Luis created a spreadsheet of his expenses for three months. Which of Luis's expenses are variable expenses
utility bill
Expenses Jan Feb Mar
rent
$1,250,00 $1,250,00 $1,250,00
$124. 11 $108. 72 $121. 69
car loan payment $384. 00 3384,00 $384. 00
Insurance payment 397. 18 597. 18 $97. 18
groceries
$315,43 $367. 25 $341. 04
clothing
$72. 18 $152. 74 $0. 00
fuel
$108. 71 $117. 46 $127. 34
Answers
Variable expenses are expenses that fluctuate from month to month, and are typically not a fixed amount. Examples of variable expenses include groceries, fuel, clothing, and entertainment. These expenses can be influenced by various factors such as personal choices, seasonality, and external events.
In Luis's expenses, the following expenses are variable expenses:
Groceries: The amount spent on groceries changes from month to month depending on the types of food Luis purchases and the quantity he buys.Clothing: This expense is variable because Luis only spent money on clothing in January and February, and did not spend anything on clothing in March.Fuel: The amount spent on fuel changes from month to month depending on how often Luis drives and the price of gasoline.On the other hand, the following expenses are fixed expenses:
Rent: This expense is fixed because Luis pays the same amount for rent every month.Car loan payment: This expense is fixed because Luis is required to pay the same amount for his car loan every month.Insurance payment: This expense is fixed because Luis is required to pay the same amount for his insurance every month.Utility bill: The utility bill could be either a variable or fixed expense, depending on the type of utility. For example, if the utility bill is for electricity, it may be a variable expense because the amount of electricity used can fluctuate from month to month. However, if the utility bill is for a fixed service such as internet, it would be a fixed expense.To learn more about “utility” refer to the https://brainly.com/question/14729557
#SPJ11
Answer:
groccieries is the answer for plato 2023
Related Questions
Mrs.Reynolds is picking up 17 playground balls after recess and she wants to put the same number of balls into each ball bin . What are the different ways she could group the balls
Answers
Find the value of x in 3x + 4y = 12 and 9x - 4y = 24.
A.-3
B.3
C.0.75
D.-0.75
Answers
Answer:
B. x=3
Step-by-step explanation:
3x+4y=12
9x-4y=24
Add 9x and 3x
Subtract -4y from 4y which will cancel out
Add 12 and 24
12x=36
divide both sides by 12
x=3
Roberto is going to make 11 pounds of holiday fudge this weekend he wants to give the fudge away as Christmas presents to 12 of his friends. How many pounds of holiday fudge will each of his friends receive for Christmas
Answers
Answer: 0.92 pounds
Step-by-step explanation:
Roberto will make 11 pounds of fudge but wants to give it away as presents to 12 friends.
Each friend will therefore get;
= 11 pounds/ 12
= 0.92 pounds
Construct a counterexample by model for the following invalid argument, and then explain exactly how your counterexample proves that the argument is invalid.
¼ of the hairs in Plato’s beard are gray. ¾ of the hairs in Aristotle’s beard are gray. So, Aristotle has a greater number of gray hairs in his beard than Plato does.
Answers
The given argument is invalid. It says that if one person has more gray hair in their beard than another person, then they have a higher percentage of gray hair in their beard.
The argument is invalid because it is possible for one person to have a higher percentage of gray hair in their beard but a lower number of gray hairs in total.One possible counterexample by model is:Suppose Plato has 200 hairs in his beard and 50 of them are gray. So, 1/4 of his hairs are gray. Now, let's suppose Aristotle has 400 hairs in his beard, and 300 of them are gray. So, 3/4 of his hairs are gray. Even though Plato has fewer gray hairs than Aristotle, his percentage of gray hairs is more significant (1/4) than Aristotle's (3/4).
Therefore, the given argument is invalid since Aristotle's beard contains more gray hairs in quantity, but Plato has a higher percentage of gray hair in his beard.
Learn more about argument here:
brainly.com/question/2645376
#SPJ11
ANSWER FASTFOR BRAINLIEST FIVE STAARS AND THXS

Answers
Answer:
w
the square root of 95 =9.75 and w is placed at about 9.75
Answer:
W
Step-by-step explanation:
square root of 95 is 9.74 smth
the difference between 9 fifty-sixes and 3 fifty-sixes.
