It costs $7.50 to enter a petting zoo. Each cup of food to feed the animals is $2.50. If you have $12.50, how many cups can you buy?
Answers
Answer:
2
steps
7.50+2.50=10.00
10.00+2.50=12.50
so you have 2 cups of food u can buy
Related Questions
Formula: \(t = 50 + \frac{n - 40}{4} \)Where T is temperature in Fahrenheit and N is a number of chirps per minute. If T=60°F, find the number of chirps per minute.
Answers
In order to find the value of N in the equation when T = 60, we just need to apply the value of T and then calculate the value of N.
So we have that:
\(\begin{gathered} T=50+\frac{N-40}{4} \\ 60=50+\frac{N-40}{4} \\ \frac{N-40}{4}=10 \\ N-40=40 \\ N=80 \end{gathered}\)So the number of chirps per minute is 80
C.Given the figure on the right. Answer the following.
Another Plzz

Answers
Answer:
10
Step-by-step explanation:
Remark
Technically, we can't. We have no way of knowing what kind of figure we are working with. We can say to you that if this is not at least a parallelogram then no answer is possible.
Opposite sides of a parallelogram are equal.
Equation
2x = x + 5
Solution
Subtract x from each side
2x - x = 5
x = 5
HE = 2x
HE = 2*5
HE = 10
What is the y-value of the solution to the system of equations? 3x 5y = 1 7x 4y = −13
Answers
The solution to the system of equations is x = -3 and y = 2. The y-value of the solution is 2
To find the y-value of the solution to the system of equations, we can solve the system using any suitable method such as substitution or elimination.
Given system of equations:
3x + 5y = 1
7x + 4y = -13
Let's use the method of elimination to solve the system:
Multiply equation 1 by 4 and equation 2 by 5 to make the coefficients of y in both equations equal:
4(3x + 5y) = 4(1) --> 12x + 20y = 4
5(7x + 4y) = 5(-13) --> 35x + 20y = -65
Now, subtract equation 1 from equation 2 to eliminate the y term:
(35x + 20y) - (12x + 20y) = -65 - 4
35x - 12x = -69
23x = -69
x = -69/23
x = -3
Substitute the value of x into equation 1 to find y:
3(-3) + 5y = 1
-9 + 5y = 1
5y = 1 + 9
5y = 10
y = 10/5
y = 2
Therefore, the solution to the system of equations is x = -3 and y = 2. The y-value of the solution is 2.
For more details of equations :
https://brainly.com/question/21620502
#SPJ4
Raphael i h year old
a) Lily' age i Raphael' age divided by 3. Write an expreion in term of h for Lily' age
b) An expreion for Ethan' age i h6. Write a entence to decribe how Ethan' age compare with Raphael' age
Answers
a) When Lily's age is 20, and Raphael's age is divided by 3 then the expression of Lily's age in terms of h is h < 10.
b) Ethan's age is half of Raphael's age therefore, Ethan's age is half Raphael's age.
a) If Raphael is twice as old as his sister Lily, we can represent their ages as 2h and h, respectively, where h is Lily's age. The sum of their ages is less than 30, so we can write the equation:
2h + h < 30
Combining like terms, we get:
3h < 30
Dividing both sides by 3, we get:
h < 10
This is an expression of Lily's age in terms of h.
b) If Ethan's age is 16, and Raphael's age is twice Ethan's age, we can represent Raphael's age as 2 × 16 = 32.
Ethan's age is 16, which is half of Raphael's age of 32. Therefore, Ethan's age is half of Raphael's age.
Learn more about the age at
https://brainly.com/question/11284412?referrer=searchResults
#SPJ4
The question is -
Raphael is twice as old as his sister. The sum of their ages is less than 30.
a) Lily's age is 20, and Raphael's age is divided by 3. Write an expression in terms of h for Lily's age.
b) An expression for Ethan's age 16. Write a sentence to describe how Ethan's age compares with Raphael's age.
