
Answers
Answer:
E
Step-by-step explanation:
because it makes sense
Related Questions
Help me with three questions a brainlist!
Answers
Answer:
Step-by-step explanation:
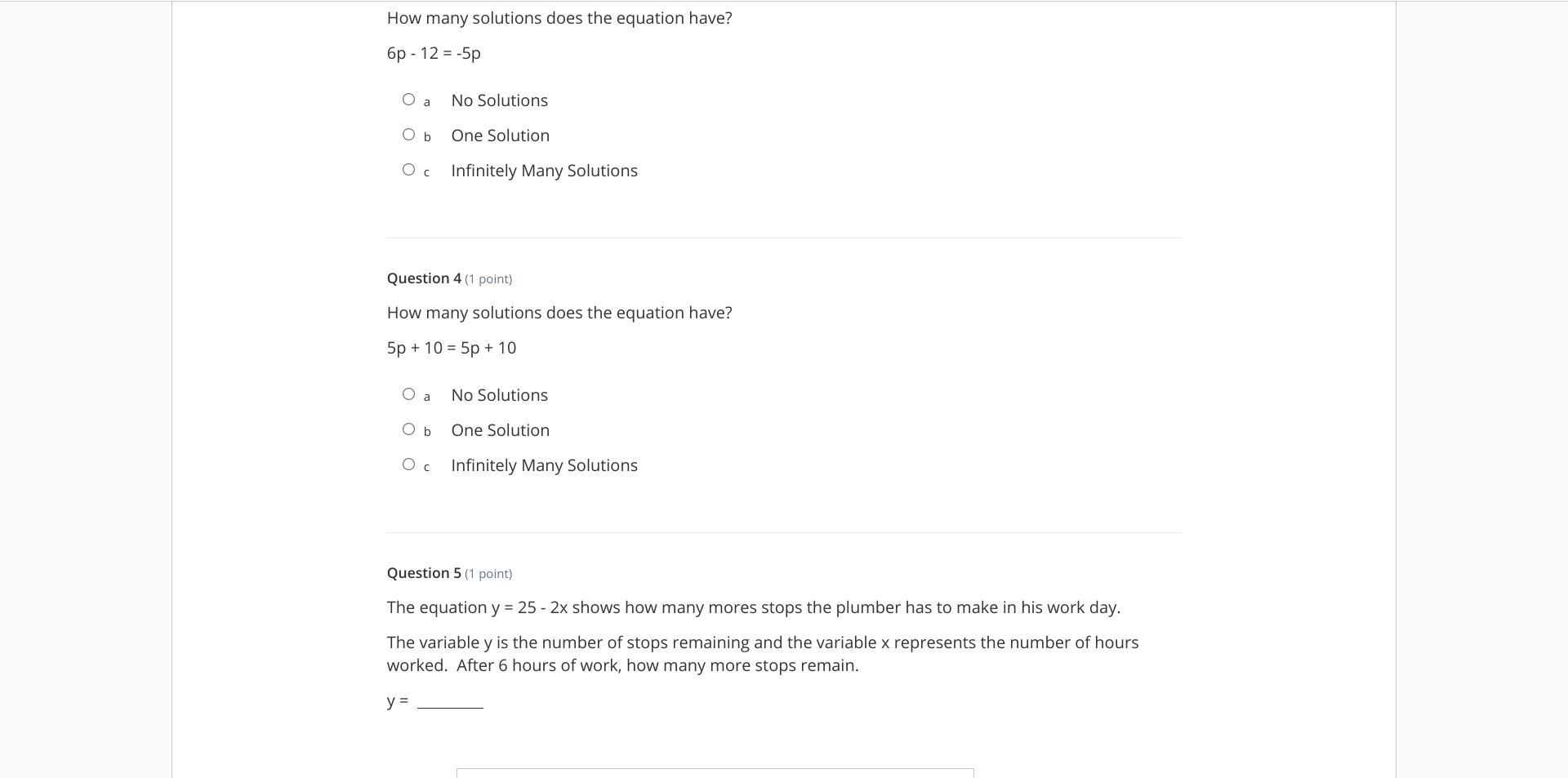
First question
1 solution
6p-12= - 5p Take 6p from both sides-12 = -5p - 6p Combine-12 = - 11p Divide by - 11-12/-11 = p1.09 = pSecond Question
Infinitely many solutions.5p + 10 = 5p + 10No matter what value you use for p, the right side of the equation always equals the left side.Third question
y = 25 - 2xx = 6y = 25 - 2*6y = 25 - 12y = 13There are 13 more stops to make.
