
Answers
Answer:
For the parallel one the gradient will stay the same, so you just need to work out the y-intercept
3=(-12)-6+c
3=12+c
c=-9
equation for parallel line y=-6x-9
Then for perpendicular the gradient is the reciprocal
so you substitute again
3=1/6(-2)+c
3=-1/3+c
c=10/3
the equation for perpendicular is y=1/6x+10/3
Related Questions
Hey! I know this seems easy, but I really do need help!:(

Answers
Answer:
2b+9
Step-by-step explanation:
(7-b)+(3b+2) ---> remove parenthesis
7-b+3b+2 ---> combine like terms
2b+9
Also if you ever need help on these questions you can just dm me on thatsbloodyy on i g I love doing these types of math questions lol :,)
Happy holidays!!
Asp help probability math
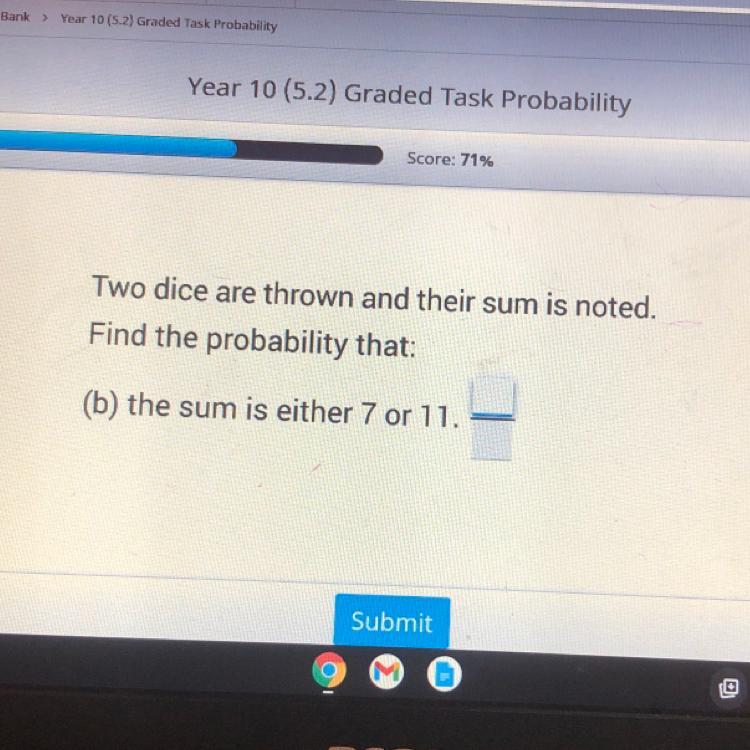
Answers
Answer:
total possible outcome is 36
sum = 7 --> (1;6) (2;5) (3;4) (4;3) (5;2) (6;1) ---> 6
= 11 --> (5;6) (6;5) ---> 2
⇒ \(\frac{6 +2}{36}\) = 8/36 = 2/9
Need help with this;

Answers
Answer:
See belowStep-by-step explanation:
Deposit amount P = $4200Interest rate r = 3 1/2% = 3.5% = 0.035 PA compounded semiannuallyCompound n = 2 per yearCalculations as per following questions
a. I = $4200*(0.035/2) = $73.5b. A = $4200 + $73.5 = $4273.5c. I = $4273.5*(0.035/2) = $74.79d. A = $4273.5 + $74.79 = $4348.29e. I = $4348.29 - $4200 = $148.29f. I = $4200*0.035 = $147What is the answer for -5x^2=-500 by factoring the quadratic equation?
Answers
Answer:
x=10
Step-by-step explanation:
I think..i tired
Divide both sides by 55.
{x}^{2}=-\frac{500}{5}x2=−5500
2
Simplify \frac{500}{5}5500 to 100100.
{x}^{2}=-100x2=−100
3
Take the square root of both sides.
x=\pm \sqrt{-100}x=±√−100
4
Simplify \sqrt{-100}√−100 to \sqrt{100}\imath√100ı.
x=\pm \sqrt{100}\imathx=±√100ı
5
Since 10\times 10=10010×10=100, the square root of 100100 is 1010.
One researcher treats this data set as a representative sample of passenger liner travelers at the time to study the factors that influence ticket prices. She expects that the sex of a passenger influences the ticket price. Propose a linear regression model to evaluate the researcher's expectation. Interpret your results.