Solve the system of equations:
8x + 3y = 13
3x + 2y = 11
Answers
Answer:
1.x=13/8-3y/8
2.x=11/3-2y/3
Step-by-step explanation:
On its municipal website, the city of Tulsa states that the rate it charges per 5 CCF of residential water is $21.62. How do the residential water rates of other U.S. public utilities compare to Tulsa's rate? The data shown below ($) contains the rate per 5 CCF of residential water for 42 randomly selected U.S. cities.10.38 9.08 11.7 6.4 12.32 14.43 15.4610.02 14.4 16.08 17.5 19.08 17.88 12.7516.7 17.25 15.54 14.7 18.81 17.89 14.818.32 15.95 26.75 22.22 22.66 20.88 23.3518.95 23.6 19.16 23.65 27.7 26.95 27.0426.89 24.58 37.76 26.41 38.91 29.36 41.55(a)Formulate hypotheses that can be used to determine whether the population mean rate per 5 CCF of residential water charged by U.S. public utilities differs from the $21.62 rate charged by Tulsa. (Enter != for ≠ as needed.)H0:Ha:(b)What is the test statistic for your hypothesis test in part (a)? (Round your answer to three decimal places.)What is the p-value for your hypothesis test in part (a)? (Round your answer to four decimal places.)(c)At α = 0.05, can your null hypothesis be rejected? What is your conclusion?Do not reject H0. The mean rate per 5 CCF of residential water throughout the United States differs significantly from the rate per 5 CCF of residential water in Tulsa.Reject H0. The mean rate per 5 CCF of residential water throughout the United States does not differ significantly from the rate per 5 CCF of residential water in Tulsa.Do not reject H0. The mean rate per 5 CCF of residential water throughout the United States does not differ significantly from the rate per 5 CCF of residential water in Tulsa.Reject H0. The mean rate per 5 CCF of residential water throughout the United States differs significantly from the rate per 5 CCF of residential water in Tulsa.(d)Repeat the preceding hypothesis test using the critical value approach.State the null and alternative hypotheses. (Enter != for ≠ as needed.)H0:Ha:Find the value of the test statistic. (Round your answer to three decimal places.)State the critical values for the rejection rule. Useα = 0.05.(Round your answers to three decimal places. If the test is one-tailed, enter NONE for the unused tail.)test statistic≤test statistic≥State your conclusion.Do not reject H0. The mean rate per 5 CCF of residential water throughout the United States differs significantly from the rate per 5 CCF of residential water in Tulsa.Reject H0. The mean rate per 5 CCF of residential water throughout the United States does not differ significantly from the rate per 5 CCF of residential water in Tulsa.Do not reject H0. The mean rate per 5 CCF of residential water throughout the United States does not differ significantly from the rate per 5 CCF of residential water in Tulsa.Reject H0. The mean rate per 5 CCF of residential water throughout the United States differs significantly from the rate per 5 CCF of residential water in Tulsa.
Answers
The null hypothesis for the data will be 21.62 and the alternate hypothesis is 2.02 for the p-value for the data is 0.2253 .
The charge at which anything happens is referred to as the velocity at which it happens.
The required details for mean rate :
(a) H0: µ = 21.62
Ha: µ ≠ 21.62
(b) t = -1.231
p-value = 0.2253
(c) Stop rejecting H0 right now. No longer significantly different from the domestic water tariff in Tulsa, the suggested household water charge per five CCF for the entire USA.
(d) H0: µ = 21.62
Ha: µ ≠ 21.62
t = -1.231
check statistic ≥ 2.020
Don't dismiss H0 any longer. The suggested five CCF residential water charge for the entirety of the USA is no longer significantly different from the five CCF residential water tariff in Tulsa.
The P-value is higher at 0.05, the level of significance. The impact in this instance is negligible. The attempt to reject the null hypothesis failed.
The conclusion is that there is insufficient statistical support to determine whether other American cities have a different mortality rate than Tulsa.
The crucial values for t at this level of significance are t=2.019.
Given that the statistic t = -1.15 is inside the acceptance range in this case, the null hypothesis is not disproved.
to learn more about null hypothesis visit:
https://brainly.com/question/16261813
#SPJ4
Please help me! Picture below!!

Answers
Answer:
The answer is 256
I took a sample of the grade point averages for students in my class. For the 25 students, the standard deviation of grade points was 0.65 and the mean was 2.89. The standard error for the sample was:
A)0.026
B)0.13
C)0.578
Answers
The standard error for the given sample of grade point average is B) 0.13.