a student has 4.9 x 1022 molecules of a (probably fictional) carbohydrate with the following formula: c9h11o6. how many grams of c are in this sample? enter your answer to the nearest tenth, without units, and ignoring sig figs.
Answers
There are approximately 0.976 grams of carbon (C) in the given sample of the carbohydrate (C9H11O6).
To find the number of grams of carbon (C) in the sample, we need to first determine the molar mass of the carbohydrate.
The molar mass of C is approximately 12.01 g/mol. The molar mass of H is approximately 1.01 g/mol, and the molar mass of O is approximately 16.00 g/mol.
The molar mass of the carbohydrate (C9H11O6) can be calculated as follows:
(9 * 12.01 g/mol) + (11 * 1.01 g/mol) + (6 * 16.00 g/mol) = 162.18 g/mol
Next, we can use the Avogadro's number (6.022 x 10^23) to determine the number of moles in the sample:
4.9 x 10^22 molecules / 6.022 x 10^23 molecules/mol = 0.0813 mol
Finally, we can calculate the mass of carbon in the sample by multiplying the number of moles by the molar mass of carbon:
0.0813 mol * 12.01 g/mol ≈ 0.976 g
So, there are approximately 0.976 grams of carbon in this sample.
There are approximately 0.976 grams of carbon (C) in the given sample of the carbohydrate (C9H11O6).
To find the mass of carbon in the sample, we first need to determine the molar mass of the carbohydrate. The molar mass of an element or compound is the mass of one mole of that substance. In this case, we have the formula C9H11O6, which indicates that the carbohydrate consists of 9 carbon atoms (C), 11 hydrogen atoms (H), and 6 oxygen atoms (O).
The molar mass of carbon is approximately 12.01 g/mol, hydrogen is approximately 1.01 g/mol, and oxygen is approximately 16.00 g/mol. To calculate the molar mass of the carbohydrate, we multiply the number of atoms of each element by their respective molar masses and sum them up.
Therefore, the molar mass of C9H11O6 is
(9 * 12.01 g/mol) + (11 * 1.01 g/mol) + (6 * 16.00 g/mol) = 162.18 g/mol.
Next, we can use the Avogadro's number (6.022 x 10²³) to determine the number of moles in the given sample. The given sample contains 4.9 x 10²²molecules of the carbohydrate. Dividing this by Avogadro's number gives us the number of moles:
4.9 x 10 molecules / 6.022 x 10^23 molecules/mol = 0.0813 mol.
Finally, we can calculate the mass of carbon in the sample by multiplying the number of moles by the molar mass of carbon: 0.0813 mol * 12.01 g/mol ≈ 0.976 g. Therefore, there are approximately 0.976 grams of carbon in the given sample.
In conclusion, the sample of the carbohydrate (C9H11O6) contains approximately 0.976 grams of carbon (C).
To know more about Avogadro's number visit:
brainly.com/question/16348863
#SPJ11
Solve for e.