Answers
Linear regression is an essential statistical tool for understanding relationships between two continuous variables. It allows us to understand how the dependent variable (y) changes with changes in the independent variable (x).
In this problem, we are interested in studying how sex influences ticket prices for passenger liner travelers. Let's propose a linear regression model for this. We begin by defining our variables. Our dependent variable is ticket price (y), and our independent variable is sex (x). Since sex is a categorical variable, we need to create a dummy variable for this. We define sex as follows: 1 for female and 0 for male.
Since β1 is negative, we conclude that ticket prices are, on average, $30 lower for male passengers than for female passengers. Therefore, we can conclude that sex is a statistically significant predictor of ticket prices for passenger liner travelers at the time.
To know more about essential visit:
https://brainly.com/question/3248441
#SPJ11
Lisa is on the west shore of Mighty River, which is 1 mile wide and has two parallel shorelines running exactly north-to-south. She wishes to get to a point on the opposite shore that is 1 mile south of where she is now as quickly as possible. (So this point is sqrt (2) miles due southeast from her starting position.) Assuming that Lisa can walk twice as fast as she can swim, and that she wants to swim across the river first before walking any necessary distance along the opposite shoreline, at what course (in degrees) should she start swimming?
(The angle is measured from north, so 90 degrees is due east, meaning she swims directly across the river, and 135 degrees is due southeast, meaning she swims directly to her destination point.)

Answers
Lisa should start swimming at an angle of \(120^{\circ}\) to reach her destination as quickly as possible.
Given:
The river is 1 mile wideThe end point is 1 mile south of the starting pointLisa's speed of walking is twice that of her speed of swimmingLisa wants to swim across the river first before walking the rest of the distance along the opposite shorelineTo find: The course (in degrees) at which she should start swimming so that she can reach the end point as quickly as possible
To solve this problem, we need to know the following:
Pythagoras theorem states that in a right angled triangle, the square of the length of hypotenuse is the sum of the squares of lengths of perpendicular and baseCosine of an angle is the ratio of base and hypotenuse in the right angled triangleA single variable function is minimized by a value for which, the first derivative of the function is zero and the second derivative of the function is positiveLet us assume that Lisa starts swimming at a course such that she needs to swim for 'x' miles to reach the opposite shore, as shown in the figure.
Labelling the points in the figure, we can say that,
AB = 1 mile (given)
BD = 1 mile (given)
AC = x miles (by our assumption)
It is clear that ABC forms a right angled triangle where,
Perpendicular: BC
Base: AB
Hypotenuse: AC
Using Pythagoras Theorem for triangle ABC, we have,
\((Hypotenuse)^{2} =(Perpendicular)^{2} +(Base)^{2}\), which implies,
\((AC)^{2} =(BC)^{2} +(AB)^{2}\)
Put AC = x, AB = 1 in the above equation to get,
\(x^{2} =(BC)^{2} +1^{2}\)
\(x^{2} =(BC)^{2} +1\)
\((BC)^{2}=x^{2} -1\)
\(BC=\sqrt{x^{2} -1}\)
From the figure, we can say that,
\(CD=BD-BC\)
Put \(BC=\sqrt{x^{2} -1}\) and \(BD=1\) in the above equation to get,
\(CD=1-\sqrt{x^{2} -1}\)
According to our assumption, Lisa swims the distance of AC and walks the distance of CD, that is, she swims a distance of \(x\) miles and walks a distance of \(1-\sqrt{x^{2} -1}\) miles.
Now, let us assume that Lisa's speed of swimming is \(k\) miles/hour. It is given that Lisa's speed of walking is twice that of her speed of swimming. Then, accordingly, Lisa's speed of walking must be \(2k\) miles/hour. We note that these speeds are constants for Lisa.
We know that,
\(Speed=\frac{Distance}{Time}\)
Then,
\(Time=\frac{Distance}{Speed}\)
This implies that,
Time spent by Lisa on swimming = \(\frac{x}{k}\)
Similarly, time spent by Lisa on walking = \(\frac{1-\sqrt{x^{2} -1} }{2k}\)
Then, total time taken by Lisa to travel the whole distance from the starting point to the end point is,
\(\frac{1-\sqrt{x^{2} -1} }{2k} +\frac{x}{k}\)
\(\frac{1}{2k}( 1-\sqrt{x^{2} -1} +2x )\)
Since Lisa wishes to get to the end point as quickly as possible, we must minimize the total time taken by her to travel the entire distance.