The standard error for the given sample of grade point averages can be calculated using the formula: standard error = standard deviation / √(sample size). In this case, the standard deviation is 0.65 and the sample size is 25.
So, the standard error = 0.65 / √25 = 0.13.
Therefore, the correct answer is B) 0.13.
The standard error is a measure of the precision of the sample mean as an estimate of the population mean. It represents the average amount of variation or uncertainty we can expect in the sample mean compared to the true population mean. A smaller standard error indicates a more precise estimate of the population mean.
In this case, with a standard error of 0.13, it means that on average, the sample mean of grade point averages is expected to deviate from the true population mean by approximately 0.13. This provides an indication of the accuracy of the sample mean as an estimate of the population mean. The standard error is useful in statistical inference and hypothesis testing, as it helps determine the reliability of the sample mean in making inferences about the population.
Learn more about standard error here:
https://brainly.com/question/13179711
#SPJ11
a/2-8=-4
I have no idea how to do this!!
Answers
Answer:
a = 8
Step-by-step explanation:
a ÷ 2 - 8 + 8 = - 4 + 8
a ÷ 2 = 4
a ÷ 2 × 2 = 4 × 2
a = 8
Answer:
a = 8
Step-by-step explanation:
Given
\(\frac{a}{2}\) - 8 = - 4 ( add 8 to both sides )
\(\frac{a}{2}\) = 4 ( multiply both sides by 2 to clear the fraction )
a = 8
Can I get some help..please?

Answers
Answer:
-2 and 21/50
Step-by-step explanation:
PEMDAS says that paranthases go first, so we solve 2 and 1/5 minus 33/12. 2 and 1/5 simplifies to the improper fraction, 11/5. Then we find a common denominater between 11/5 and 33/12 to get 60. 11/5=132/60, and 33/12=165/60. (132/60)-(165/60)=-33/60. Then we multipl that by 4 and 2/5, which can simplify to the improper fraction, 22/5. (22/5)*(-33/60) is -726/300, and simplifies to -2 and 21/50. Hope this helps!
(a) Find all the roots (real and complex) of f(1) = 14 + 3r3 – 7x2 – 71 +2. (b) Using the Binomial Theorem expand and simplify: (x + 5y) 4. ALGEBRA (a) Find the sum 54(2)k-1. You may leave your answer unsimplified. (b) Expand completely using properties of logarithms: log2 y V1-1 z(y2 +1) 5. VERIFYING/SHOWING sec-1 Verify the trigonometric identity: secar = sin
Answers
(a) The roots of the given equation f(1) = 14 + 3r3 – 7x2 – 71 +2 are as follows: f(1) = 14 + 3r3 – 7x2 – 71 +2= 3r3 – 7x2 – 55.
The above equation doesn't give any real or complex roots, we need to be given an equation to find the roots. Thus, no solution can be given.
(b) Using the Binomial Theorem, we can expand and simplify the expression (x + 5y)4 as follows: (x + 5y)4 = C(4, 0)x4(5y)0 + C(4, 1)x3(5y)1 + C(4, 2)x2(5y)2 + C(4, 3)x1(5y)3 + C(4, 4)x0(5y)4= x4 + 20x3y + 150x2y2 + 500xy3 + 625y4. Thus, the expansion and simplification of the given expression are x4 + 20x3y + 150x2y2 + 500xy3 + 625y4. ALGEBRA. (a) The sum of the given series 54(2)k-1 can be calculated as follows: S = 54(2)k-1= 54 * 2k-1= (22 * 3)k-1= 3k. Thus, the sum of the given series is 3k.(b) Using the properties of logarithms, we can expand the expression log2 y √(1-1/z(y2+1)) as follows:log2 y √(1-1/z(y2+1))= log2 y (y2+1)-1/2/z-1/2= (1/2)log2 (y2+1) - (1/2)log2 z - (1/2)log2 (y2+1). Thus, the expression can be expanded completely using the properties of logarithms as (1/2)log2 (y2+1) - (1/2)log2 z - (1/2)log2 (y2+1).VERIFYING/SHOWING. To verify the given trigonometric identity secα = sin(π/2 - α), we can use the following steps: secα = 1/cosαand sin(π/2 - α) = cosαHence, secα = sin(π/2 - α)Thus, the given trigonometric identity is verified.
