Choose the proportion that correctly represents the similar figures.
A. 5/x = 3/8
B. 8/5 = 3/x
C. 8/3 = x/5
D. x/3 = 8/5

Answers
The proportion that correctly represents the similar figures is the one in option B:
8/5 = 3/x
Which proportion correctly represents the similar figures?If two figures are similar, then the quotient between the correspondent sides must be equal.
Then we can write the equation:
8ft/3ft = 5ft/x
8/3 = 5/x
Now we can divide both sides by 5 and multiply both sides by 3, then we will get:
8/5 = 3/x
That is the proportion we wanted, then we conclude that the correct option is B.
Learn more about similar figures:
https://brainly.com/question/14285697
#SPJ1
Related Questions
help me please number 8
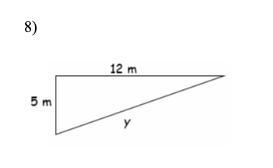
Answers
Answer:
13
Step-by-step explanation:
square root of 12^2 + 5^2
What’s 5x + 5 factored?
Answers
Answer:
5(x+1)
Step-by-step explanation:
So factor is to make it simplified like x(y+c) {I made up random variable for an example but almost all factored problems look like this}
So first find the Greatest Common Factor or GCF for short
The GCF between 5x and 5 is 5
So you divide the whole thing by 5
5x+5/5
you’d get x+1
Now for the 5 just put it around X+1 but with parenthesis
5(x+1)
the matrix of a relation r on the set { 1, 2, 3, 4 } is . answer y for yes or n for no. no other answers are programmed and any other answer will be marked wrong: (A). R is reflexive and symmetric but not transitive.
(B). R is reflexive and transitive but not symmetric.
(C). R is symmetric and transitive but not reflexive.
(D). R is an equivalence relation.
Answers
Since the relation is symmetric and transitive, but not reflexive, it does not satisfy all the properties of an equivalence relation, the correct answer is (C) R is symmetric and transitive but not reflexive.
For a relation to be reflexive, every element in the set must be related to itself. In this case, the matrix does not have 1s on the diagonal, indicating that it is not reflexive.
For a relation to be symmetric, if (a, b) is in the relation, then (b, a) must also be in the relation. Looking at the matrix, we can see that it is symmetric as the 1s appear in corresponding positions across the main diagonal.
For a relation to be transitive, if (a, b) and (b, c) are in the relation, then (a, c) must also be in the relation. The matrix satisfies this property as the only instances where both (a, b) and (b, c) are 1s, (a, c) is also a 1.
learn more about symmetric here:
https://brainly.com/question/31184447
#SPJ11
how do i find the scale factor?

Answers
Answer:
1:3.7
Step-by-step explanation:
1331/27
Then cube root
3.66666666667
Round
3.7
(i believe)
Use the graph of the polynomial function to find the factored form of the
related polynomial. Assume it has
no constant factor.

Answers
Answer:
C. X+1 x+8
Here is ur answer
Mark me as brainlest.......
the mass of a plastic triangle is 3g and rhe mass of a plastic square is 7 g Samson has a collection of plastic triangles and squares if there are 14 triangles and squares altogether and their combined mass is 58 g calculate how many triangles and how many squares Samson has.
Answers
Answer:
4 squares
10 triangles
Step-by-step explanation:
t=3g
s=7g
t+s=14 t=14-s
3t+7s=58
substitute
3(14-s)+7s=58
42-3s+7s=58
reduce
4s+42=58
4s=16
s=4
t=14-4=10
et (Xn)n≥1 be a sequence of independent Bernoulli random variables with success probability p. Denote by S₁ the number of failures until the first success, by S₂ the number of failures between the first and second sucess, and, in general, by Sk the number of failures between the (k-1)th and the kth success. (a) Compute the joint probability mass function of S₁,..., Sn. (b) Are the random variables S₁,..., Sn independent? Prove or disprove. (c) Compute the cdf of U = max {S₁,..., Sn}.
Answers
The value of CDF at U = max {S₁,..., Sn} is \((1 - (1-p)^u+1)^n\).
We are given that;
The number of failures is between = (k-1)th and the kth success.