9e-5 = 7e-11
Answers
Explanation:
9e - 5 = 7e - 11
9e - 7e = -11 + 5
2e = -6
e = -6/2
e = -3
Answer:
e = -3
Step-by-step explanation:
9e - 5 = 7e - 11
2e - 5 = - 11
+5 +5
2e = -6
2 2
e = -3
identify the rule of similarity in Trigonometry
Answers
Answer:
Step-by-step explanation:
If three sides of a triangle are proportional to the three sides of another triangle, then the triangles are similar
Pineapple Corporation (PC) maintains that their cans have always contained an average of 12 ounces of fruit. The production group believes that the mean weight has changed. They take a sample of 13 cans and find a sample mean of 12.03 ounces and a sample standard deviation of .07 ounces. What conclusion can we make from the appropriate hypothesis test at the .10 level of significance
Answers
Since our calculated t-value of 4.39 is greater than the critical value of 1.782, we can reject the null hypothesis at the 0.10 level of significance. This means that we have evidence to suggest that the mean weight of Pineapple Corporation's cans is not equal to 12 ounces, supporting the production group's belief.
To test whether the production group's belief that the mean weight of Pineapple Corporation's cans has changed, we need to conduct a hypothesis test. We can start by setting up our null and alternative hypotheses:
- Null hypothesis (H0): The mean weight of Pineapple Corporation's cans is equal to 12 ounces.
- Alternative hypothesis (Ha): The mean weight of Pineapple Corporation's cans is not equal to 12 ounces.
We can use a two-tailed t-test to test this hypothesis since we do not have information about the direction of the change in mean weight. With a sample size of 13, we need to use a t-distribution with 12 degrees of freedom.
Using the information given, we can calculate the test statistic:
t = (sample mean - hypothesized mean) / (sample standard deviation / sqrt(sample size))
t = (12.03 - 12) / (0.07 / sqrt(13))
t = 4.39
Looking at a t-distribution table with 12 degrees of freedom and a significance level of 0.10 (two-tailed), we can see that the critical values are +/- 1.782.
Know more about critical value here:
https://brainly.com/question/30168469
#SPJ11
The sum of 10 and a number x
Answers
Answer:Complete the question pls
Step-by-step explanation:
Simplify 3(2x - 5).
1.) 6 x - 8
2.) -6 x - 15
3.) 6 x - 15
4.) 5 x - 2
this is multiple choice
Answers
Answer:
6x - 15
Step-by-step explanation:
3(2x - 5)
Distribute
3*2x - 3*5
6x - 15
Please help me with the circled math question homework

Answers
The expressions are simplified to give;
7. 4n³(3n² + 4)
8. -3x(3x² - 4)
9. 5(k² - 8k + 2)
10. -10(6 + 6n² + 5n³)
11. 3(6n³ - 4n - 7)
12. 9(7n³ + 9n + 2)
What are algebraic expressions?Algebraic expressions are defined as mathematical expressions that are composed of variables, coefficients, terms, factors and constants.
These algebraic expressions are also made up of arithmetic operations, such as;
AdditionBracketSubtractionDivisionParenthesesMultiplicationTo factorize the expressions, we have;
12n⁵ + 16n³
Find the common term
4n³(3n² + 4)
-9x³ - 12x
find the common term
-3x(3x² - 4)
5k² - 40k + 10
find the common terms
5(k² - 8k + 2)
-60 + 60n² + 50n³
find the common term
-10(6 + 6n² + 5n³)
18n³ -12n - 21
find the common term
3(6n³ - 4n - 7)
63n³ + 81n + 18
Find the common term
9(7n³ + 9n + 2)
Learn about algebraic expressions at: https://brainly.com/question/4344214
#SPJ1
Dilate quadrilateral ABCD with the origin as the center of dilation and a scale factor of 2.5. Record the side lengths of the corresponding sides in each quadrilateral. Round your answers to the hundredths place. Verify that the ratio of each side length of A′B′C′D′ to the corresponding side length of ABCD is equal to the dilation factor.
PLEASE I NEED HELP WITH THIS !!!!!!!

Answers
Answer:
dilated figure — attachment 1side lengths and ratios — attachment 2Step-by-step explanation:
Dilation about the origin is accomplished by multiplying each coordinate by the dilation factor.
Using GeoGebra, the dilation by a factor of 2.5 is easily accomplished by defining the dilated points as ...