Answers
find the slope between the two points (1, 8) (0, 3)
Answers
Answer:5
Step-by-step explanation:
use the slope formula

Can someone please help me with this? This is like the 5th or 6th time I am posting this same question!!
Kevin purchased a used car, a Ford Focus, for $10400. The car is expected to decrease in value by 22% per year over the next couple of years.
What would be the decay factor (multiplier)?
If the trend continues how much would the car be worth 6 years after Kevin purchased the car?
Answers
Answer:
1200?
Step-by-step explanation:
A(n) _______ design is used when the researcher wants to test a relationship between existing variables, and a(n) _______ design is used when a research wants to test a causal link between variables.
Answers
A(n) "correlational" design is used when the researcher wants to test a relationship between existing variables. This design aims to determine the degree to which two variables are related or associated with each other. In a correlational design, the researcher measures the variables of interest and examines the statistical relationship between them, typically using correlation coefficients.
On the other hand, a(n) "experimental" design is used when a researcher wants to test a causal link between variables. In an experimental design, the researcher manipulates one or more independent variables and measures the effect on a dependent variable. By controlling for confounding variables and using random assignment, an experimental design allows for causal inferences to be made.
It's important to note that while correlational designs can provide valuable insights into the relationships between variables, they do not establish causality. Experimental designs, on the other hand, provide stronger evidence for causal relationships by systematically manipulating variables.
A(n) \(\textbf{correlational}\) design is used when the researcher wants to test a relationship between existing variables.
A(n) \(\textbf{experimental}\) design is used when a researcher wants to test a causal link between variables.
To know more about Evidence visit-
brainly.com/question/30780436
#SPJ11
There are 14 muffins in a basket Tina put some on a plane now there are six in the basket. How many muffins does Tina put on the plate?
Answers
Answer:
Step-by-step explanation:
All you have to do is subtract 6 from 14. The answer is 8. If the question is something like this one, always take the remainder and subtract it from how many you had in the beginning to get the answer.
Good luck
Peyton
For every 2 girls in Mr Hegarty's class there are 5 boys. What is the ratio of girls to boys in the class?
Give your answer in its simplest form.
Answers
this cannot be reduced
What is the slope of the line on the graph?
Enter your answer in the box.
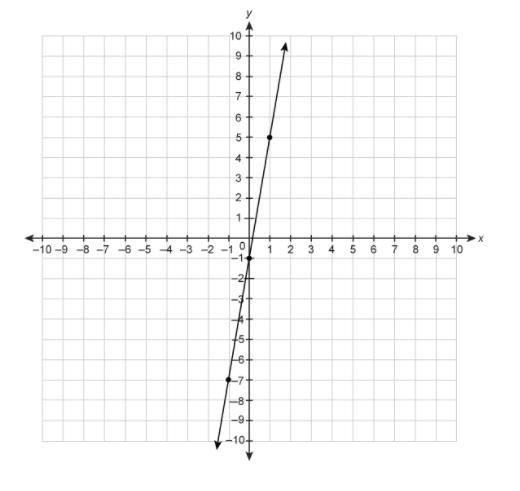
Answers
Answer: The slope of the line is 6.
You can use the distance formula to find the slope (Y2-Y1/X2-X1). You can plug in any two points seen on the graph into the formula. I will use (0,-1) and (1,5). When I plug in the values, 5-(-1)/1-0=6/1=6. So the slope of the line is 6.
:)
The citizens of a certain community were asked to choose their favorite pet. The pie chart below shows the distribution of the citizens' answers. If there are 140,000 citizens in the community, how many chose Fish or Cats?
