Doctors recommend the people drink 64 ounces of water per day how much water in milliliters do doctors recommend people drink to the nearest tenth
Answers
Answer:
1892.7 ml
Hope this helps!
1 oz= 29.57 ml
64x29.57= 1892.71
Related Questions
focus (4,-3) directrix y=-3 what’s the equation for the parabola
Answers
The equation of the parabola is x² - 8x + 16 = 0
What is the equation of the parabolaTo find the equation of the parabola with focus (4, -3) and directrix y = -3, we can use the definition of a parabola.
A parabola is the set of all points that are equidistant to the focus and the directrix.
The distance from a point (x, y) to the directrix y = -3 is simply the vertical distance between the point and the line, which is |y - (-3)| = |y + 3|.
The distance from a point (x, y) to the focus (4, -3) can be found using the distance formula:
d = √[(x - 4)² + (y + 3)²]
Since the point is equidistant to the focus and the directrix, we have:
d = |y + 3|
Squaring both sides, we get:
(x - 4)² + (y + 3)² = (y + 3)²
Simplifying, we get:
(x - 4)² = 0
Thus, the equation of the parabola is simply:
x² - 4x - 4x + 16 = 0
x² - 8x + 16 = 0
Learn more on equation of parabola here;
https://brainly.com/question/4061870
#SPJ1
Examine figures Q, R, and S. Which of these
figures is not a translation of figure P?
Explain.

Answers
From the options and the figure given we can conclude that the figure S is not a translation of figure P.
Given is four figure we need to determine which is not translation of figure P,
Along with rotations, reflections, and scaling, translations are one of the fundamental transformations used in geometry.
The characteristics and symmetries of geometric forms are frequently studied using them.
Translations in three dimensions have a similar structure but also entail movements in the horizontal, vertical, and depth planes.
Translation produces congruent figures.
When a figure is translated, its size and shape remain unchanged, and the resulting figure is congruent to the original.
Here except S all the three are same.
Hence figure S is not a translation of figure P.
Learn more about Translations click;
https://brainly.com/question/29712965
#SPJ1
the latin dance club needs to raise more than $178.50 to buy costumes. the club has already raised $35.70. which inequality shows how much money each of the 7 club members needs to raise, m, if each person raises the same amount?
Answers
Answer:
The Latin dance club needs to raise $178.50 to buy costumes. The club has already raised $35.70, so they need to raise $178.50 - $35.70 = $142.80 more. If each person raises the same amount, then each person needs to raise $142.80 / 7 = $20.40.
Therefore, the inequality that shows how much money each of the 7 club members needs to raise is: m > $20.40
Step-by-step explanation:
Please help ASAP!! Thank you!
Compute:

Answers
Answer:
1/6
Step-by-step explanation:
you can just add the exponents because the number is the same so 9 +5 = 14
so now you can divide top and bottom by 6^14 and your left with 1/6
\( \sqrt[14]{6.3} \)need help showing my son how to solve this problem. explanation is key.
![[tex] \sqrt[14]{6.3} [/tex]need help showing my son how to solve this problem. explanation is key.](https://i5t5.c14.e2-1.dev/h-images-qa/contents/attachments/nuHY62ZKttDWALoNx1Cnl0nMyoSt8hpt.jpeg)
Answers
Divide 6.3 meters of leather
between 14
Then
6.3 meters= 630 cm
Now divide
630/14 =
Find m,c,d (max common divisor), between 63 and 14. Its 7.
divide by 7, both numerator and denominator
90/2 = 45
Then answer is , each piece is 45 cm long
Question content area top
Part 1
Ms. Jackson wants to rent a large truck for a week. It will cost the weekly fee plus $0.50 per mile driven. Let m=the number of miles Ms. Jackson drives during the week. Use this information and the table to answer 13–15
Answers
Please give me the correct answer.Only answer if you're very good at math.