A' = 2.5A
B' = 2.5B
C' = 2.5C
D' = 2.5D
__
GeoGebra can be set to display the lengths of the line segments, so we have done that in the first attachment. They are computed as the root of the sum of the squares of the differences in x- and y-coordinates. That computation is programmed into the spreadsheet of the second attachment.
The second attachment lists the dilated coordinates and the lengths computed for each of the segments.
The RATIO calculation divides the dilated segment length by the original segment length. It verifies that all segments in the dilated figure are 2.5 times the corresponding length in the pre-image.
_____
Segment lengths are calculated using the distance formula:
\(d=\sqrt{(x_2-x_1)^2+(y_2-y_1)^2}\)
_____
Comment on coordinates
We have used the coordinates shown in the problem statement for the given points. However, we note that the quadrilateral areas reported are different for the given problem and our attempt to copy it. (4.54 vs 4.55) This suggests that one or more point coordinates are actually slightly different from the value shown in the problem. Of course, that difference would have to be in the hidden 3rd decimal place.


f(x)=2x^2-5x-3 g(x)=2x^2+5x+2 find (f/g)(x)
Answers
If f(x)=2x²-5x-3 g(x)=2x²+5x+2 then (f/g)(x) = (x - 3) / (x + 2).
What is function?
In mathematics, a function is a relationship between two sets of elements, called the domain and the range, such that each element in the domain is associated with a unique element in the range.
To find (f/g)(x), we need to divide f(x) by g(x) as follows:
f(x) = 2x² - 5x - 3
g(x) = 2x² + 5x + 2
f(x) / g(x) = (2x² - 5x - 3) / (2x² + 5x + 2)
To simplify this expression, we can factor the numerator and denominator:
f(x) / g(x) = [(2x + 1)(x - 3)] / [(2x + 1)(x + 2)]
Now, we can cancel out the common factor of (2x + 1) from both the numerator and denominator:
f(x) / g(x) = (x - 3) / (x + 2)
Therefore, (f/g)(x) = (x - 3) / (x + 2).
To learn more about functions from the given link:
https://brainly.com/question/12431044
#SPJ1
She selects 150 trees at random from her orchard and uses this fertilizer on those trees and estimates the following regression: Y
^
i
=600+4.93X i
, where Y
^
i
denotes the predicted number of apricots obtained from the I th tree and X i
denotes the number of units of fertilizer used on the I th tree. A. H 0
:β 1
≥5.14 and H 1
:β 1
<5.14. B. H 0
:β 1
>4.93 and H 1
:β 1
≤4.93. C. H 0
:β 1
=5.14 and H 1
:β 1
=5.14. D. H 0
:β 0
=4.93 and H 1
:β 0
=4.93. Suppose the standard error of the estimated slope is 0.74. The t-statistic associated with the test Wendy wishes to conduct is (Round your answer to two decimal places. Enter a minus sign if your answer is negative.1
Answers
Given statement solution is :- The t-statistic associated with the test is approximately -0.28.
The t-statistic, which is used in statistics, measures how far a parameter's estimated value deviates from its hypothesised value relative to its standard error. Through the Student's t-test, it is utilised in hypothesis testing. In a t-test, the t-statistic is used to decide whether to accept or reject the null hypothesis.
To find the t-statistic associated with the test, we need to calculate the test statistic using the estimated slope coefficient, the null hypothesis, and the standard error.
The estimated slope coefficient is 4.93.
The null hypothesis is H₀: β₁ ≥ 5.14 (stating that the true slope coefficient is greater than or equal to 5.14).
The predicted slope's standard error is 0.74.
The formula to calculate the t-statistic is:
t = (estimated slope - hypothesized slope) / standard error
Plugging in the values:
t = (4.93 - 5.14) / 0.74
t = -0.21 / 0.74
t ≈ -0.28 (rounded to two decimal places)
Therefore, the t-statistic associated with the test is approximately -0.28.