Total time taken: \(T=\frac{1}{2k}( 1-\sqrt{x^{2} -1} +2x )\)
Differentiating with respect to 'x', we have,
\(T'=\frac{1}{2k}( -\frac{x}{\sqrt{x^{2} -1}} +2 )\)
Differentiating with respect to 'x' again, we have,
\(T''=\frac{1}{2k(\sqrt{x^{2} -1})^{3}}\)
Equating the first derivative to 0, we have,
\(\frac{1}{2k}( -\frac{x}{\sqrt{x^{2} -1}} +2 )=0\)
\(-\frac{x}{\sqrt{x^{2} -1}} +2 =0\)
\(\frac{x}{\sqrt{x^{2} -1}} =2\)
\(2\sqrt{x^{2} -1}= x\)
Squaring both sides,
\(4(x^{2} -1)= x^{2}\)
\(4x^{2} -4= x^{2}\)
\(3x^{2} =4\)
\(x^{2} =\frac{4}{3}\)
\(x=\frac{2}{\sqrt{3}}\)
Note that we assumed the positive square root for 'x' because 'x' denotes a distance which cannot be negative.
Put \(x=\frac{2}{\sqrt{3}}\) in the expression for second derivative to get,
\(T''=\frac{1}{2k(\sqrt{(\frac{2}{\sqrt{3}} )^{2} -1})^{3}}\)
\(T''=\frac{1}{2k(\sqrt{\frac{4}{3} -1})^{3}}\)
\(T''=\frac{1}{2k(\sqrt{\frac{1}{3}})^{3}}>0\)
The last expression is positive because 'k' denotes a speed which is always positive.
This implies that the obtained value \(x=\frac{2}{\sqrt{3}}\) minimizes the quantity of total time taken.
Now, from the figure, we can say that,
\(cos(\angle BAC)=\frac{AB}{AC}\)
Put AC = x, AB = 1 in the above equation to get,
\(cos(\angle BAC)=\frac{1}{x}\)
Put the obtained minimizing value, \(x=\frac{2}{\sqrt{3}}\) in the above equation to get,
\(cos(\angle BAC)=\frac{1}{\frac{2}{\sqrt{3}} }\)
\(cos(\angle BAC)=\frac{\sqrt{3}}{2 }\)
\(cos(\angle BAC)=cos(30^{\circ})\)
Then,
\(\angle BAC=30^{\circ}\)
Since the angle is measured from the north, the required angle is, \(90^{\circ}+30^{\circ}=120^{\circ}\)
Thus, Lisa should start swimming at an angle of \(120^{\circ}\) to reach her destination as quickly as possible.
Learn more about finding optimum course here:
https://brainly.com/question/17587668

How can you use a protractor to prove that AB and DC are perpendicular?
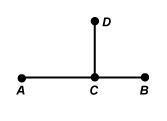
Answers
8. Choose the graph that represents the equation y = -x + 4 + 1.
Answers
Answer:
where r the graphs i can not help if u don't put the graphs
Step-by-step explanation:
Vanessa is creating centerpieces for a reception. Each centerpiece will consist of eight flowers arranged around one candle. Vanessa will create 20 of these centerpieces. Each candle costs $6.00, and each flower costs $1.50. What is the final cost of the centerpieces? $120.00 $240.00 $360.00 $480.00

Answers
Answer:
360
Step-by-step explanation:
If you multiply 20 by 6 you get 120
then if you multiply 1.50 by 8 you get 12
then multiply 12 by 20 which equals 240
add 240 by 120 you get your final answer 360
.a. Approximate the given quantity using Taylor polynomials with
n=3.
b. Compute the absolute error in the approximation assuming the exact value is given by a calculator.
sinh (0.24)
a. Approximate the given quantity using Taylor polynomials with
n=3.
b. Compute the absolute error in the approximation assuming the exact value is given by a calculator.
sinh (0.17)
Answers
a. To approximate the given quantity using Taylor polynomials with n=3, we need to use the formula for the Taylor polynomial of degree n:
Pn(x) = f(a) + f'(a)(x-a) + (1/2!)f''(a)(x-a)^2 + (1/3!)f'''(a)(x-a)^3 + ... + (1/n!)f^(n)(a)(x-a)^n
where f(x) = sinh(x), a = 0. The derivatives of sinh(x) are:
f'(x) = cosh(x), f''(x) = sinh(x), f'''(x) = cosh(x), and so on.