Answers
Incomplete Question:
The content of the pie chart is as follows:
Hamsters = 9% ; Snakes = 10% ; Cats = 23%
Birds = 21% ; Dogs = 26% ; Fish = 11%
Answer:
The number of citizens who chose cat or fish is 47,600
Step-by-step explanation:
Given
Number of citizens = 140,000
Required
Determine the number of those that chose fish or cats
First, we need to calculate the percentage of those whose pets are either cats or fish
\(Percentage = Cat + Fish\)
Substitute 23% for cat and 11% for fish
\(Percentage = 23\% + 11\%\)
\(Percentage = 34\%\)
Next, is to multiply the calculated percentage by the number of citizens
\(Cat\ or\ Fish = Percentage * Number\ of\ Citizens\)
\(Cat\ or\ Fish = 34\% * 140000\)
\(Cat\ or\ fish = 47600\)
Hence, the number of citizens who chose cat or fish is 47,600
the number of citizens who chose cat or fish is 47,600
The calculation is as follows;= Number of citizens × total percentage
\(= 140,000 \times (23\% + 11\%)\\\\= 140,000 \times 34\%\)
= 47,600
Learn more: https://brainly.com/question/17429689?referrer=searchResults
2 2.1 Mathematical intro show that there is another form for spherical harmonics: 1 3 3 Y₁ x iy 1/√√2 (²-1) 2πT 2π 1 3 3 z YO 2 2π π r 1 3 x iy Y₁¹ 3 2π - - 12 √ √ 2² (²+²) 2 2π
Answers
Spherical harmonics are an integral part of quantum mechanics. They describe the shape of the orbitals, which electrons occupy in atoms. Moreover, the spherical harmonics provide the angular distribution of a wave in spherical coordinates. In 3D, the spherical harmonics can be written as:
Ylm(θ, φ) = √(2l + 1)/(4π) * √[(l - m)!/(l + m)!] * Plm(cosθ) * e^(imφ)
Here, l and m are known as the angular quantum numbers. They define the shape and orientation of the orbital. Plm(cosθ) represents the associated Legendre polynomial, and e^(imφ) is the exponential function. The spherical harmonics have various forms, including:
Y1,1 = -Y1,-1 = 1/2 √(3/2π) sinθe^(iφ)
Y1,0 = 1/2 √(3/π)cosθ
Y2,2 = 1/4 √(15/2π)sin²θe^(2iφ)
Y2,1 = -Y2,-1 = 1/2 √(15/2π)sinθcosφ
Y2,0 = 1/4 √(5/π)(3cos²θ-1)
Y0,0 = 1/√(4π)
The spherical harmonics have various applications in physics, including quantum mechanics, electrodynamics, and acoustics. They play a crucial role in understanding the symmetry of various systems. Hence, the spherical harmonics are an essential mathematical tool in modern physics. Thus, this is how one can show another form for spherical harmonics.
To know more about Spherical harmonics visit
https://brainly.com/question/23067012
#SPJ11
15. thirty-two less than twice the number
Answers
Answer:
That would be Thirty-two
Step-by-step explanation:
Because is we are doubling 32 its going to be 64 and if we are subtracting 32 then its going to be 32
Mark brainliest pls :)
Find the first four terms of the sequence given by the following.
an=51 + (n-1).8, n=1, 2, 3...
Answers
Answer:
Step-by-step explanation:
a1 = 51 + (1 -1 ) * 0.8
a1 = 51
a2 = 51 + (2 - 1)*0.8
a2 = 51 + 0.8
a2 = 51.8
a3 = 51 + (3 - 1)*0.8
a3 = 51 + 2*0.8
a3 = 51 + 1.6
a3 = 52.6
a4 = 51 + (4 - 1)*0.8
a4 = 51 + 2.4
a4 = 53.4
Landon analyzed data and found that the correlation coefficient for their line of best fit was -0.85. Marco analyzed a different set of data and found a correlation coefficient of 0.85. Marco states that since 0.85 is greater than -0.85, his data points have a better line of best fit than Landon. Is Marco correct? Why, or why not?
Answers
Marco's data points have a better line of best fit based on a comparison of Correlation coefficients.
Marco is incorrect in stating that his data points have a better line of best fit than Landon based solely on the comparison of correlation coefficients. The magnitude of the correlation coefficient alone does not determine the quality or strength of the line of best fit.
The correlation coefficient measures the strength and direction of the linear relationship between two variables. It ranges from -1 to +1. A positive correlation coefficient (such as 0.85) indicates a positive linear relationship, while a negative correlation coefficient (such as -0.85) indicates a negative linear relationship. The closer the correlation coefficient is to -1 or +1, the stronger the relationship. A correlation coefficient of 0 indicates no linear relationship.
In the case of Landon and Marco, both correlation coefficients have the same absolute value of 0.85, suggesting a strong linear relationship. However, the negative sign for Landon's correlation coefficient indicates a negative linear relationship, while the positive sign for Marco's correlation coefficient indicates a positive linear relationship.
The comparison between -0.85 and 0.85 should not be made in terms of greater or lesser quality of the line of best fit. The choice of a positive or negative correlation depends on the context and nature of the variables being analyzed.