For such more questions on t-statistic
https://brainly.com/question/28235817
#SPJ8
Tell what each of the residual plots to the right indicates about the appropriateness of the linear model that was fit to the data.
a)x-valuesResiduals
A scatterplot with horizontal axis labeled "x-values" and vertical axis labeled "Residuals" contains points that appear randomly distributed.
b)x-valuesResiduals
A scatterplot with horizontal axis labeled "x-values" and vertical axis labeled "Residuals" contains points whose general pattern is a curve that falls and then rises from left to right.
c)x-valuesResiduals
A scatterplot with horizontal axis labeled "x-values" and vertical axis labeled "Residuals" contains points that have a wide vertical range on the left side of the plot and which become more and more tightly clustered from left to right. Points on the right side of the graph tightly follow the path of a horizontal line.
Question content area bottom
(a) Choose the best answer for residuals plot (a).
A The fanned pattern indicates that the linear model is not appropriate. The model's predicting power decreases
as the values of the explanatory variable increases.
OB. The fanned pattern indicates that the linear model is not appropriate. The model's predicting power increases
as the values of the explanatory variable increases.
Oc. The scattered residuals plot indicates an appropriate linear model.
h
(b) Choose the best answer for residuals plot (b).
OA. The scattered residuals plot indicates an appropriate linear model.
OB. The curved pattern in the residuals plot indicates that the linear model is not appropriate. The relationship
is not linear.
Oc. The fanned pattern indicates that the linear model is not appropriate. The model's predicting power decreases
as the values of the explanatory variable increases.
Answers
Answer:
(a) The best answer for residuals plot (a) is:
A. The fanned pattern indicates that the linear model is not appropriate. The model's predicting power decreases as the values of the explanatory variable increases.
A fanned pattern in the residuals plot suggests that the linear model is not appropriate because the variability of the residuals increases as the values of the explanatory variable increases. This indicates that the linear model is not capturing all the important features of the data and may not be the best fit for the data.
(b) The best answer for residuals plot (b) is:
B. The curved pattern in the residuals plot indicates that the linear model is not appropriate. The relationship is not linear.
A curved pattern in the residuals plot suggests that the linear model is not appropriate because the relationship between the variables is not linear. This indicates that the linear model is not capturing all the important features of the data and may not be the best fit for the data.
If n represents a number, which of the following expressions represents the sum of one more than twice the number and three less than 5 times the number? *
Answers
Answer:
the anwer is option 1
Step-by-step explanation: 7n+2
Eliana is reading a 964-page book.She reads 20 pages per day in the book. If x represents the number of days Eliana has spent reading the book so far, which of the following equations can be used to find the number of pages remaining in the book for Elaina to read. A-y=20x+964 B-y=-20+964 C-y=964+20 D-y=-964+20
Answers
Answer:
the answer is a
Step-by-step explanation:
Classify a triangle whose side lengths are 8, 16, and 18
A. Right Triangle
B. Acute Triangle
C. Obtuse Triangle
D. Isosceles Triangle
Answers
Answer:
Obtuse triangle
Step-by-step explanation:
A triangle is a polygon with three sides and three angles. There are different types of triangles such as right angled, acute, obtuse and isosceles triangle.
In right angle triangle, one angle is 90°. The square of the longest side (hypotenuse) is equal to the sum of the square of the two sides.
An acute triangle is a triangle with acute angles (less than 90°). The square of the longest side is less than the sum of the square of the two sides.
An obtuse triangle is a triangle with one obtuse angle (greater than 90°) and two acute angles (less than 90°). The square of the longest side is larger than the sum of the square of the two sides.
An isosceles triangle is a triangle with two equal sides.
Given a triangle whose side lengths are 8, 16, and 18, the longest side is 18.
Since no two sides are the same hence it is not an isosceles triangle.
Also, 18² > 16² + 8²; therefore this is an obtuse triangle
given your answer to (i), if jim chooses to buy 4 pints of beer and 9 cups of coffee, what must be the ratio of the price of pints of beer to the price of cups of coffee?