Now,
(a) The random variables S₁, S₂, ..., Sn are geometrically distributed with parameter p. The joint probability mass function of S₁,..., Sn is given by:
\(P(S_1 = k_1, S_2= k_2, ..., Sn = kn) = (1-p)^(k_1 + k_2+ ... + kn) * p^n\)
(b) The random variables S₁,..., Sn are independent. This can be shown by considering the definition of independence. Two random variables X and Y are independent if and only if P(X = x, Y = y) = P(X = x)P(Y = y) for all x and y. In our case, we have:
\(P(S_1 = k_1, S_2 = k_2, ..., Sn = kn) = (1-p)^(k_1 + k_2 + ... + kn) * p^n= (1-p)^k_1 * p * (1-p)^k_2 * p * ... * (1-p)^kn * p= P(S_1 = k_1)P(S_2 = k_2)...P(Sn = kn)\)
Therefore, the random variables S₁,..., Sn are independent.
(c) The cdf of U = max {S₁,..., Sn} is given by:
P(U ≤ u) = P(S₁ ≤ u, S₂ ≤ u, ..., Sn ≤ u)= P(S₁ ≤ u)P(S₂ ≤ u)...P(Sn ≤ u)
= \((1 - (1-p)^u+1)^n\).
Therefore, by the sequence the answer will be \((1 - (1-p)^u+1)^n\).
Learn more about arithmetic sequence here:
https://brainly.com/question/3702506
#SPJ4
if it is accepted that an observed association is a causal one, an estimate of the impact that a successful preventive program might have can be derived from:
Answers
The estimate of the impact that a successful preventive program might have can be derived from
attributable risk.
What is an attributable risk?In epidemiology, attributable risk or excess risk is a phrase equivalent with risk difference, which has also been used to express the attributable proportion among the exposed and the population.
Attributed risk assists in determining how much of an outcome is attributable to a certain risk factor (i.e., an estimate of the excess risk) in a population exposed to that factor.
The rate (percentage) of a health result (illness or death) in exposed persons that can be linked to the exposure is known as the attributable risk (AR). Attribitable risk measures how much more common a result is in absolute terms among the exposed than the non-exposed.
Learn more about program on:
https://brainly.com/question/26134656
#SPJ1
The missing number in the arithmetic sequence 60, 51, ___, 33 is:
Answers
Answer:
42
Step-by-step explanation:
In this question, we have the find the rate of change in the sequence.
To find this, we need to find how much the sequence is changing by.
We know from 60 to 51 is -9, so we know that our sequence is changing by -9.
To find our unknown number, we would subtract 9 from 51.
51 - 9 = 42
Our missing number in the sequence is 42.
We can check our answer by subtracting 9 from 42. This gives us our next number, which is 33.
42 would be your answer.
I need to know the probability that someone would prefer pie using this vin diagram

Answers
The probability of the event B, which is the probability that a person prefers pie, is approximately 0.2345.
From the venn diagram, we can see that there are a total of 24 + 93 + 10 + 18 = 145 people.
The event B represents the people who prefer pie, which is 24 + 10 = 34 people, because these are the people who prefer pie or both pie and cake.
So the probability of the event B, P(B), is the proportion of people who prefer pie or both pie and cake out of the total number of people:
P(B) = (number of people who prefer pie or both pie and cake) / (total number of people)
P(B) = (24 + 10) / 145
P(B) = 34 / 145
P(B)= 0.2345
Therefore, the probability of the event B, which is the probability that a person prefers pie, is approximately 0.2345.
To learn more on probability click:
https://brainly.com/question/11234923
#SPJ1
This question is from my final exam review:
Let n be a randomly selected integer from 1 to 15. Find P(n < 10 | n is prime). Round to the nearest hundredth and put your answer as a DECIMAL. So, if your answer is 37%, then put .37 in the answer box.
Answers
The probability P(n < 10 | n is prime) is 4/6, which simplifies to 2/3 or approximately 0.67 (rounded to the nearest hundredth).
To find the probability P(n < 10 | n is prime), we need to determine the number of prime integers less than 10 and divide it by the total number of integers from 1 to 15 that are prime.