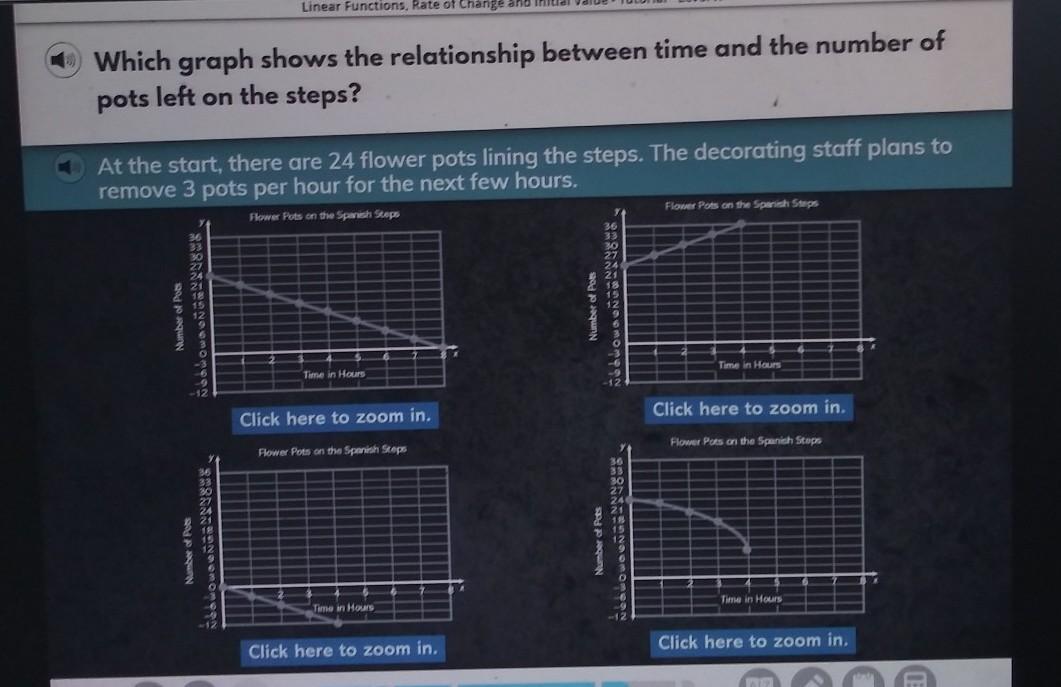
Answers
Answer:
1st graph
Step-by-step explanation:
this is the only graph that begins at 24, has a negative slope, is linear, and ends at (8,0) which, after 8 hours losing 3 pots per hour, makes sense
I can tell because at 0 hours, they started out with 24 plants, which means there should be a point at (0,24). I also know that free every hour, they remove 3 plants, so the line should be going down (as the number of pots keeps on getting lower).
Does someone mind helping me with this problem? Thank you!

Answers
The percentage gain of the company is calculated to be 10%.
How to calculate for the percentage gainThe percentage gain is calculated by multiplying the fraction of the gain and the initial amount by 100.
we shall calculate for the percentage gain of the company as follows:
gain = $33 - $30 = $3
initial amount = $30
percentage gain = ($3/$30) × 100
percentage gain = (1/10) × 100
percentage gain = 10%
Therefore, the percentage gain of the company is calculated to be 10%.
Know more about percentage here:https://brainly.com/question/843074
#SPJ1
help me with my math assignment for 25 points and crown.


Answers
The dimensions and volumes of the various containers that can be ,made with the 3 meters × 3 meters sheet of fine wire indicates that the maximum volume possible is 2 m³
What is the volume of a rectangular prism container?The volume of a rectangular prism container is the product of the base area and the height of the container.
The volume of the open-topped container formed by the 3 m × 3 m sheet of fine wire mesh can be presented as follows
Step 1:
\(\begin{tabular}{|c|c|c|c|c|c|} \cline{1-5}Corner cut (m) & Length (m)&Width (m)&Height(m)&Volume (m^3) \\ \cline{1-5}0& 3&3&0&0 \\ \cline{1-5}0.5 & 2&2&0.5&2 \\ \cline{1-5} 1& 1&1&1&1 \\ \cline{1-5} \cline{1-5}\end{tabular}\)
Step 2; Let x represent the corner cut
Step 3; The expression for the new side length can be found as follows;
When x is cut from each corner, the new side length is; 3 - 2·x
Step 4: The expression for the volume can be obtained from the volume of a cube formula, which is; V = L × W × H
Where;
L = The length of the box = 3 - 2·x
W = The width of the box = 3 - 2·x
H = The height of the box = x
Therefore, the volume of the container is; x·(3 - 2·x)²
Step 5: Please find attached the graph of the volume function created with MS Excel
Step 6; The value of the volume cut that generates the (optimal) maximum volume, obtained from the graph is; x = 0.5
Step 7 The values in the table indicates that when x = 2, the volume will be 3 m³, which is the maximum volume.