Therefore, the Taylor polynomial of degree 3 for sinh(x) centered at a = 0 is:
P3(x) = x + (1/2!)(x)^3
To approximate sinh(0.24), we substitute x = 0.24 into the formula above:
P3(0.24) = 0.24 + (1/2!)(0.24)^3 = 0.240008
b. To compute the absolute error in the approximation assuming the exact value is given by a calculator, we need to subtract the actual value of sinh(0.24) from the approximation we obtained in part a:
Error = |P3(0.24) - sinh(0.24)| = |0.240008 - 0.241663| = 0.001655
Therefore, the absolute error in the approximation is 0.001655.
To approximate sinh(0.17), we use the same formula and substitute x = 0.17:
P3(0.17) = 0.17 + (1/2!)(0.17)^3 = 0.170005
To compute the absolute error in this case, we subtract the actual value of sinh(0.17) from the approximation we obtained:
Error = |P3(0.17) - sinh(0.17)| = |0.170005 - 0.17031| = 0.000305
Therefore, the absolute error in the approximation for sinh(0.17) is 0.000305.
To know more about approximate visit:
https://brainly.com/question/16315366
#SPJ11
Besides being simple for its own sake, what other advantage do simple models usually have?
a) Higher accuracy
b) Greater complexity
c) Easier interpretation
d) More detailed predictions
Answers
The correct option is c) Easier interpretation. One of the main advantages of simple models is their ease of interpretation. Simple models tend to have fewer parameters and less complex mathematical equations, making it easier to understand and interpret how the model is making predictions.
This interpretability can be valuable in various domains, such as medicine, finance, or legal systems, where it is important to have transparent and understandable decision-making processes.
Complex models, on the other hand, often involve intricate relationships and numerous parameters, which can make it challenging to comprehend the underlying reasoning behind their predictions. While complex models can sometimes offer higher accuracy or make more detailed predictions, they often sacrifice interpretability in the process.
To know more about complex visit-
brainly.com/question/28235673
#SPJ11
the first stack has 3 boxes, the second has 2 boxes, and the third has one box. in how many ways can he stack the six boxes in this way?
Answers
Using Permutation formula,
Total 720 ways are possible to stack the six boxes in order .
We have given that,
First stack contains number of boxes = 3
Second stack contains number of boxes = 2
Third stack contains number of boxes = 1
Total number of boxes = 6
Number of ways to stack 1 box = ⁶P₁ = 6!/5!
= 6 ways
Number of ways to stack 2 boxes = ⁵P₂= 5!/(5-2)!
= 5!/3! = 20 ways
Number of ways to stack 3 boxes = ⁴P₃= 4!/1!
= 4 ways
Total ways to stack 6 boxes = ⁶P₁ ×⁵P₂×⁴P₃
= 20×6× 4 = 720 ways
Hence, we can stack the 6 boxes in 720 ways .
To learn more about Permutation , refer:
https://brainly.com/question/28065038
#SPJ4
4(x + 2) = 4x + 2
Are these two Equivalent
Answers
Answer:
no they're not
Step-by-step explanation:
4(x+2) = 4x +8
4x+2= 4x+2
Answer:
No they are not equivalent
First we would have to solve 4(x+2)
In order to solve this we need to multiply. So 4×X is equal to 4x. 4×2=8 Therefore when solving Its 4x+8..and 4x+8 is not equivalent to 4x+2
In the first half of last year, a team won 60 percent of the games it played. In the second half of last year, the team played 20 games, winning 3 of them. If the team won 50 percent of the games it played last year, what was the total number of games the team played last year?
A) 60
B) 70
C) 80
D) 90
E) 100
Answers
The total number of games the team played last year was 80 (option C). In the first half of the year, the team won 60 percent of their games, indicating that they won 6 out of every 10 games played.
In the second half of the year, the team played 20 games and won 3 of them. This means that in the second half, they won only 3 out of 20 games, which is equivalent to winning 15 percent of their games.
To find the overall percentage of games won, we can calculate the weighted average of the two percentages. Since the team won 50 percent of their games overall, we can assign equal weights to the first and second halves of the year. Therefore, the average winning percentage for the team would be the midpoint between 60 percent and 15 percent, which is (60% + 15%) / 2 = 37.5%.