Answers
The ratio of the price of pints of beer to the price of cups of coffee if Jim chooses to buy 4 pints of beer and 9 cups of coffee is: b/c = 4b/9c , b/c = 1.125
Jim bought 3 pints of beer and 7 cups of coffee for $14, and the ratio of the price of pints of beer to the price of cups of coffee is 2:3,
To determine the cost of one pint of beer and one cup of coffee, let's solve the system of equations.
2b + 3c = 7 (dividing both sides of the equation by 7)
2b/7 + 3c/7 = 1b/3.5 + c/2.333
= 1b + 1.5c
= 4.666... (dividing both sides of the equation by 3.5)
b/3.5 × 4 + c/2.333 × 9
= 14b/0.875 + c/0.259
= 14.666...
Therefore, the ratio of the price of pints of beer to the price of cups of coffee if Jim chooses to buy 4 pints of beer and 9 cups of coffee is:
b/c = 4b/9c (multiplying both sides by 9c)
b/c = 1.125
Learn more about Ratio:
brainly.com/question/12024093
#SPJ11
How many ways can a set of four tires be put on a car if all the tires are interchangeable? How many ways are possible if two of the four are snow tires?
Answers
Answer: 24 possible ways
A set of 4 tires can be fixed in any of the four possible positions in a car as it is mentioned that all four tires are interchangeable. Therefore, the 4 tires can be fixed in 4! ways. The four interchangeable tires can be put on a car in 24 possible ways.
Step-by-step explanation:
looked it up
Probability:
Person A and Person B are playing archery together. Assume their abilities to fire the arrow at the target are exactly the same, and the probability of getting the target is 0.5 for both of them.
Now that given A has fired 201 arrows and B has fired 200 arrows, what is the probability that A gets more targets than B?
Answers
If Person A and Person B are playing archery together. the probability that A gets more targets than B is 0.5, or 50%.
How to find the probability?The number of targets hit by A and B follows a binomial distribution with parameters n = 201 and n = 200, respectively, and p = 0.5.
To find the probability that A gets more targets than B, we need to find the probability that A hits more than 100 targets (since 100 is the average number of targets hit by each player). We can use the normal approximation to the binomial distribution to do this.
The mean of the difference in the number of targets hit by A and B is:
E(A - B) = E(A) - E(B) = np - np = 0
The variance of the difference in the number of targets hit by A and B is:
Var(A - B) = Var(A) + Var(B) = np(1-p) + np(1-p) = 100
The standard deviation of the difference is then:
SD(A - B) = sqrt(Var(A - B)) = 10
Using the normal distribution approximation, we can standardize the difference in number of targets:
Z = (X - E(A - B)) / SD(A - B)
where X is the number of targets that A hits.
P(A hits more targets than B) = P(A - B > 0)
= P(Z > (0 - 0) / 10)
= P(Z > 0)
= 0.5
Therefore, the probability that A gets more targets than B is 0.5, or 50%. This means that there is an equal chance that A will hit more targets than B as there is that B will hit more targets than A.
Learn more about probability here:https://brainly.com/question/13604758
#SPJ1
4.21 game of dreidel. a dreidel is a four-sided spinning top with the hebrew letters nun, gimel, hei, and shin, one on each side. each side is equally likely to come up in a single spin of the dreidel. suppose you spin a dreidel three times. calculate the probability of getting
Answers
The probability of getting at least one nun in three spins of a dreidel is approximately 0.578
The probability is the ratio of number of favorable outcomes to the total number of outcomes
The probability of getting no nuns in a single spin is 3/4, since there are three non-nun letters (Gimel, Hei, Shin) and four total letters.
The probability of getting no nuns in three spins is then (3/4)^3, since the spins are independent and we can multiply probabilities of independent events.