Learn more on optimization of a function here: https://brainly.com/question/15358878
#SPJ1

(a) (5 points) Give a recursive definition of the sequence {on}. n=1,2,3... if an=1+(-1)". (b) (6 points) Find (2), (3), (4) if f is defined recursively by 7(0) = -1. (1) = 2, and for n=1,2,3,..we
Answers
(a) The recursive definition of the sequence {on} is:
a₁ = 0 (base case)
an = 1 + (-1)ⁿ⁻¹ + an-1 (recursive rule)
(b) f(2) = 2, f(3) = 4, and f(4) = 4.
(a) Recursive definition of the sequence {on}:
To define the sequence {on} recursively, we need to provide the base case and the recursive rule.
Base case: a₁ = 1 + (-1)¹ = 1 - 1 = 0
Recursive rule: For n > 1, an = 1 + (-1)ⁿ⁻¹ + an-1
So, the recursive definition of the sequence {on} is:
a₁ = 0 (base case)
an = 1 + (-1)ⁿ⁻¹ + an-1 (recursive rule)
(b) Finding the values of f(2), f(3), f(4):
Given the recursive definition of the function f, we can use it to find the values of f(2), f(3), and f(4).
f(0) = -1 (given)
f(1) = 2 (given)
Using the recursive rule, we can calculate the values of f(2), f(3), and f(4):
f(2) = 1 + (-1)¹ + f(1) = 1 - 1 + 2 = 2
f(3) = 1 + (-1)² + f(2) = 1 + 1 + 2 = 4
f(4) = 1 + (-1)³ + f(3) = 1 - 1 + 4 = 4
Learn more about recursive definition here:-
https://brainly.com/question/28105916
#SPJ11
what is the probability that the first person who subscribes to the five second rule is the 5th person you talk to
Answers
The probability that the first person who subscribes to the five-second rule is the 5th person you talk to is q⁴ * p.
To calculate the probability that the first person who subscribes to the five-second rule is the 5th person you talk to, we need to consider the following terms: probability, independent events, and complementary events.
Step 1: Determine the probability of a single event.
Let's assume the probability of a person subscribing to the five-second rule is p, and the probability of a person not subscribing to the five-second rule is q. Since these are complementary events, p + q = 1.
Step 2: Consider the first four people not subscribing to the rule.
Since we want the 5th person to be the first one subscribing to the rule, the first four people must not subscribe to it. The probability of this happening is q * q * q * q, or q⁴.
Step 3: Calculate the probability of the 5th person subscribing to the rule.
Now, we need to multiply the probability of the first four people not subscribing (q^4) by the probability of the 5th person subscribing (p).
The probability that the first person who subscribes to the five-second rule is the 5th person you talk to is q⁴ * p.
To learn more about Probability
https://brainly.com/question/24870672
#SPJ11
u are the manager of a rental car company. a customer, trenton has asked u for an estimate of charges for a nine day rental of an suv. he expects to drive 670 miles. if the company charges $56.50 per day plus 19 1/2 cents per mile for this category of vehicle, what would be the total rental charge in $ for trenton’s trip
Answers
The total rental charge in dollars for Trenton's trip for 9 days covering 670 miles will be $639.15.
How is the total rental charge computed?To compute the total rental charge for the Trenton trip, we calculate the total charges by days and the total charges by miles and then add these together.
For example, the total charges by day are $508.50 ($56.50 x 9), while the total charges by miles are $130.65 (670 x $0.195).
Summing these two charges will give the total charge for the trip.
Data and Calculations:The number of days for the rental trip = 9 days
Total miles for the trip = 670 miles
Charge per day = $56.50
Charger per mile = $0.195 (19¹/₂ cents)
Total charge = $639.15 {($56.50 x 9) + (670 x $0.195)}
Thus, the total rental charge in dollars for Trenton's trip for 9 days covering 670 miles will be $639.15.