Let's assume the total number of games played last year was x. Since the team won 37.5% of the games, they won 0.375x games. We can set up an equation based on the information given:
0.375x = 50% of x
0.375x = 0.5x
0.5x - 0.375x = 0
0.125x = 0
x = 0 / 0.125
x = 0
However, we have arrived at an invalid result. It seems there is an error in the information provided or the calculations made.
Learn more about percentages here: https://brainly.com/question/16797504
#SPJ11
The area of the Atlantic Ocean is 2.9638 x 107 mi? . The area of the
Pacific Ocean is 6.0061 x 107 mi? How much greater is the area of the
Pacific Ocean than the area of the Atlantic Ocean?
A 3.0423 x 10° mi?
B 3.0423 x 104 mi?
C 3.0423 x 106 mi?
D 3.0423 x 10? mi?
Answers
Answer:
Answer not in the listed options....did you enter all of the info correctly ?
Step-by-step explanation:
6.0061 / 2.9638 = 2.026 times bigger
y = 3x - 7
The slope of the function is
type your answer...
. The y-intercept of the function is
type your answer..
Answers
Answer:
The slope is 3, and the y-intercept is -7
Step-by-step explanation:
This is written in y = mx + b form, where m is the slope, and b is the y-intercept.
~theLocoCoco
The slope of the function is 3. The y-intercept of the function is -7.
In the equation y = 3x - 7, the coefficient of x is 3. This coefficient represents the slope of the line.
Therefore, the slope of the function is 3.
The equation is in the form y = mx + b, where m represents the slope and b represents the y-intercept.
In this equation, the y-intercept is the value of y when x is 0. By substituting x = 0 into the equation, find the y-intercept.
y = 3(0) - 7
= 0 - 7
= -7
Hence, the y-intercept is -7.
To know more about function here
https://brainly.com/question/30721594
#SPJ6
You have just signed up for a broadband home internet service that uses coaxial cable. which connector type will you most likely use?
Answers
Answer:
F type connector
Step-by-step explanation:
Use an F-type connector for broadband cable connections that use coaxial cable.
The F connector is a coaxial RF connector commonly used for "over the air" terrestrial television, cable television and universally for satellite television and cable modems,
#SPJ4
Learn more on
https://brainly.com/question/14391417
F type connector
The F-connector is a coaxial RF connector commonly used for "wireless" terrestrial television, cable television, and common for satellite television and cable modems, usually with RG-6/U cable or with RG -59 / U.F connector is also known as threaded connector. There are two main types: 7mm (6.8mm) is the most common and used in coaxial cable, and 5mm connector is used in thin coaxial cable commonly used in satellite system.
The F-connector is an accessory that connects a coaxial cable to an electronic device or wall outlet.
Type F connectors are highly mechanical and electrically stable coaxial screw connectors for cable television (CATV), set-top boxes, cable modems and satellite television applications up to 4 GHz
Learn more about wire here
https://brainly.com/question/15246898
#SPJ4
Which of the following statements is true for this distribution? (No calculations are required to answer this question.)
50
60
70
80
O A Mean > Median
O
B. The relationship between the mean and median cannot be determined from the display.
O
C. Median > Mean
O D. Mean = Median

Answers
Answer:
The t distribution can be used when finding a confidence interval for the population mean whenever the sample size is small.
Hence, the correct option is A.
To estimate the population mean we use a t-distribution to calculate the confidence interval. When we use a t-distribution the sample standard deviation is used to estimate the population standard deviation
On Sunday, Melissa has $56.75 on her debit card when she goes out with sone friends. She uses her debit card to spend $19.25 on lunch. She and her friends would like to go to see a movie, but some of her friends are out of money. If the movie tickets cost $7.25 each, what is the maximum number of tickets can Melissa buy without overdrawing on her debit card?
Answers
Answer: 40 or 30
Step-by-step explanation:
56.75 - 19.25 + 7.25
56.75 - 26.26
30.49
round: 40 or 30
some researchers claim that there is not much difference between qualitative and quantitative data. please select the best answer from the choices pro
Answers
The claim that there is not much difference between qualitative and quantitative data is incorrect.
Qualitative and quantitative data are two distinct types of data that serve different purposes and have different characteristics.