Know more about roots here:
https://brainly.com/question/30265920
#SPJ11
a 95 confidence interval for p1-p2 is (-0.185, -0.093). explain how the confidence interval provides the same information as the significance test in part a
Answers
We can conclude that the difference between p1 and p2 is statistically significant at the 5% level of significance.
The confidence interval and significance test in part A both provide similar information. The significance test in part A tests if the difference between p1 and p2 is statistically significant, while the confidence interval provides an estimated range of values for the true difference between p1 and p2 with a certain degree of confidence (95% in this case).A confidence interval is a range of values that we believe will include a population parameter with a specified level of confidence.
It can be computed to estimate the population mean or the difference between two population means, such as p1 and p2.In contrast, a significance test assesses whether the difference between two population proportions is statistically significant.
The test calculates a p-value, which is the likelihood of obtaining the observed difference between two proportions, assuming the null hypothesis (that there is no difference between the two proportions) is true. A p-value less than the level of significance (usually 0.05) indicates that the difference between the two proportions is statistically significant, while a p-value greater than the level of significance indicates that the difference is not statistically significant.
Both the confidence interval and the significance test inform us about the difference between two population proportions. The confidence interval provides a range of plausible values for the difference, while the significance test tells us whether the difference is statistically significant or not. In this particular case, since the confidence interval does not contain zero,
Learn more about Significance
brainly.com/question/31037173
#SPJ11
11. Engineering The maximum load for a certain elevator is 2000 pounds. The total
weight of the passengers on the elevator is 1400 pounds. A delivery man who weighs
243 pounds enters the elevator with a crate of weight w. Write, solve, and graph an
inequality to show the values of w that will not exceed the weight limit of the elevator.
Answers
The inequality to show the values of [w] that will not exceed the weight limit of the elevator is w + 1643 ≤ 2000. On solving the inequality, we get w ≤ 357. The graph of the inequality is attached.
What is inequality?In mathematics, an inequality is a relation which makes a non-equal comparison between two numbers or other mathematical expressions. It is used most often to compare two numbers on the number line by their size.An inequality is a mathematical relationship between two expressions and is represented using one of the following -≤ : less than or equal to
≥ : greater than or equal to
< : less than
> : greater than
≠ : not equal to
Given is the maximum load for a certain elevator is 2000 pounds. The total weight of the passengers on the elevator is 1400 pounds. A delivery man who weighs 243 pounds enters the elevator with a crate of weight [w].
We can write the inequality as follows -1400 + 243 + w ≤ 2000
w + 1643 ≤ 2000
Solving the inequality, we get -w + 1643 ≤ 2000
w ≤ 2000 - 1643
w ≤ 357
Refer to the graph attached.Therefore, the inequality to show the values of [w] that will not exceed the weight limit of the elevator is w + 1643 ≤ 2000. On solving the inequality, we get w ≤ 357. The graph of the inequality is attached.
To solve more questions on inequalities, we get -
https://brainly.com/question/11897796
#SPJ1

find the vertex of f(x)=-(x+4)^2+2
Answers
Answer:
the vertex is (-4,2), I hope this helps :)
Step-by-step explanation:
Emma's luggage may be lost with probability p = 0.1. The luggage and its content are estimated to be worth 316.05. Emma's utility insure against the loss of the luggage, what is the maximum insurance premium I that Emma would be willing to pay?
Answers
Emma's luggage may be lost with probability p = 0.1. The luggage and its content are estimated to be worth 316.05. Emma's utility insures against the loss of the luggage. What is the maximum insurance premium I that Emma would be willing to pay?
Solution:To calculate Emma's maximum insurance premium, let's start by calculating her expected utility if she doesn't insure her luggage.U (no insurance) = 0.9 x U (316.05) + 0.1 x U (0)where U (316.05) is Emma's utility function for 316.05 value, and U (0) is Emma's utility function for a loss of the luggage. Emma has not insured her luggage, hence, if it gets lost, she will get 0 value for it.A sum of 316.05 is worth more than 0, Emma will still get a certain amount of utility, which will be larger than 0.