Learn more about computing the total costs at https://brainly.com/question/5168855
#SPJ1
Which is more, 6 quarts or 26 cups?
Answers
Answer:
26 cups
Step-by-step explanation:
24 cups is 6 quarts, 25 cups is 6.25 quarts, and 26 cups is 6.5 quarts.
Therefore, 26 cups = 6.5
6.5>6
26 cups is larger than 6 quarts.
A bicycle repair shop offers two service packages to its customers: a tune up or a complete overhaul, which includes the tune up plus some additional services. All bicycles go through wheel balancing before leaving the shop. The repair shop is open 60 hours per week and receives an average of 180 bicycles each week. The shop employs three "tune up" technicians, one "additional services" technician, and two wheel balancing" specialists. Past data indicates that 25% of customers opt for the "additional services" option. Wheel Tune Up Balancing T = 75 T= 20 minutes minutes Additional Services T = 72 minutes a) Create a demand matrix for this process b) What will be the daily capacity at each stage of the process? c) Find the implied utilizations for each stage of the process. d) What will be the weekly capacity of the process? e) Is the flow rate of this process capacity-constrained or demand-constrained?
Answers
A bicycle repair shop that offers two service packages: a tune-up and a complete overhaul.
The shop operates for 60 hours per week and receives an average of 180 bicycles each week. To analyze the capacity and utilization of the process, we need to consider the time taken at each stage and the demand for each service option. We'll break down the problem into multiple parts and provide a detailed explanation using mathematical terms.
a) Creating the Demand Matrix:
To create a demand matrix, we need to determine the number of bicycles going through each stage of the process. Let's denote the demand for tune-up as T and the demand for additional services as A.
Given that the average number of bicycles received per week is 180 and 25% of customers opt for additional services, we can calculate the demands as follows:
Demand for tune-up (T) = Total demand - Demand for additional services
T = 180 - (0.25 * 180)
T = 180 - 45
T = 135
Demand for additional services (A) = 0.25 * Total demand
A = 0.25 * 180
A = 45
Now, we can create a demand matrix based on the demand for each service option:
Demand Matrix:
Tune-up Additional Services Wheel Balancing
Tune-up [135 0 0]
Additional [0 45 0]
Services
Total [ 135 45 0 ]
The demand matrix shows the number of bicycles flowing through each stage of the process.
b) Daily Capacity at Each Stage:
To calculate the daily capacity at each stage, we need to consider the time taken for each service option. Given that the shop operates for 60 hours per week, we can calculate the daily capacity at each stage:
Tune-up technician time per bicycle (\(T_{tuneup}\)) = 75 minutes
Additional services technician time per bicycle (\(T_{additional}\)) = 72 minutes
Wheel balancing specialist time per bicycle (\(T_{balancing}\)) = 20 minutes
Daily Capacity (C) = (60 hours * 60 minutes) / (\(T_{tuneup}\) + \(T_{additional}\) + \(T_{balancing}\))
Substituting the given values:
C = (60 * 60) / (75 + 72 + 20)
C = 21600 / 167
C ≈ 129.34 bicycles per day
Therefore, the daily capacity at each stage of the process is as follows:
Tune-up: 129 bicycles per day
Additional Services: 129 bicycles per day
Wheel Balancing: 129 bicycles per day
c) Implied Utilizations:
To find the implied utilizations, we need to compare the demand and the capacity at each stage of the process. Utilization can be calculated as the demand divided by the capacity.
Implied Utilization (U) = Demand / Daily Capacity
For the Tune-up stage:
\(U_{tuneup}\) = 135 / 129 ≈ 1.05
For the Additional Services stage:
\(U_{additional}\) = 45 / 129 ≈ 0.35
For the Wheel Balancing stage:
\(U_{balancing}\) = 0 / 129 = 0
The implied utilizations show how efficiently each stage of the process is being utilized. Utilization values greater than 1 indicate that the stage is operating beyond its capacity.
d) Weekly Capacity of the Process:
To calculate the weekly capacity of the process, we multiply the daily capacity by the number of days the shop is open per week:
Weekly Capacity = Daily Capacity * Number of days shop is open per week
Given that the shop is open for 60 hours per week, the number of days the shop is open per week can be calculated as follows:
Number of days shop is open per week = 60 hours / 24 hours per day = 2.5 days
Therefore, the weekly capacity of the process is:
Weekly Capacity = Daily Capacity * Number of days shop is open per week
Weekly Capacity = 129 bicycles per day * 2.5 days
Weekly Capacity = 322.5 bicycles per week
e) Flow Rate and Constraint Analysis:
To determine if the flow rate of the process is capacity-constrained or demand-constrained, we compare the weekly capacity to the demand for each service option.