Qualitative data refers to non-numerical information that is typically obtained through observations, interviews, or surveys. It provides insights into opinions, attitudes, behaviors, and subjective experiences. Qualitative data is often descriptive in nature, expressed in words, narratives, or themes. It allows researchers to explore complex phenomena, understand contextual factors, and capture the richness of human experiences. Examples of qualitative data include interview transcripts, field notes, and open-ended survey responses.
On the other hand, quantitative data is numerical in nature and involves the collection and analysis of measurable variables. It focuses on quantities, statistical analysis, and mathematical modeling. Quantitative data allows researchers to quantify relationships, make predictions, and conduct statistical tests. It is often collected through surveys, experiments, or structured observations. Examples of quantitative data include numerical measurements, survey responses on a Likert scale, and statistical values such as means and standard deviations.
In conclusion, qualitative and quantitative data are distinct in their characteristics, purpose, and analytical approaches. The claim that there is not much difference between them is incorrect.
Learn more about qualitative and quantitative data
brainly.com/question/17313620
#SPJ11
A parallelogram has an area of 20 square centimeters. The height of the triangle is 5 centimeters. What is the length of its base?
Answers
Answer:
4 cm
Step-by-step explanation:
A parallelogram area formula= Base x Height.
It already gave you the area so you can work backwards to solve for the base.
So, 20 divided by 5(the height) is 4.
Therefore, you can conclude that the length of the base is 4 cm.
Sue has 45 shells in her shell collection. Jared, who just started his collection, has
5 shells. Sue’s collection is how many times larger than Jared’s? I need the equation: and answer
Answers
Answer:
9
step by step:
sue = 45 shells
Jared= 5 shells
therefore 45÷5 =9
Answer:
9 times bigger
Step-by-step explanation:
45/5= 9 times bigger
why?
because "how many times bigger (or larger)"
Sue has 45 shells
and Jared has 5 shells
divide them and u get the answer
equation of a circle with center at the origin and radius 10
Answers
The equation of a circle with the center at the origin and radius 10 can be determined by using the standard form of the equation of a circle, which is given by the equation x² + y² = r², where (x, y) are the coordinates of any point on the circle, and r is the radius of the circle. If the center of the circle is at the origin,
then the coordinates of the center are (0, 0), and the equation can be written as x² + y² = 10². This equation represents a circle with center at the origin and radius 10. This equation can be used to graph the circle by plotting the points that satisfy the equation.
The circle will be a perfect circle with a radius of 10 units and centered at the origin. It will pass through the points (-10, 0), (0, -10), (10, 0), and (0, 10). These points can be found by solving the equation for x and y. When x = -10, 0, and 10, y will be equal to 0, and when y = -10, 0, and 10, x will be equal to 0. This is how the circle can be graphed using the equation.
To know more about center visit:
https://brainly.com/question/31935555
#SPJ11
What is the solution to the inequality below x2 > 64
Answers
Answer:
Step-by-step explanation:
x2
Review Questions
1. Cindy is a baker and runs a large cupcake shop. She has already
a. How many workers will the firm hire if the market wage rate is
hired 11 employees and is thinking of hiring a 12th. Cindy esti- $27.95 ? \$19.95? Explain why the firm will not hire a larger or mates that a 12 th worker would cost her $100 per day in wages $ smaller number of units of labor at each of these wage rates. and benefits while increasing her total revenue from $2,600per. day to $2,750 per day. Should Cindy hire a 12 th worker? b. Show this firm Explain. L016.2 c. Now again determine the firm's demand curve for labor. Complete the following labor demand table for a firm that is assuming that it is selling in an imperfectly competitive marhiring labor competitively and selling its product in a competiket and that, although it can sell 17 units at $2.20 per unit, it tive market. L016.2 ginal product of each successive labor unit. Compare this demand curve with that derived in part b. Which curve is more elastic? Explain. 3. Alice runs a shoemaking factory that uses both labor and capital to make shoes. Which of the following would shift the factory's demand for capital? You can select one or more correct answers from the choices shown. LO16.3 a. Many consumers decide to walk barefoot all the time. b. New shoemaking machines are twice as efficient as older machines. c. The wages that the factory has to pay its workers rise due to an economywide labor shortage.