Therefore, Emma's utility function is likely to be positive, so let us assume that U (0) = 0.If we plug this information into the above equation, we will have:U (no insurance) = 0.9U (316.05) + 0.1 × 0 = 0.9U (316.05)Hence, Emma's expected utility, if she doesn't insure her luggage, will be 0.9U (316.05).However, if Emma chooses to insure her luggage, she will pay the insurance premium I. If the luggage gets lost, she will get reimbursed by the insurance company for 316.05. Her expected utility function, if she insures her luggage, will be:
U (insurance) = 0.9U (316.05 – I) + 0.1U (316.05)Where U (316.05 – I) is Emma's utility function for 316.05 – I value. Emma will get this amount if the luggage is not lost, but she has to pay the premium I.If we compare Emma's expected utility when she insures her luggage and when she doesn't insure her luggage, we will have the following inequality:
U (insurance) ≥ U (no insurance)0.9U (316.05 – I) + 0.1U (316.05) ≥ 0.9U (316.05)Let us solve this inequality:0.9U (316.05 – I) + 0.1U (316.05) ≥ 0.9U (316.05)0.9U (316.05 – I) ≥ 0.8U (316.05)U (316.05 – I) ≥ 0.89U (316.05)Since U (316.05 – I) is a decreasing function, it will get smaller as I gets larger.
Hence, to maximize Emma's expected utility, we need to minimize the insurance premium I that she pays to the insurance company.If Emma doesn't insure her luggage, her expected utility will be 0.9U (316.05)Emma will choose to insure her luggage if her expected utility is larger if she insures her luggage.U (insurance) = 0.9U (316.05 – I) + 0.1U (316.05)0.9U (316.05 – I) ≥ 0.8U (316.05)U (316.05 – I) ≥ 0.89U (316.05)Emma will choose to insure her luggage if her expected utility is larger if she insures her luggage. Hence,Emma's maximum insurance premium I that Emma would be willing to pay is $31.35.
If Emma chooses to insure her luggage, she will pay the insurance premium I. Her expected utility function, if she insures her luggage, will be U (insurance) = 0.9U (316.05 – I) + 0.1U (316.05). Emma will choose to insure her luggage if her expected utility is larger if she insures her luggage. Therefore, Emma's maximum insurance premium I that Emma would be willing to pay is $31.35. The utility function is considered decreasing as Emma has to pay more premium.
To know more about utility function :
brainly.com/question/30652436
#SPJ11
Find an equation for the hyperbola with foci (0,±5) and with asymptotes y=± 3/4 x.
Answers
The equation for the hyperbola with foci (0,±5) and asymptotes y=± 3/4 x is:
y^2 / 25 - x^2 / a^2 = 1
where a is the distance from the center to a vertex and is related to the slope of the asymptotes by a = 5 / (3/4) = 20/3.
Thus, the equation for the hyperbola is:
y^2 / 25 - x^2 / (400/9) = 1
or
9y^2 - 400x^2 = 900
The center of the hyperbola is at the origin, since the foci have y-coordinates of ±5 and the asymptotes have y-intercepts of 0.
To graph the hyperbola, we can plot the foci at (0,±5) and draw the asymptotes y=± 3/4 x. Then, we can sketch the branches of the hyperbola by drawing a rectangle with sides of length 2a and centered at the origin. The vertices of the hyperbola will lie on the corners of this rectangle. Finally, we can sketch the hyperbola by drawing the two branches that pass through the vertices and are tangent to the asymptotes.
Know more about equation for the hyperbola here:
https://brainly.com/question/30995659
#SPJ11
Let n be the largest integer for which 14n has exactly 100 digits. Counting from right to left, find the 68th digit of n
Answers
Counting from right to left, find the 68th digit of n is 10.
An integer, is a whole number that can be positive, negative, or zero and is not a fraction. Integer examples include: -5, 1, 5, 8, 97, and 3,043. 1.43, 1 3/4, 3.14, and other numbers that are not integers are some examples.
The largest integer with exactly 100 digits is the integer that consists of 100 copies of the digit 9.
This integer is equal to 10100 = 10
To know more about integers visit the link:
https://brainly.com/question/15276410?referrer=searchResults
#SPJ4
3×-5=16 and 3×=21
the first equation is a true statement for a certain value of x.
can you explain why the second equation must also be true for the same value of x?