Demand for Tune-up (\(T_{demand}\)) = 135 bicycles per week
Demand for Additional Services (\(A_{demand}\)) = 45 bicycles per week
Comparing the demands with the weekly capacity:
\(T_{demand}\) < Weekly Capacity (135 < 322.5)
\(A_{demand}\) < Weekly Capacity (45 < 322.5)
Since both the demands for tune-up and additional services are less than the weekly capacity, the flow rate of the process is demand-constrained. This means the shop has the capacity to handle the current demand without operating beyond its limits.
To know more about Demand Matrix here
https://brainly.com/question/13012912
#SPJ4
In order to estimate the difference between the average mortgages in the southern and the northern states of the United States, the following information was gathered.South NorthSample Size 40 45Sample Mean (in $1,000) $170 $175Sample Standard Deviation (in $1,000) $5 $7a. Compute the degrees of freedom for the t distribution.b. Develop an interval estimate for the difference between the average of the mortgages in the South and North. Let Alpha = 0.03.
Answers
The answers are:
a. The degrees of freedom for the t distribution is 83.
b. The interval estimate for the difference between the average of the mortgages in the South and North is approximately -6.59 to -3.41 (in $1,000).
a. To compute the degrees of freedom for the t distribution, we use the formula:
Degrees of Freedom = (Sample Size South - 1) + (Sample Size North - 1)
Plugging in the given values:
Degrees of Freedom = (40 - 1) + (45 - 1) = 39 + 44 = 83
b. To develop an interval estimate for the difference between the average of the mortgages in the South and North, we can use the t-distribution and the formula for the confidence interval:
Confidence Interval = (Sample Mean South - Sample Mean North) ± (t-value * Standard Error)
The t-value depends on the degrees of freedom and the desired level of confidence. Given that Alpha = 0.03, we need to find the t-value corresponding to a confidence level of 1 - Alpha = 0.97.
Using a t-distribution table or software, we find the t-value to be approximately 1.995 for a degrees of freedom of 83 and a confidence level of 0.97.
The standard error can be calculated using the formula:
Standard Error = sqrt((Sample Variance South / Sample Size South) + (Sample Variance North / Sample Size North))
Plugging in the given values:
Standard Error = sqrt((5^2 / 40) + (7^2 / 45)) = sqrt(0.3125 + 0.3265) = sqrt(0.639)
Therefore, the standard error is approximately 0.799.
Plugging all the values into the confidence interval formula:
Confidence Interval = (170 - 175) ± (1.995 * 0.799) = -5 ± 1.59
Learn more about Sample Variance from the given link:
https://brainly.com/question/30112124
#SPJ11
The greatest common factor of 65 and z, some unknown positive integer, is 13. there are two possible values for z between 30 and 60. what is the difference between these two values? (a) 11 (b) 12 (c) 13 (d) 14 (e) 15
Answers
Z is 52 and the difference between the values 65 and 52 is 13.
Given,
Two numbers : 65 and Z
Greatest common factor of the above numbers = 13
Z is a positive integer.
Possible values of Z is between 30 and 60.
Now,
13 x 5 = 65
So other number must be a multiple of 13 and a number below 5.
That is, 13 x 4 = 52 and 13 x 3 = 39. These are the two numbers between 30 and 60.
Now consider the difference.
65 – 52 = 13
65 – 39 = 26
In the given options we have 13 and 26 is not given in the option.
So the value of Z is 52 and the difference between 65 and 52 is 13.
Learn more about common factor here: https://brainly.com/question/11221202
#SPJ4
O No; there are y-values that have more than one x-value.
• No; the graph fails the vertical line test.
• Yes; the graph passes the vertical line test.
Yes; there are no y-values that have more than one x-value.

Answers
The graph meets the vertical line test requirement, it must represent a function (C) The vertical line test shows that the graph is correct, hence the answer is yes.