Answers
Cindy should hire the 12th worker as it would result in a net increase in profit, with additional revenue exceeding the cost of hiring. Insufficient information is provided to determine the demand curve for labor or compare its elasticity. Events that would shift the factory's demand for capital include new, more efficient machines and rising wages due to a labor shortage.
a. To determine whether Cindy should hire a 12th worker, we need to compare the additional revenue generated with the additional cost incurred. Hiring the 12th worker would increase total revenue by $150 ($2,750 - $2,600) per day, but it would also increase costs by $100. Therefore, the net increase in total profit would be $50 ($150 - $100). Since the net increase in profit is positive, Cindy should hire the 12th worker.
b. By hiring the 12th worker, Cindy can increase her total revenue from $2,600 per day to $2,750 per day. The additional revenue generated by the 12th worker exceeds the cost of hiring that worker, resulting in a net increase in profit.
c. To determine the firm's demand curve for labor, we need information about the marginal product of labor (MPL) and the wage rates. Unfortunately, this information is not provided, so we cannot complete the labor demand table or derive the demand curve for labor.
Without specific data or information about changes in the quantity of labor demanded and wage rates, we cannot determine which demand curve (from part b or c) is more elastic. The elasticity of the demand curve depends on the responsiveness of the quantity of labor demanded to changes in the wage rate.
The events that would shift the factory's demand for capital are:
a. New shoemaking machines being twice as efficient as older machines would increase the productivity of capital. This would lead to an increase in the demand for capital as the factory would require more capital to produce the same quantity of shoes.
b. The wages that the factory has to pay its workers rising due to an economy-wide labor shortage would increase the cost of labor relative to capital. This would make capital relatively more attractive and lead to an increase in the demand for capital as the factory may substitute capital for labor to maintain production efficiency.
The event "Many consumers decide to walk barefoot all the time" would not directly impact the demand for capital as it is related to changes in consumer behavior rather than the production process of the shoemaking factory.
Learn more about the demand curve at:
brainly.com/question/1139186
#SPJ11
How many different 4-question geometry quizzes can a teacher make if there are 7 different problems to test on?.
Answers
Answer:
35 quizzes
Step-by-step explanation:
We need to determine how many ways we can choose 4 questions out of 7 to make the quizzes.
We do this by using the formula \(\displaystyle nCr=\frac{n!}{r!(n-r)!}\) which describes the number of ways we can choose \(r\) objects given \(n\) possible choices. So, if \(n=7\) and \(r=4\), then:
\(_4C_7=\frac{7!}{4!(7-4)!}\\\\_4C_7=\frac{7*6*5*4!}{4!*3!}\\\\_4C_7=\frac{210}{6}\\\\_4C_7=35\)
Hence, the teacher can make 35 different geometry quizzes.
Distinguish between the terms data warehouse, data mart, and data lake and provide one example.
Question 2:Identify three commonly used approaches to cloud computing. Mention two main characteristics for each one.
Answers
A data warehouse is a centralized repository that stores structured, historical data from various sources within an organization. A data mart is a subset of a data warehouse that focuses on a specific subject area or department within an organization. A data lake is a storage system that stores vast amounts of raw and unstructured data in its original format. Three commonly used approaches to cloud computing are Infrastructure as a Service, Platform as a Service and Software as a Service.
Data Warehouse:
A data warehouse is a centralized repository that stores structured, historical data from various sources within an organization. It is designed for reporting, analysis, and business intelligence purposes. Data warehouses consolidate data from different systems, transform it into a consistent format, and provide a unified view of the organization's data. For example, a retail company may create a data warehouse to store sales data from different stores and regions for analysis and decision-making.
Data Mart:
A data mart is a subset of a data warehouse that focuses on a specific subject area or department within an organization. It contains a subset of data relevant to a particular business unit or user group. Data marts are designed to provide more specialized and targeted analysis compared to a data warehouse. For example, within a data warehouse for a healthcare organization, there may be separate data marts for patient records, financial data, and supply chain management.
Data Lake:
A data lake is a storage system that stores vast amounts of raw and unstructured data in its original format. It is a repository that can hold structured, semi-structured, and unstructured data from various sources without the need for predefined schemas or data transformations. Data lakes allow for flexible and scalable storage and enable data exploration, advanced analytics, and machine learning. For example, a company may create a data lake to store customer logs, social media feeds, and sensor data for future analysis and insights.
Question 2:
Three commonly used approaches to cloud computing are:
1. Infrastructure as a Service (IaaS):
- Characteristics: Provides virtualized computing resources such as virtual machines, storage, and networks.