Answers
Step-by-step explanation:
because we can also find out the value of x in second equation like this
3x=21
x=21/3
x=7
Answer:
We conclude that x = 7 must be true for the second equation because it will also satisfy the second equation.
Step-by-step explanation:
Given the first equation
3x-5 = 16solving the equation
3x-5 = 16
adding 5 to both sides
3x-5+5 = 16+5
3x = 21 ∵ 3x = 21 is the 2nd equation
divide bothe sides by 3
3x/3 = 21/3
x = 7
Please notice that when simplifying 3x-5 = 16, the moment we reach 3x=21, we can determine that it represents the same equation.
In other words, whatever the value of x we will get, it will satisfy both equations.
Therefore, we conclude that x = 7 must be true for the second equation because it will also satisfy the second equation.
Verification:
Consider the 2nd equation
3x = 21
Put x = 7
3(7) = 21
21 = 21
Thus, it has been validated that when we conclude that x = 7 must be true for the second equation because it will also satisfy the second equation.
MGSE.6EE.3: According to the Distributive Property, 5(a + b) =
A. 5a + b
B. 5a + 5b
C. 5(b + a)
D. a(5 + b)
Answers
Answer:
B) 5a+5b
Step-by-step explanation:
5(a+b)=5a+5b
What list shows these in order from least to greatest?
Square W: A= √325 in.2
Square X: A= 3π/.5 in.2
Square Y: A= 5.5π in.2
Square Z: A= 17.92 in.2
1. Z, Y, W, X
2. X, W, Z, Y
3. Y, Z, W, X
4. W, X, Y, Z
Answers
Answer:
4 i am not sure for this answer guess
In AHIJ, the measure of ZJ=90°, the measure of ZI=62°, and IJ = 57 feet. Find the
length of JH to the nearest tenth of a foot.

Answers
Answer:
\(x = 107.2\)
Step-by-step explanation:
\(57 = ih \cos(62) \\ ih = \frac{57}{ \cos(62) } \\ \\ x = ih \sin(62) \\ x = \frac{57}{ \cos(62) } \times \sin(62) \\ x = 107.2\)
Answer:
Step-by-step explanation:
The graph had prove the adjacent length of angle ZI, which is 57. And asks the opposite side of angle ZI, we use tan. to solve for x.
tan (62) = opposite side / adjacent side
tan (62) = x / 57
tan (62) x 57 = x
x = 107.2
the inspector samples five cirucit boads at reuglar intervals and finds the means older quality score x for these five boards. do we expec x to be exactly 100 if the soldering process is functioning pripertly
Answers
The parameter refers to the entire population and the statistics refers to a sample, only a sample will be inspected, no, only 99.7%, a student t distribution with spread σ/√n, The mean is less variable than single observations from the population, The distribution of the mean call length x becomes approximately normal distributed.
The parameter refers to numbers that summarize the data of the entire population while; Statistics refers to the numbers that summarize the data for a subset of the population or of a sample
No, he expects 99.7% to function within three standard deviations of the mean
The distribution of the sample average will be the student t distribution curve with spread = σ/√n
The mean includes a collection of variables from the sample, hence it is less variable than single observations from the population
As per the Central Limit Theorem, the distribution of the mean call length x from large samples of calls becomes more and more approximately normal as the size of the sample approaches that of the population.
--The given question is incomplete, the complete question is
"What is the difference between parameters and statistics? 2. Does statistical process control inspect all the items produced after they are finished? 3. The inspector samples five circuit boards at regular intervals and finds the mean solder quality score of x for these five boards. Do we expect x to be exactly 100 if the soldering process is functioning properly? 4. If the quality of individual boards varies according to a normal distribution with mean µ = 100 and standard deviation σ = 4, what will be the distribution of the sample averages, x? (Recall the sample size is n = 5.) 5. In general, is the mean of several observations more or less variable than single observations from a population? Explain. 6. The distribution of call lengths to a call centre is strongly skewed. What does the Central Limit Theorem say about the distribution of the mean call length x from large samples of calls?"--
To know more about Central Limit Theorem, here
https://brainly.com/question/18403552
#SPJ4
Point M is on line segment LN Given LN=2x-5,LN=2x−5, MN=x-1,MN=x−1, and LM=3,LM=3, determine the numerical length of LN
.