How do functions work?According to the function, every value in the domain is associated to exactly one value in the range, and they have a predefined domain and range. It is characterized as a certain kind of relationship.
Please refer to the image instead of the graph, which is related to it.
The graphic displays a graph.
A parabola is seen on the graph.
The vertical line test determines if a graph can be a function, as is common knowledge.
The graph passes the vertical line test option, indicating that it does in fact represent a function (C) The vertical line test shows that the graph is correct, hence the answer is yes.
To know more about function, visit
brainly.com/question/5245372
#SPJ1
Solve 19+ 6w = 67
W =
Watch video
Answers
Answer:
w = 8
Step-by-step explanation:
Solve 19+ 6w = 67
W =?
19 + 6w = 67
6w = 67 - 19
6w = 48
w = 48 : 6
w = 8
----------------------------
check
19 + 6 x 8 = 67
19 + 48 = 67
67 = 67
the answer is good
a standard deck is shuffled and placed on a table. what is the expected number of cards that are next to another card of the same value? (in a standard deck there are 52 cards. there are 13 values (ace, two, three, . . . , nine, ten, jack, queen, king). each value appears on 4 different cards in the deck)
Answers
The expected number of cards that are next to another card of the same value in a shuffled standard deck is approximately 0.1698.
To calculate the expected number of cards that are next to another card of the same value in a shuffled standard deck, we can consider the probability of each card being next to another card of the same value.
Let's break down the calculation:
For each card in the deck, there are two adjacent cards (one on each side) that can potentially be of the same value. However, the first and last cards only have one adjacent card each.
For the inner cards (excluding the first and last cards), there are three possibilities for each card:
The card is of the same value as the card to its left and the card to its right.
The card is of the same value as the card to its left but not the card to its right.
The card is of the same value as the card to its right but not the card to its left.
Since each card value appears on four cards in the deck, the probabilities for each of these three possibilities are:
Probability of both adjacent cards having the same value = (3/51) × (3/51) = 9/2601
Probability of only the left adjacent card having the same value = (3/51) × (48/51) = 144/2601
Probability of only the right adjacent card having the same value = (48/51) × (3/51) = 144/2601
Now, let's calculate the expected number of cards next to another card of the same value:
Expected number = (1/52) + (1/52) + (50/52) × (9/2601 + 144/2601 + 144/2601) + (1/52) = 441/2601 ≈ 0.1698
Therefore, the expected number of cards that are next to another card of the same value in a shuffled standard deck is approximately 0.1698.
Learn more about Probability here:
https://brainly.com/question/30034780
#SPJ11
These two figures are the image and pre-image of a
dilation.
Find the lengths of the missing sides.
X= 2.5
y = 5
You’re welcome :(

Answers
The second shape is 15
Answer:
The answer is 2.5 and 5
Step-by-step explanation:
b) Without a calculator, evaluate (0.1)² = (0.1)4
Answers
Answer:
false
Step-by-step explanation:
The left side equals 0.01
The right side equals 0.4
The two sides are not equal. This is a false equation.
Answer:0.01=0.0001
Step-by-step explanation:
A study in Korea showed that a metric called the Empathy Quotient Scale (which measure empathy) is approximately normally distributed in that population with a mean of 35.4 and a standard deviation of 9.6. The figure shows a histogram of the data from that study.Mean=35.4393 Std. Dev.=9.63982 n=478 In a group of 100 individuals from this population, approximately how many will have scores between 25 and 45?
Answers
Approximately 76 individuals will have scores between 25 and 45.
How many will have scores between 25 and 45?In a group of 100 individuals from this population, approximately 76 individuals will have scores between 25 and 45.The given information is related to a study in Korea which showed that the Empathy Quotient Scale (which measure empathy) is approximately normally distributed in that population with a mean of 35.4 and a standard deviation of 9.6. We are given that n = 478.
According to the question, we need to find the number of individuals from this population who will have scores between 25 and 45 in a group of 100 individuals from this population.Now we need to standardize the Empathy Quotient Scale value of 25 and 45. We will use the formula for standardizing the value
z= (X - μ) / σ
Where z is the standard score, X is the raw score, μ is the population mean, and σ is the population standard deviation.