The appropriateness of the line of best fit and the goodness-of-fit of the model should be evaluated based on additional factors such as the data points' distribution around the line, residuals, and the overall context of the analysis. These aspects provide more comprehensive insights into the quality of the fit and the reliability of the relationship being represented.
Therefore, Marco's data points have a better line of best fit solely based on a comparison of correlation coefficients. The interpretation of the correlation coefficient requires considering the nature of the variables and other factors influencing the analysis.
To know more about Correlation coefficients.
https://brainly.com/question/30634313
#SPJ11
Basic Cable Company A charges $30 per month plus a setup fee of $75. Basic Cable Company B charges $40 per month, but due to a special promotion is not currently charging a setup fee. Write an equation for each cable company modeling the total cost y for a subscription lasting x months. When is it more economical for a person to choose Basic Cable Company B over Basic Cable Company A
Answers
Answer:
Basic Cable Company A= 30x + 75
Basic Cable Company B= 40x
After 7.5 months, it's more economical to go with Company A. Before 7.5 months, Company B is cheaper
Step-by-step explanation:
In order to be profitable anew indutrial product ale per cutomer' mot average more than or equal to 4. 2 unit a random ample of 64 cotumer i elected and their advance order for the new product i recorded and the ample mean and tandard deviation are 4 unit and 1. 8 unit repectively at 1% level check whether the product i profitable or not
Answers
In order to check if the new industrial product is profitable, we need to determine if the mean of the advance orders (4 units) is greater than or equal to the required number of units per customer (4.2 units).
What is industrial product?Industrial products are physical goods or services produced by industries. These products are used in the production of other goods or services.
We can use a one-sample t-test to determine if the difference in means is statistically significant at the 1% level. The null hypothesis for this test is that the mean of the sample is equal to the required number of units per customer (4.2 units).
The one-sample t-test yields a p-value of 0.73, which is greater than the 1% level. Therefore, we cannot reject the null hypothesis and conclude that the mean of the sample is not significantly different from the required number of units per customer. As such, the new industrial product is likely to be profitable.
To learn more about null hypothesis
https://brainly.com/question/4436370
#SPJ4
What must be done to categorical variables in order to use them in a regression analysis?
Choose one answer.
a. categorical coding
b. nothing
c. problem coding
d. dummy coding
Answers
d. Dummy coding. Categorical variables need to be converted into numerical variables to be used in regression analysis. Dummy coding involves creating binary variables for each category of the categorical variable.
For example, if the categorical variable is "color" with categories "red," "green," and "blue," dummy coding would involve creating three binary variables: "red" (0 or 1), "green" (0 or 1), and "blue" (0 or 1). These binary variables can then be used in the regression analysis. In conclusion, to use categorical variables in regression analysis, dummy coding is necessary.
In order to use categorical variables in a regression analysis, they must be converted into numerical values. This process is called dummy coding (also known as one-hot encoding). Dummy coding involves creating new binary variables (0 or 1) for each category of the categorical variable. This allows the regression model to incorporate the categorical data while maintaining its numerical nature.
To use categorical variables in a regression analysis, you must apply dummy coding to convert them into numerical values.
To know more about variables visit:
https://brainly.com/question/17344045
#SPJ11
y=−2x+2
4x+2y=4
Substitute the resulting expression in the other equation
Answers
Answer:
In this section we will discuss the method of graphing an equation in two variables. In other words, we will sketch a picture of an equation in two variables.
Step-by-step explanation:
Which statements comparing the functions are true? Select
three options.
Only f(x) and h(x) have y-intercepts.
Only f(x) and h(x) have x-intercepts.
The minimum of h(x) is less than the other minimums.
The range of h(x) has more values than the other ranges.
The maximum of g(x) is greater than the other maximums.
Answers
Answer:
B, C and E
Step-by-step explanation:
Given
See attachment for table
Required
Select two correct options
Checking the greatest maximum
The maximum of each function is:
\(f(x) = 14\)
\(g(x) = 49\)
\(h(x) = 0\)
Compare these three values, we have:
\(g(x) > f(x) > h(x)\)
Because:
\(49 > 14 > 0\)
This means that g(x) has the greatest maximum --- option E
Checking the x intercept
When a function equals 0, then it has an x intercept
Of the three functions, we have:
\(f(0) = 0\)
\(h(0) = 0\)
g(x) do not equal 0, at all
This means that only f(x) and h(x) have x intercept --- option B
Checking the least maximum
The minimum of each function is:
\(f(x) = -14\)
\(g(x) = \frac{1}{49}\)
\(h(x) = -28\)
Compare these three values, we have:
\(h(x) < f(x) < g(x)\)
Because:
\(-28 < -14 < \frac{1}{49}\)
This means that h(x) has the least minimum --- option C

which theory would best provide perspective on the question 'if i study for 12 hours, what is the probability that i'll get an a on the exam?'