Answers
The numerical length of LN is 9 units
How to determine the numerical length of LN?The given parameters are
LN = 2x - 5
MN = x -1
LM = 3
Because the point M is on line LM, we have
LN = LM + MN
Substitute the known values in the above equation, so, we have the following representation
2x - 5 = x - 1 + 3
Evaluate the like terms
x = 7
Substitute x = 7 in LN = 2x - 5
LN = 2 x 7 - 5
Evaluate
LN = 9
Hence, the length is 9 units
Read more about numerical length at
https://brainly.com/question/19131183
#SPJ1
The school band is ordering health bars to sell for a fundraiser. The company that sells the bars charges $0.40 per bar plus $20.00 for shipping regardless of the size of the order. The band must spend less than $200.00 on bars for the fundraiser. The inequality below relates x, the number of bars that could be ordered, with the shipping costs and their spending requirements.
0.40 x + 20 less-than 200
Which best describes the number of bars the band can order?
They can order from 0 to 449 bars, but no more.
They can order from 0 to 450 bars, but no more.
Their order must contain 451 bars or more.
Their order must contain 452 bars or more.
Answers
To divide
by
, answer this question: How many sets of
are in
? Use the model representing the fraction
to help you answer the question. (Hint: Think about grouping the blue boxes into pairs.)
Answers
Can someone please explain to me how to work this out?

Answers
Answer:
B
Step-by-step explanation:
the way i work it out is if you take the product and power it to the third you can easily find out which answer is correct. another way, if you don't have a calculator is to look at the last digit in the number in the square root sign.
For example, 3 square root 64 equals 8. you would look at the 4 and try to find 3 numbers that end in 4 OR is divisible three times by the number. 64 is exactly divisible by 4 only 3 times so you know that it can't be 8.
hope this helps!
1. What porition in the distribution cormspends to a z-sore of - 1.20: A. Belowe the mean by 1.20 points B. Beiow the mean by a difstance equal to 1.20 stanuard deviations C. Abave the incain try 1.20 points D. Abave the mican try a distance equal to 1.20 standard deviations 2. What zscore corresponds to a score that is above the mean by 2 standard dieviations? A. 1 13. −2 C. 2 D. 41 3. If a student's exam score in Chemistry was the same as the mean score for. the entire Chemistry class of 35 students, what would that stutent's z-score be: A. 2=35.00 8. z=−0.50 C. z=41.00 D. z=0.00 4. For a population with M=75 and 5=5, what is the z - score correspondin g to x=65? A 4
=−2.00 Ba 4
+1.00 C. +1.50 D. +2.00 5. A zrcore indicates how an individual perfoemed an w test relative to the other people who took the same tent. A. True 9. False 6. Suppose the 3000 students taking Introduction to Prycholody at a lage univera ty all take the same fin al exam. What can you conclude about a rtudeat takug Introduction to Dpychosogy at this univernfy whic taves the finai exam and qas a j-score of +0.80 on the final exam? คi. The rudent's icore was balaw the nuen of the 3000 wiudents. 8. The itudent answe red corsectiy ant 30 quevicions. C. The itudents score harequal to the mears of ait 1000 students. D. The student's score wras above the me in of the 3000 studenta.
Answers
1. The portion in the distribution corresponding to a z-score of -1.20 is option B. Below the mean by a distance equal to 1.20 standard deviations. This is because the z-score measures the number of standard deviations that a given data point is from the mean of the data set.
A z-score of -1.20 means that the data point is 1.20 standard deviations below the mean. 2. The z-score corresponding to a score that is above the mean by 2 standard deviations is option C. 2. This is because the z-score measures the number of standard deviations that a given data point is from the mean of the data set. A score that is 2 standard deviations above the mean corresponds to a z-score of 2.3.
If a student's exam score in Chemistry was the same as the mean score for the entire Chemistry class of 35 students, their z-score would be option D. z = 0.00. This is because the z-score measures the number of standard deviations that a given data point is from the mean of the data set. If the student's score is the same as the mean, their z-score would be zero.4. For a population with M = 75 and
s = 5, the z-score corresponding to
x = 65 is option A.
z = -2.00. This is because the z-score measures the number of standard deviations that a given data point is from the mean of the data set.
