculated by adding the balances of all the equity accounts.
Calculations:Opening balance of common stock = $100,000
Opening balance of additional paid-in capital = $4,100,000
Opening balance of retained earnings = $3,000,000
Net Income for the year ended December 31, 2012 = $800,000
Retained earnings (Opening Balance) = $3,000,000
Add: Net Income for the year ended December 31, 2012 = $800,000
Total retained earnings = $3,800,000Less: Cash Dividend Declared on July 1 and paid on July 31 = $200,000Retained earnings (Closing balance) = $3,600,000
Total stockholders’ equity = Common Stock + Additional Paid-in Capital + Retained Earnings (Closing balance) = $100,000 + $4,100,000 + $3,600,000 = $7,800,000
Therefore, the statement of stockholders’ equity for CC for the year ended December 31, 2012, is as follows:Particulars Amount ($)
Common Stock 100,000
Additional Paid-in Capital 4,100,000
Retained Earnings (Opening Balance) 3,000,000
Add: Net Income for the year ended December 31, 2012 800,000
Total retained earnings 3,800,000
Less: Cash Dividend Declared on July 1 and paid on July 31 (200,000)
Retained earnings (Closing balance) 3,600,000
To learn more about : equity
https://brainly.com/question/27821130
#SPJ8
MacKenzie invested $6,500 in an account that earns 4.3% simple interest rate. What is the balance in her account after 5 years?
Answers
Answer:
so you wold do I=t×r×A ok so I=6,500 t=5 r=4.3 and u have to find A so you wolf multiple 5×4.3=21.5 and than you wold divide 6500÷21.5=302.3255813953488×21.5= 6500 so A=302.3255813953488
Can somebody help me find this missing angle please.

Answers
Answer:
x = 96 degrees
Step-by-step explanation:
49 + 35 + x = 180
84 + x = 180
x = 180 - 84
x = 96 degrees