So the probability of getting at least one nun in three spins is
= 1 - (3/4)^3
= 1 - 0.421875
= 0.578125
Therefore, the probability of getting at least one nun is 0.578
Learn more about probability here
brainly.com/question/11234923
#SPJ4
The given question is incomplete, the complete question is:
A dreidel is a four-sided spinning top with the Hebrew letters nun, gimel, hei, and shin, one on each side. Each side is equally likely to come up in a single spin of the dreidel. Suppose you spin a dreidel three times. Calculate the probability of getting (a) at least one nun?
What number goes in the
missing space?

Answers
russell is a history teacher who recently held an exam in his class. the mean score result is 65, while the standard deviation was 20. assume that the scores are normally distributed. if a student's z-score was 1.5, how many points did he score on the exam?
Answers
If a student's z-score was 1.5, then 95 points he scored on the exam.
The mean score result is 65.
The standard deviation was 20.
A student's z-score was 1.5.
The average of a set of data is known as the set's mean. Each item of data has a z-score that indicates how far it deviates from the mean, whereas the standard deviation of a set of data reveals how dispersed the data is.
We can relate a piece of data using a formula that uses the mean, standard deviation, and z-score to identify various pieces of information in a certain situation.
The formula of z-score is:
Z = (X - Mean)/Standard Deviation
Now putting the value
1.5 = (X - 65)/20
Multiply by 20 on both side, we get
30 = X - 65
Add 65 on both side, we get
X = 95
To learn more about standard deviation link is here
brainly.com/question/23907081
#SPJ4
factorise completely (x plus 2) Square - (x - 4) Square and hence find then value of 1000 Square minus 992 Square
Answers
Answer:
\(x^2+3x+8\)
\(15936\)
Step-by-step explanation:
\(\left(x+2\right)^2-\left(x-4\right)\)
\(\left(x+2\right)\left(x+2\right)-\left(x-4\right)\)
\(x^2+2x+2x+4-(x-4)\)
\(x^2+4x+4-\left(x-4\right)\)
\(x^2+4x+4-x+4\)
\(x^2+3x+8\)
\(1000^2-992^2\)
\(1000000-984064\)
\(15936\)
Which is the domain of the piecewise function shownhere?A. -6 0There’s a graph with piecewise functions on it. But if someone would help me that would be great

Answers
It is important to know that the domain refers to the set of x-values of the given function.
The first interval shown is
\((-\infty,-6\rbrack\)The second interval shown is
\((-6,-3)\)The third interval shown is
\(\lbrack-3,4\rbrack\)If you add all the intervals shown, we get the following domain
\((-\infty,4\rbrack\)Which can be expressed as
\(x\leq4\)Hence, the answer is C.The record high temperature in Australia is 123°F. The record low temperature in Australia is – 9°F. How many degrees warmer is the record high temperature than the record low temperature?
Answers
Answer:
132
Step-by-step explanation:
123+9=132?
Answer:
132 degrees and can I get brainliest
Step-by-step explanation:
Absolute value of -9 is 9 so then 123 plus 9.
one airline has six across seating in coach (three seats on either side of the aisle). if seats are assigned randomly, what is the probability that a person will be stuck in a middle seat? (enter the probability as a fraction.)
Answers
1/3
The probability that a person will be stuck in a middle seat when seats are assigned randomly is 1/3. This is because there are three middle seats for every six seats total in the coach cabin.
Learn more about probability
brainly.com/question/30034780
#SPJ11
The expression 2w^2 + 10w represents the area of a rectangle with width of w inches. select the situation that could be represented by the expression 100-10w-2w^2

Answers
Answer:
Option C
Step-by-step explanation:
We know that the expression:
2*w^2 + 10*w
Represents the area of a rectangle with width w.
Now we want to find the situation that can be represented with the expression:
100 - 10*w - 2*w^2
Let's rewrite this as:
100 - (2*w^2 + 10*w)
Then we are subtracting the area of our rectangle to an area of measure 100.
Now, suppose that we have a square of 10in by 10 in.