Therefore, the z-score can be calculated as follows: z = (x - M) / s
= (65 - 75) / 5
= -2.005. True. A z-score indicates how an individual performed on a test relative to the other people who took the same test.6. The student's score was above the mean of the 3000 students. This is because a z-score of +0.80 means that the student's score was 0.80 standard deviations above the mean of the data set. Therefore, the student performed better than the average student in the class. Option D is the correct answer.
To know more about z-score visit:
https://brainly.com/question/31871890
#SPJ11
(a) Use six rectangles to find estimates of each type for the area under the given graph of f from x
Answers
We have to find the area under the graph but since we are not given the graph ,So let's learn how it is done. To estimate the area under the graph of function f from x, you can use rectangles. Here's how you can do it:
Step 1: Divide the interval [a, b] into six equal subintervals.
Step 2: Calculate the width of each rectangle by dividing the total width of the interval [a, b] by the number of rectangles (in this case, 6).
Step 3: For each subinterval, find the value of the function f at the right endpoint of the subinterval.
Step 4: Multiply the width of the rectangle by the value of the function at the right endpoint to find the area of each rectangle.
Step 5: Add up the areas of all six rectangles to estimate the total area under the graph of f from x.
Let's learn more about interval:
https://brainly.com/question/479532
#SPJ11
A submarine is at a depth of 30m. It descends another 20m and then rises
40m. What is its final depth?
Answers
the answer is 10m deep after rising
Please help. I keep getting these wrong and I am not sure why!
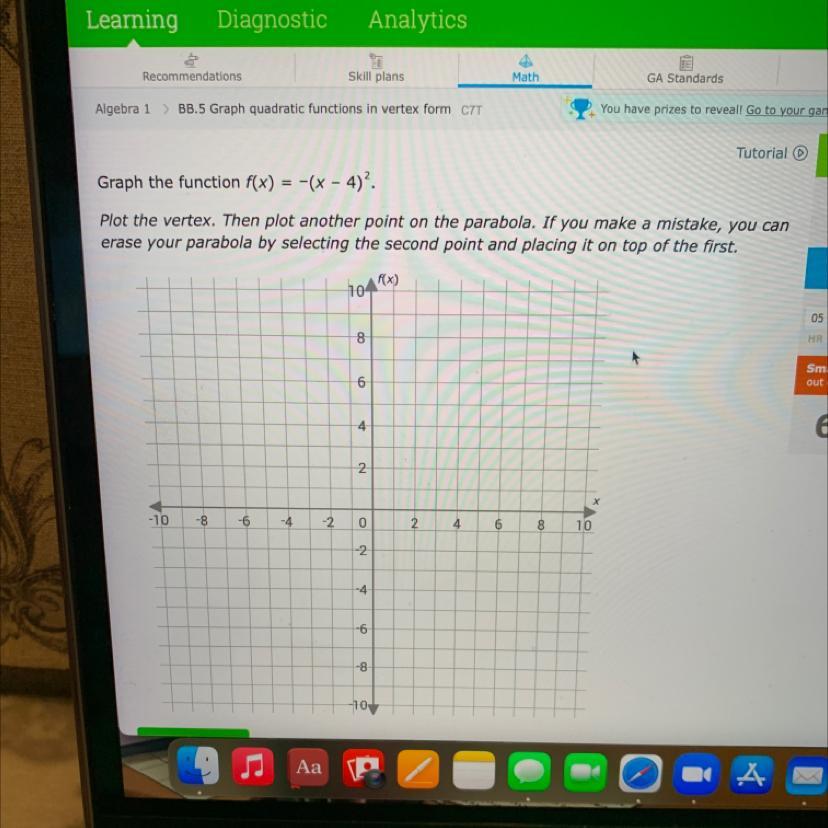
Answers
Solution
\(f\left(x\right)=-\left(x-4\right)^{2}\)The graph
The vertex of a parabola is the point at the intersection of the parabola and its line of
symmetry
Any other point is a point on the graph, you can choose any desired point on the graph