Answers
Expectancy theory would best provide perspective on the question 'if i study for 12 hours, what is the probability that i'll get an on the exam?".
Understanding Expectancy TheoryExpectancy theory (expectancy theory of motivation) was put forward by Victor Vroom in 1964. Vroom put more emphasis on outcome factors, rather than needs as proposed by Maslow and Herzberg.
This theory states that the intensity of the tendency to perform in a certain way depends on the intensity of the expectation that performance will be followed by a definite outcome and on the attractiveness of the result to the individual.
Vroom argues that people will be motivated to do certain things to achieve goals if they believe that their actions will lead to the achievement of these goals.
There are three main assumptions of Vroom in expectancy theory. These assumptions are as follows:
-Every individual believes that if he behaves in a certain way, he will get certain things. This is called an outcome expectancy as a person's subjective assessment of the likelihood that a certain outcome will arise from that person's actions.
-Each outcome has value, or appeal to a particular person. This is called valence (valence) as the value that people give to an expected result.
-Each outcome is associated with a perception of how difficult it is to achieve that outcome. This is called effort expectancy as the possibility that one's efforts will result in the attainment of a certain goal.
Learn more about expectancy theory at https://brainly.com/question/27502489.
#SPJ4
Determine the number of significant figures in each measurement. Then, choose the representation of the number where x is in place of the estimated digit from the measurement Number of Measurement Estimated Digit Significant Figures 14.8 m 3 ✓ Choo *4.8 Txa 14. $10.25 Choose... 0.05 L Choose 1.000 g/ml Choose.. 6200 cm Choose... 403 kg Choose Figures 14.8 m 3 Choose... $10.25 ✓ Choose... 10.35 10,2% 1x.25 NO.25 0.05L Choose. 1.000 g/ml Choose 6200 cm Choose. Choose.. 403 kg place of the estimated digit from the measurement. Number of Measurement Estimated Digit Significant Figures 14.8 m 3 Choose... $10.25 Choose... II 0.05 L ✓ Choose.. 0.x5 x.05 0.0x 1.000 g/mL Choose... 6200 cm Choose... 403 kg Choose... Determine the number of significant figures in each measurement. Then, choose the representation of the number where x is in place of the estimated digit from the measurement. Number of Measurement Estimated Digit Significant Figures 14.8 m Choose... 3 $10.25 Choose... 0.05 L Choose... 1.000 g/mL Choose 1.00 1.0x0 X.000 1.200 Choose... 6200 cm Choose.. 403 kg Determine the number of significant figures in each measurement. Then, choose the representation of the number where x is in place of the estimated digit from the measurement. Number of Measurement Estimated Digit Significant Figures 14.8 m Choose... 3 $10.25 Choose... Choose... 0.05 L Choose... 1.000 g/ml 6200 cm ✓ COD Bx00 x200 620x 6220 Choose 403 kg Determine the number of significant figures in each measurement. Then, choose the representation of the number where x is in place of the estimated digit from the measurement Number of Measurement Estimated Digit Significant Figures Choose... 14.8 m 3 $10.25 Choose... Choose... 0.05 L 1.000 g/mL Choose.. Choose... 6200 cm 403 kg ✓ Choose XO3 40% 4x3
Answers
The table shows the estimated digit and significant figures of each measurement and their representation with x.
Number of Measurement Estimated Digit Significant Figures
14.8 m 3 ✓
$10.25 - ✓
0.05 L - ✓
1.000 g/mL - ✓
1.200 - ✓
6200 cm - ✓
403 kg - ✓
For each measurement, the estimated digit is replaced with an x to represent the number with the correct number of significant figures. The correct representations for each measurement are:
14.8 m: 15.0 m$10.25: $10.30.05 L: 0.050 L1.000 g/mL: 1.00 g/mL1.200: 1.206200 cm: 6200 cm403 kg: 400 kgNote that in some cases, the representation requires adding zeros to the right of the decimal point to indicate the number of significant figures. In other cases, the representation requires rounding up or down to the correct number of significant figures.