The prime numbers less than 10 are 2, 3, 5, and 7. So, there are 4 prime numbers less than 10.
The total number of integers from 1 to 15 that are prime is 6 (2, 3, 5, 7, 11, and 13).
As a result, the chance P(n 10 | n is prime) is 4/6, which can be expressed as 2/3 or, rounded to the nearest hundredth, as around 0.67.
Thus, 0.67 is the answer.
for such more question on probability
https://brainly.com/question/13604758
#SPJ8
Let f(x)=x√ and g(x)=x−13. Evaluate (f+g)(9).(1 point)
1. (f+g)(9)=3
2. (f+g)(9)=7
3.(f+g)(9)=−1
4. (f+g)(9)=−4
Answers
Answer:
\((f+g)(9) = -1\)
Step-by-step explanation:
First, undo the given shorthand:
\((f+g)(x) = f(x) + g(x)\)
Then, solve for \(f(x)\) and \(g(x)\) individually, and at the end, add the results together.
We can start with \(f(x)\):
\(f(x) = \sqrt{x}\)
\(f(9) = \sqrt9\)
\(f(9) = 3\)
Now, we'll move on to \(g(x)\):
\(g(x) = x - 13\)
\(g(9) = 9 - 13\)
\(g(9) = -4\)
Finally, we can add our solved results for \(f(9)\) and \(g(9)\):
\(f(9) + g(9) = 3 - 4 = -1\)
Hence,
\((f+g)(9) = -1\)
The next two questions involve predicting the height of a population of girls at age 18 based on each girls height at age 2. We have a sample of 70 girls from Berkley, CA born in 1928-1929 where we have measured their height at age 2 and 18. Let +=the height of girls at age 2 in cm's .y = the height of girls at age 18 in cm's. The the following are the appropriate summary statistics n = 70 = 87.25, y = 166.54, R = 0.664. S 3.33. 6.07 Dscat_girls.
Answers
The regression equation for predicting the height of girls at age 18 based on their height at age 2 is:
y ≈ 68.953 + 1.210x
What is linear regression?The correlation coefficient illustrates how closely two variables are related to one another. This coefficient's range is from -1 to +1. This coefficient demonstrates the degree to which the observed data for two variables are significantly associated.
Based on the given information, we can use the linear regression model to predict the height of girls at age 18 based on their height at age 2. Here are the summary statistics:
n = 70 (sample size)
x = 87.25 (mean height at age 2 in cm)
y = 166.54 (mean height at age 18 in cm)
R = 0.664 (correlation coefficient)
S = 3.33 (standard deviation of height at age 2 in cm)
\(S_y\) = 6.07 (standard deviation of height at age 18 in cm)
To predict the height of girls at age 18 (y) based on their height at age 2 (x), we can use the regression equation:
y = a + bx
where a is the y-intercept (predicted height at age 18 when x = 0) and b is the slope of the regression line.
From the given information, we have the following values:
x = 87.25
y = 166.54
R = 0.664
Using these values, we can calculate the slope (b) of the regression line:
b = R * (\(S_y\) / S)
= 0.664 * (6.07 / 3.33)
≈ 1.210
Next, we can calculate the y-intercept (a) using the formula:
a = y - b * x
= 166.54 - 1.210 * 87.25
≈ 68.953
Therefore, the regression equation for predicting the height of girls at age 18 based on their height at age 2 is:
y ≈ 68.953 + 1.210x
Learn more about linear regression on:
https://brainly.com/question/27426965
#SPJ4
How are comparisons between negative numbers different than comparisons between positive numbers?
Answers
A man sells 8 articles for Rs. 7360 and makes a profit of
15%. Find the gain or loss percent if he sells 13 such
articles for Rs. 11440.
(Ans: 10% gain)
Answers
Answer:
SP of 8 articles =Rs 7360
Profit=15%
Now,
SP of each article =7360/8= Rs920
Wkt,
SP=CP+profit (let CP=x)
920=x+15%of CP
920=x+15÷100× x
920=x+15x÷100
920=(100x+15x)÷100
920=115x÷100
92000=115x
92000÷115=x
Therefore, x=Rs 800
CP=800(i.e Cost price of one article)
Again,
SP of 13 articles=Rs 11440
SP of 1 article=11440÷13=Rs 880
Since,SP>CP
Profit!