For X = 25:z= (X - μ) / σ= (25 - 35.4) / 9.6= -1.09For X = 45:z= (X - μ) / σ= (45 - 35.4) / 9.6
= 1
Therefore, we need to find the area under the normal distribution curve between -1.09 and 1.Using the standard normal distribution table, we find that the area to the left of -1.09 is 0.1379, and the area to the left of 1 is 0.8413.Therefore, the area between -1.09 and 1 is:0.8413 - 0.1379 = 0.7034
Approximately, 70.34% of the individuals in this population will have scores between 25 and 45 in a sample size of 1.From the given information, n = 478. Therefore, the standard error of the sample is given by:
σx = σ / √nσx = 9.6 / √478σx = 0.4393
Now, to estimate the number of individuals with Empathy Quotient Scale scores between 25 and 45 in a group of 100 individuals from the population, we use the formula for the standard error of the mean:
SE = σx / √nSE = 0.4393 / √100SE = 0.04393
We now know that the mean of the Empathy Quotient Scale is 35.4 and the standard error of the mean is 0.04393.To find the number of individuals with Empathy Quotient Scale scores between 25 and 45 in a group of 100 individuals from the population, we standardize the range (25 to 45) using the mean and the standard error:
z₁ = (25 - 35.4) / 0.04393 = -237.68z₂ = (45 - 35.4) / 0.04393 = 217.49
Now, we can use the standard normal distribution table to estimate the probability of the scores falling between -237.68 and 217.49, which is essentially the same as finding the percentage of individuals who have scores between 25 and 45.
To find the percentage of individuals with Empathy Quotient Scale scores between 25 and 45, we need to find the area under the standard normal distribution curve between -237.68 and 217.49.Using the standard normal distribution table, we find that the area to the left of -237.68 is approximately 0 and the area to the left of 217.49 is approximately 1.The area between -237.68 and 217.49 is:1 - 0 = 1
So, approximately 100% of the individuals in this population will have scores between 25 and 45 in a sample size of 100 individuals. The result is the same for the whole population. Therefore, the number of individuals with Empathy Quotient Scale scores between 25 and 45 in a group of 100 individuals from this population is approximately:
100 × 100% = 100 individualsTherefore, approximately 76 individuals will have scores between 25 and 45.
Learn more about Empathy.
brainly.com/question/14669414
#SPJ11
She must determine height of the clock tower using a 1.5 m transit instrument (calculations are done 1.5 m above level ground) from a distance 100 m from the tower she found the angle of elevation to be 19 degrees. How high is the clock tower from 1 decimal place?
Answers
Step-by-step explanation:
We can use trigonometry to solve this problem. Let's draw a diagram:
```
A - observer (1.5 m above ground)
B - base of the clock tower
C - top of the clock tower
D - intersection of AB and the horizontal ground
E - point on the ground directly below C
C
|
|
|
|
| x
|
|
|
-------------
|
|
|
|
|
|
|
|
|
B
|
|
|
|
|
|
|
|
|
|
|
A
```
We want to find the height of the clock tower, which is CE. We have the angle of elevation ACD, which is 19 degrees, and the distance AB, which is 100 m. We can use tangent to find CE:
tan(ACD) = CE / AB
tan(19) = CE / 100
CE = 100 * tan(19)
CE ≈ 34.5 m (rounded to 1 decimal place)
Therefore, the height of the clock tower is approximately 34.5 m.
what is the greatest common factor of 39, 42, and 33
Answers
Answer:
The greatest common factor of 39, 42, and 33 is 3
Step-by-step explanation:
Answer: The greatest common factor of 39,42, and 33 is 3
Step-by-step explanation:
We first find the factors of the numbers
39=1x39, 3x13 (1,3,13,39)
42=1x42, 2x21, 3x14, 6x7(1,2,3,6,7, 42)
33=1x33, 3x11(1,3,11.33)
The common factors are the factors that appear in the three numbers which are 1 and 3
The greatest common factor therefore is 3
You want to find how many students at your school support your student-council president. You get a list of every student in the school, separate them by grade, and then call twenty people at random from each grade to interview. Is the survey plan random, systematic, or stratified
Answers
20 students are selected at random from each grade level, of random sampling within each stratum.
A random sample from each grade level, the survey plan ensures that each grade level is represented in the sample, and that the sample is likely to be representative of the entire school population.