The area of that square will be:
A = 10in*10in = 100 in^2
Now if we cut our rectangle (with an area = 2*w^2 + 10*w) from that square, the new area of the figure will be:
area = 100in^2 - (2*w^2 + 10*w)
Which is exactly the expression in the question, then the correct option is:
Option C
Solve the given differential equation:
xy''+y'=0
usually if it was the form (x^2)y''+xy'+5y=0, you could then assume (r^2)+(1-1)r+5=0
how do i start/solve this?
Answers
The solution to the given differential equation is \(y = a_0x^{[0]} + a_1x^{[1]} + a_2x^{[2]}\), where a_0, a_1, and a_2 are constants.
How to solve the differential equationTo fathom the given differential equation, xy'' + y' = 0, we will begin by expecting a control arrangement of the frame y = ∑(n=0 to ∞) a_nx^n, where a_n speaks to the coefficients to be decided.
Separating y with regard to x, we get:
\(y' = ∑(n=0 to ∞) a_n(nx^[(n-1))] = ∑(n=0 to ∞) na_nx^[(n-1)]\)
Separating y' with regard to x, we get:
\(y'' = ∑(n=0 to ∞) n(n-1)a_nx^[(n-2)]\)
Presently, we substitute these expressions for y and its subsidiaries into the differential condition:
\(x(∑(n=0 to ∞) n(n-1)a_nx^[(n-2))] + (∑(n=0 to ∞) na_nx^[(n-1))] =\)
After improving terms, we have:
\(∑(n=0 to ∞) n(n-1)a_nx^[(n-1)] + ∑(n=0 to ∞) na_nx^[n] =\)
Another, we compare the coefficients of like powers of x to zero, coming about in a boundless arrangement of conditions:
For n = 0: + a_0 = (condition 1)
For n = 1: + a_1 = (condition 2)
For n ≥ 2: n(n-1)a_n + na_n = (condition 3)
Disentangling condition 3, we have:
\(n^[2a]_n - n(a_n) =\)
n(n-1)a_n - na_n =
n(n-1 - 1)a_n =
(n(n-2)a_n) =
From equation 1, a_0 = 0, and from equation 2, a_1 = 0.
For n ≥ 2, we have two conceivable outcomes:
n(n-2) = 0, which gives n = or n = 2.
a_n = (minor arrangement)
So, the solution to the given differential equation is \(y = a_0x^{[0]} + a_1x^{[1]} + a_2x^{[2]}\), where a_0, a_1, and a_2 are constants.
Learn more about differential equations here:
https://brainly.com/question/28099315
#SPJ1
help meeeeeeeeeeeeeee pleaseeeeeee

Answers
Answer: 9.7 seconds
Step-by-step explanation:
\(16t^2 =1503\\\\t^2 =1503/16\\\\t=\sqrt{1503/16} \text{ } (t > 0)\\\\t \approx 9.7\)
I need help explanation if possible

Answers
Answer: Heyaa! :)
Your Answer Is.. 135.01°
Step-by-step explanation:
Convert to degrees, minutes, and seconds by leaving the number to the left of the decimal the same and manipulating the decimal.
Hopefully this helps you !
- Mattthew ~` (have a great day) <3
When two variables vary along with each other but the data points are loosely scattered around the line of best fit, the correlation is?
Answers
When two variables vary along with each other but the data points are loosely scattered around the line of best fit, the correlation is weak correlation.
We need to find the type of correlation when two variables vary along with each other but the data points are loosely scattered around the line of best fit.
What are scatterplots?A scatter plot helps find the relationship between two variables. This relationship is referred to as a correlation. Based on the correlation, scatter plots can be classified as follows.
Scatter plot for the positive correlationScatter plot for negative correlationScatter plot for null correlationA weak positive correlation indicates that, although both variables tend to go up in response to one another, the relationship is not very strong. A strong negative correlation, on the other hand, indicates a strong connection between the two variables, but that one goes up whenever the other one goes down.
Therefore, when two variables vary along with each other but the data points are loosely scattered around the line of best fit, the correlation is weak correlation.
To learn more about the scattered plot visit:
https://brainly.com/question/2655543.
#SPJ4