Profit=SP-CP
=880-800
=Rs 80
Profit%=profit÷CP×100%
=80÷800×100
=10%
The chi-square distribution provides a good approximation to the sampling distribution of the chi-square statistic only if the sample size is large. The sample size is large enough if each expected count is Select one:
a. 5 or higher
b. 25 or higher
c. 10 or higher
d. 15 or higher
e. 20 or higher
Answers
The correct answer to the given question about chi-square distribution and sampling distribution is a. 5 or higher.
The chi-square distribution provides a good approximation to the sampling distribution of the chi-square statistic only if the sample size is large. Generally, a sample size of 5 or higher is considered large enough for this approximation. This is because the chi-square distribution approaches a normal distribution as the degrees of freedom increase, and a sample size of 5 or more provides enough degrees of freedom for the approximation to be valid. However, if any expected count is less than 5, then the approximation may not be reliable, and alternative methods should be considered (such as Fisher's exact test or the Monte Carlo method).
To learn more about chi-square distribution click here
brainly.com/question/30259945
#SPJ4
Aggregate Demand (AD)=C+I+G+ (X-M). X = O a. X factor b. exchange c. exports
Answers
Aggregate Demand (AD) is a macroeconomic concept that represents the total demand for goods and services in an economy. The X factor in the AD equation represents exports, which are an important part of the economy.
AD is calculated by adding up the individual components of demand, which include consumer spending (C), investment spending (I), government spending (G), and net exports (X-M). The X-M component represents the difference between exports (X) and imports (M).
The X component in the equation represents exports, which are the goods and services produced domestically and sold to foreign countries. Exports are an important part of the economy as they generate income and create jobs. The M component in the equation represents imports, which are the goods and services purchased from foreign countries and consumed domestically. Imports can have a negative impact on the economy as they represent a drain on resources and can lead to a trade deficit. The X factor in the equation is used to represent exports because it is a variable that can change over time. Factors that can affect exports include exchange rates, tariffs, and global demand for certain products. If the exchange rate between two currencies changes, it can make exports more or less expensive for foreign buyers, which can affect the level of exports. Tariffs are taxes on imports, which can make domestic products more competitive in foreign markets.
To know more about Aggregate Demand visit :-
https://brainly.com/question/29349235
#SPJ11
The following data gives the means of two samples taken from a population. Test whether there is any significant difference between the two samples at 95% level. x = 60, y = 59, n₁ = 100, n₂ = 200 and σ = 50.
Answers
Based on the given data, there is no significant difference between the means of the two samples at the 95% level.
To test whether there is a significant difference between the two samples, we can use the independent samples t-test. Here are the steps to perform the test:
Step 1: State the null hypothesis (H₀) and alternative hypothesis (H₁):
H₀: There is no significant difference between the means of the two samples.
H₁: There is a significant difference between the means of the two samples.
Step 2: Set the significance level (α):
In this case, the significance level is given as 95%, which corresponds to α = 0.05.
Step 3: Calculate the test statistic:
The test statistic for the independent samples t-test is given by:
t = (x₁ - x₂) / sqrt((s₁²/n₁) + (s₂²/n₂))
Where:
x₁ and x₂ are the sample means,
s₁ and s₂ are the sample standard deviations,
n₁ and n₂ are the sample sizes.
In this case, x₁ = 60, x₂ = 59, n₁ = 100, n₂ = 200, and σ = 50.
Step 4: Determine the critical value:
Since the significance level is 0.05 and the test is a two-tailed test, we divide the significance level by 2 to find the critical value. Using the t-distribution table or a statistical software, we find that the critical value for a two-tailed test with α = 0.05 is approximately 1.96.
Step 5: Compare the test statistic with the critical value:
If the absolute value of the test statistic is greater than the critical value, we reject the null hypothesis. Otherwise, we fail to reject the null hypothesis.