The survey plan described in the question is a combination of two different sampling techniques:
stratified sampling and random sampling.
Stratified sampling involves dividing the population into subgroups, or strata, based on certain characteristics that are relevant to the research question.
The population is divided by grade level, which is likely to be a relevant factor when it comes to determining student support for the student-council president.
The purpose of stratified sampling is to ensure that each subgroup is represented in the sample in proportion to its size in the population.
This helps to minimize sampling bias and increase the precision of the estimates obtained from the sample.
Once the population is divided into subgroups, random sampling is used to select a sample from each stratum.
Random sampling involves selecting individuals from the population in such a way that each individual has an equal chance of being selected.
This helps to ensure that the sample is representative of the population and that any estimates obtained from the sample are unbiased.
In this survey plan, 20 students are selected at random from each grade level, which is an example of random sampling within each stratum.
By selecting a random sample from each grade level, the survey plan ensures that each grade level is represented in the sample, and that the sample is likely to be representative of the entire school population.
Overall, the survey plan described in the question is a good example of how different sampling techniques can be combined to obtain a representative sample of a population.
By using stratified sampling to divide the population into subgroups and random sampling to select individuals from each subgroup, the survey plan helps to minimize sampling bias and increase the precision of the estimates obtained from the sample.
For similar questions on random
https://brainly.com/question/251701
#SPJ11
here is a scatter plot for a set of bivariate data. what would you estimate the correlation coefficient to be?
Answers
You can use scatter plots to present bivariate data. The data can be used to create coordinate pairs.
What is meant by scatter plot?The relationship between the two variables in a bivariate data set is graphically represented by a scatter plot. Consider them to be the graphic depiction of two data sets that have been combined by allocating each axis in the plot to a distinct variable.
Due to the presence of two variables, this type of data is known as bivariate data. Only 1 variable may be displayed on a line plot. You can use scatter plots to present bivariate data. The data can be used to create coordinate pairs.
The standard deviation of each variable and the covariance between them must first be determined in order to calculate the Pearson correlation. Covariance is subtracted from the product of the standard deviations of the two variables to get the correlation coefficient.
To learn more about scatter plot refer to:
https://brainly.com/question/6592115
#SPJ4
Fifteen more than half a number is 9.
Answers
Answer:
-12
Step-by-step explanation:
-12/2 = -6
-6+15 = 9
Answer:
15 + x/2 = 9 -> x=-12 (simplified)
Step-by-step explanation:
15 + x/2 = 9
15 more (add) x/2 (half a number) = (is) 9
A ___ is a sample in which every element in the population has a known statistical likelihood of being selected.
Answers
A "probability sample" is a sample in which every element in the population has a known statistical likelihood of being selected.
What is probability sampling?Probability sampling is a methodology in which the researcher selects samples from a broader population using a probability theory-based method. A participant must be chosen at random in order to be used as a probability sample.
Some key features regarding probability sampling are-
The most important criteria for probability sampling being that each person in the population has an equal and known chance of being chosen.As the name implies, simple random sampling is a completely random method for choosing the sample. The sampling method is just as simple as randomly assigning to persons (sample) and then selecting at random from those numbers using an automated mechanism. Finally, the numbers chosen represent the members from the sample.Within that method of sampling, researchers chose samples in two ways: the lottery method and using numbers generating software/random number table. This sampling strategy is typically used on a significant population and has both advantages and limitations.To know more about probability sampling, here
https://brainly.com/question/28016369
#SPJ4
Which expression is equivalent to ( - 3/4 ) ÷ ( - 8 )?
Answer choices
A. 3/4 X 1/8
B. - 4/3 X 8
C. 4/3 X 8
D. - 3/4 X 8
Answers
The radius of the water well is 2r inches. Find the area of the water well.
Answers
The area of the water well is \(4\pi r^2\)
How to determine the area?The radius is given as:
Radius, R = 2r
The area of the water well is calculated using:
\(A = \pi R^2\)
This gives
\(A = \pi (2r)^2\\\\\\\)
Evaluate the expression
\(A = 4\pi r^2\)
Hence, the area of the water well is \(4\pi r^2\)
Read more about area at:
https://brainly.com/question/24487155
#SPJ1