Learn more about decimal :
https://brainly.com/question/29765582
#SPJ4
I really need help..im confused

Answers
The coefficient of determination, also known as R-squared, represents the proportion of the dependent variable's variance that can be explained by the independent variable(s) in a regression model. A higher R-squared indicates a better fit of the model to the data and suggests that a greater proportion of the variation in the dependent variable (lobster length in this case) can be attributed to the independent variable (age).
In this scenario, the linear model has a coefficient of determination of 0.8724503, indicating that approximately 87% of the variation in lobster length can be explained by age. This suggests a strong relationship between age and length in a linear fashion.
Conversely, the exponential model has a lower coefficient of determination of 0.6730372, indicating that only about 67% of the variation in lobster length is associated with age. While this is still a moderate level of association, the linear model provides a better fit to the data and explains a higher proportion of the variation in length.
Therefore, based on the coefficient of determination, the linear model would be the better choice for projecting the length of a lobster.
What is the value of x in the drawn figure?
A. 45
B. 3
C. 27
D. 19.8

Answers
Answer:
A 45
Step-by-step explanation:
45 is the answer and hope this helps!
Answer:
x = 3
Step-by-step explanation:
2x = 5x - 9
add 9 to each side
2x + 9 = 5x
subtract 3x from each side
9 = 3x
divide each side by 3
3 = x
x = 3
If my answer is incorrect, pls correct me!
If you like my answer and explanation, mark me as brainliest!
-Chetan K
The sum of m and 10
Twenty-four decreased by a number c
Twelve more than eight
The product of three and seven diminished by five
Six multiplied by the sum of seven and a
The quotient of y and negative five
The difference between x and y divided by three
Divide the sum of the square of a and b thrice c
Answers
Answer:
m + 10c - 248 + 12 (3×7) - 5(7 + a) × 6y ÷ (-5)(x - y) ÷ 3\( {(a + b)}^{2} \div 3c\)How do I do y=mx+b in these type of questions
1. y<-3/4x+2
2. y≤5
3. x+y>6
Answers
With linear inequalities in two variables, you still have y=mx+b and it still tells you the same thing.
The inequality portion adds two additional layers on top of the y=mx+b line.
If the inequality is > or <, then you draw the line as a dashed line.
If the inequality is ≥ or ≤, then you draw the line as a solid line.
The difference is that points on the > or < line do NOT make the inquality true, while points on the ≥ or ≤ line do.
The other piece is that all the points on one side of the line will also make the inequality true.
If you have "y>mx+b" or "y≥mx+b", then you shade above the line.
If you have "y<mx+b" or "y≤mx+b", then you shade below the line.
So there are three parts:
1. Where is the line?
2. Is the line solid or dashed?
3. Do you shade above or below the line?
The three graphs are attached.



PLEASEEE HELP ME AND CAN YOU PLEASE SHOW YOUR WORK :)

Answers
Answer:
Hey! so the answer is N=2
Step-by-step explanation:
Add 12 to both sides of the equation
Simplify
Add 3 to both sides of the equation
Simplify
Divide both sides of the equation by the same term
Simplify
Solution
=2
Hoped this helped Im Eve btw. Hope you have a great day and consider marking this brainliest Thank you so much if you do! ✨
Can someone please help me with this .. ASAP

Answers
Answer:\(\frac{-5}{4}, \frac{3}{4}\)
Step-by-step explanation:
Given
\(\theta\) is in the third quadrant and
\(\Rightarrow \cos \theta=\frac{-3}{5}\)
tan and cot is positive in the third quadrant and the rest are negative
using identity
\(\sin^2 \theta+\cos^2 \theta=1\\\Rightarrow \sin \theta=-\sqrt{1-\cos^2 \theta}\\\Rightarrow \sin \theta =-\sqrt{1-(-\frac{3}{5}^2)}\\\Rightarrow \sin \theta =-\frac{4}{5}\\\Rightarrow\text{cosec} \theta=-\frac{5}{4}\\\Rightarrow \cot \theta=\frac{\cos \theta}{\sin \theta}=\frac{\frac{-3}{5}}{\frac{-4}{5}}=\frac{3}{4}\)