Let's calculate the test statistic:
t = (60 - 59) / sqrt((50²/100) + (50²/200))
Using a calculator or software, the test statistic is calculated as:
t ≈ 0.1407
Since the absolute value of the test statistic (0.1407) is less than the critical value (1.96), we fail to reject the null hypothesis.
Therefore, based on the given data, there is no significant difference between the means of the two samples at the 95% level.
Learn more about samples from
https://brainly.com/question/24466382
#SPJ11
Find a vector equation with parameter t for the line of intersection of the planes x y z=2 and x z=0.
Answers
The vector equation with parameter t for the line of intersection of the planes x + y + z = 2 and x + z = 0 is r(t) = <0, 2, 0> - t<1, -1, 0>.
To find a vector equation with parameter t for the line of intersection of the planes x + y + z = 2 and x + z = 0, we can solve the system of equations formed by the planes.
First, let's solve for y in terms of x and z from the equation x + y + z = 2. Rearranging the equation, we have y = 2 - x - z.
Now, substitute this expression for y in the equation x + z = 0. We have x + (2 - x - z) + z = 2, which simplifies to 2 - z = 2.
Solving for z, we find z = 0.
Substituting z = 0 into the equation x + z = 0, we have x = 0.
Now that we have the values of x, y, and z, we can form a vector equation for the line of intersection as follows:
r(t) = = <0, 2 - x - z, 0> = <0, 2, 0> - t<1, -1, 0>.
Learn more about vector equation
https://brainly.com/question/31044363
#SPJ11
Solve for X. Answer needed ASAP!!
45+1y/-15 = -3
Answers
Answer:
y=720
Step-by-step explanation:
Multiply both sides of the equation by −15.
−675+1y=45
Add 675 to both sides.
1y=45+675
1y=720
-- -----
1 1
y=720
if you randomly select a mechanical component, what is the probability that it weighs more than 11.5lbf
Answers
The probability that randomly selected mechanical component weighs: more than 11.5 lbf is 0.0099, less than 8.7 lbf is 0.3208, less than 5.0 lbf is 0.0228, between 6.2 lbf and 7.0 lbf is 0.1314, between 10.3 lbf and 14.0 lbf is 0.0436, between 6.8 lbf and 8.9 lbf is 0.3464.
We can use the standard normal distribution and z-scores to answer these questions:
P(X > 11.5) = P(Z > (11.5 - 8) / 1.5) = P(Z > 2.33) = 0.0099
Therefore, the probability that a randomly selected mechanical component weighs more than 11.5 lbf is 0.0099, or about 1%.
P(X < 8.7) = P(Z < (8.7 - 8) / 1.5) = P(Z < 0.47) = 0.3208
Therefore, the probability that a randomly selected mechanical component weighs less than 8.7 lbf is 0.3208, or about 32%.
P(X < 5.0) = P(Z < (5 - 8) / 1.5) = P(Z < -2) = 0.0228
Therefore, the probability that a randomly selected mechanical component weighs less than 5.0 lbf is 0.0228, or about 2%.
P(6.2 < X < 7.0) = P((6.2 - 8) / 1.5 < Z < (7 - 8) / 1.5) = P(-1.2 < Z < -0.67) = 0.1314
Therefore, the probability that a randomly selected mechanical component weighs between 6.2 lbf and 7.0 lbf is 0.1314, or about 13%.
P(10.3 < X < 14.0) = P((10.3 - 8) / 1.5 < Z < (14 - 8) / 1.5) = P(1.53 < Z < 2.67) = 0.0436
Therefore, the probability that a randomly selected mechanical component weighs between 10.3 lbf and 14.0 lbf is 0.0436, or about 4%.
P(6.8 < X < 8.9) = P((6.8 - 8) / 1.5 < Z < (8.9 - 8) / 1.5) = P(-0.47 < Z < 0.60) = 0.3464
Therefore, the probability that a randomly selected mechanical component weighs between 6.8 lbf and 8.9 lbf is 0.3464, or about 35%.