- Main characteristics: Allows users to have full control over the infrastructure and is highly scalable. Users are responsible for managing the virtual machines and software installed on them.
2. Platform as a Service (PaaS):
- Characteristics: Offers a platform and environment for developing, testing, and deploying applications.
- Main characteristics: Provides ready-to-use development tools, middleware, and databases. Users focus on application development and deployment while the underlying infrastructure is managed by the cloud provider.
3. Software as a Service (SaaS):
- Characteristics: Delivers software applications over the internet on a subscription basis.
- Main characteristics: Users access and use software applications hosted on the cloud without the need for installation or maintenance. The cloud provider handles the infrastructure, maintenance, and updates.
These approaches provide varying levels of control and responsibility to users, depending on their specific requirements and preferences.
To know more about data warehouse, visit:
https://brainly.com/question/18567555#
#SPJ11
Are these lines perpendicular?

Answers
Answer:
No
Step-by-step explanation:
Answer: no
Step-by-step explanation:
Typically you can test if lines are perpendicular. You would test if the slopes are opposite signed and reciprocals(flipped)
You don't need to test, you can see the lines do not look perpendicular
They would form right angles, or squared angles, like the corner of a paper.
so answer is no
You are shipping some books to a friend. A small box will hold 6 books. A
large box will hold 18 books. You shipped a total of 54 books in 5 boxes.
How many small boxes and how many large boxes did you use? Define the
variables that you use to write the system.
Answers
a) use these data to estimate the mean wrist extension for people using this new mouse design using a 90% confidence interval. (round your answers to three decimal places.) , (b) what assumptions are required in order for it to be appropriate to generalize your estimate to the population of students at this university? yes, the assumption would have to be made that the 24 students in the study formed a random sample of people in the country. no, we can generalize the estimate to the population of students at this university. yes, the assumption that the 24 students in the study formed a random sample of students at all universities. yes, the assumption would have to be made that the 24 students in the study formed a random sample of students at this university. no, we cannot generalize the estimate to any population as we have less than 30 students. to the population of all university students? no, we cannot generalize the estimate to any population as we have less than 30 students. yes, the assumption would have to be made that the 24 students in the study formed a random sample of people in the country. yes, the assumption would have to be made that the 24 students in the study formed a random sample of students from this university. no, we can generalize the estimate to the population of all university students. yes, the assumption that the 24 students in the study formed a random sample of students at all universities. (c) based on your interval from part (a), do you think there is reason to believe that the mean wrist extension for people using the new mouse design is greater than 20 degrees? explain why or why not. no, the entire confidence interval is below 20, so the results of the study would be very likely if the population mean wrist extension were greater than 20. no, the confidence interval contains 20, so the results of the study would be very likely if the population mean wrist extension were greater than 20. yes, the confidence interval contains 20, so the results of the study would be very unlikely if the population mean wrist extension were as low as 20. yes, the entire confidence interval is above 20, so the results of the study would be very unlikely if the population mean wrist extension were as low as 20.
Answers
The random sample of \(24\) students has a mean of \(1.9149\), and the data suggests that the mean is \(20^{0}\).
How to Use the Sample Mean Formula to Determine the Sample Mean?x = (xi) / n is the general solution for computing the sample mean. Thus, xi refers to all X sample values, xi represents the sampling distribution, and n is the total number of specimen terms inside the data collection.
What does sample in statistics mean?The statistic known as the sampling distribution is created by arithmetically averaging the values of the variables in a group. The sample mean is an estimate of the anticipated value if the sample is taken from probabilistic with a common expected value.
(a) Sample mean \(= (17 + 21 + 20 + 19 + 23 + 22 + 20 + 20 + 18 + 21 + 19 + 24 + 22 + 20 + 19 + 20 + 19 + 20 + 21 + 22 + 23 + 21 + 18 + 22)/24 = 20.5\)Sample standard deviation \(= 1.9149\)
Next, we can use a t-distribution with \(23\) degrees of freedom
Confidence interval \(= (20.5 - 0.8277, 20.5 + 0.8277) = (19.6723, 21.3277)\)
b) The assumption required in order to generalize the estimate to the population of students at this university is that the \(24\) students in the study formed a random sample of students at this university.
(c) There is not enough evidence to suggest that the mean wrist extension for people using the new mouse design is greater than \(20^{0}\).
To know more about Sample mean visit:
https://brainly.com/question/30023845
#SPJ1