To know more about probability :
https://brainly.com/question/15016913
#SPJ4
____The given question is incomplete, the complete question is given below:
Suppose that the weight of a mechanical component is normally distributed with mean p = 8.0 Ibf and standard deviation = 1.5 lbf. Answer the following questions: 1. If you randomly select a mechanical component, what is the probability that it weighs more than 11.5 lbf? 2. If you randomly select a mechanical component, what is the probability that it weighs less than 8.7 lbf? 3. If you randomly select a mechanical component, what is the probability that it weighs less than 5.0 lbf? 5. If you randomly select a mechanical component, what is the probability that it weighs between 6.2 lbf and 7.0 lbf? 6. If you randomly select a mechanical component, what is the probability that it weighs between 10.3 lbf and 14.0 lbf? 7. If you randomly select a mechanical component, what is the probability that it weighs between 6.8 lbf and 8.9 lbf?
events that occur in the extremes of the normal curve have a very small probability of occurring. group of answer choices true false
Answers
The statement, "Events which occur in extremes of normal-curve have a very small-probability of occurrence" is True because the normal distribution is a bell-shaped curve that is symmetrical around mean.
The Events which occur in extremes of normal curve have a very small probability of occurring because normal-distribution is a bell-shaped curve that is symmetrical around mean, with most values falling close to mean and fewer values occurring further away from mean.
So, as one moves further from the mean, the probability of occurrence decreases exponentially.
So, events that occur in the tails (extremes) of the normal curve have a very small probability of occurring.
Therefore, the statement is True.
Learn more about Normal Curve here
https://brainly.com/question/1554034
#SPJ4
What is the completely factored form of f(x) = 683 – 1332 - 4x + 15?
Answers
Answer:-637
Step-by-step explanation:
Find the equation of a line that passes through the points (-1,-5) and (-3,-4). Leave your answer in the form y=mx+c
Answers
Answer:
y = -1/2x - 11/2
Step-by-step explanation:
y2 - y1 / x2 - x1
-4 - (-5) / -3 - (-1)
1/ -2
= -1/2
y = -1/2x + b
-5 = -1/2(-1) + b
-5 = 1/2 + b
-11/2 = b
A health habit is a health behavior that a. is especially important for at-risk individuals to adopt. b. is not always beneficial to an individual's metabolism and immune system. c. is often performed automatically, without awareness. d. is only performed under the supervision of health specialists.
Answers
The correct option among the given choices is c. is often performed automatically, without awareness
What is Health Habit?A healthy habit is a behavior or action that people consistently engage in, usually without giving it any conscious thought.
These routines get established with these habits, which are frequently carried out automatically and unknowingly. frequently brushing your teeth, washing your hands before eating, using the stairs instead of the elevator, and exercising frequently are a few examples of healthy habits.
Therefore, option C is the most accurate description of a healthy habit.
Read more about Healthy habits here
https://brainly.com/question/30823363
#SPJ4
Can someone help me find measure of b and explain how you did it ;) thank you

Answers
Answer:
b=122°
Step-by-step explanation:
180°-58°=122°
look at the picture

PLS HELP! What is 4 1/3 multiplied by 2 1/4
Answers
Answer:
your answer would be 9 3/4
hope this helps
here our your choices for the other guy
A 2 1/3
B 5 1/2
C 1 1/9
D 2 1/6
Mr.Chang has a class of 18 students. He can spend $21 on each student to buy math supplies for the year. He first buys all of his students calculators, which cost a total of 170.64. After buying the calculators, how much does he have left to spend on each student
Answers
Answer:
572557486637778886367828766664728274747447378328288273
Answer: $11.52 left for each student
Step-by-step explanation:
First, divide the total amount of money spent by the total amount of students. 170.64/18. You will get $9.48. So, that means that so far Mr. Chang has spent $9.48 on each student. Then, just subtract $9.48 from $21 (which is the total amount he is willing to spend on each student. You should get $11.52. So, Mr. Chang has $11.52 left to spend on each student. Hope this helps!
<
Find the equation of the line.
Use exact numbers.

Answers
Answer:
y = 1/2 - 3
Step-by-step explanation:
The equation is y = mx + b
m = the slope
b = y-intercept
Slope = rise/run or (y2 - y1) / (x2 - x1)
Pick 2 points (0, -3) (6, 0)
We see the y increase by 3 and the x increase by 6, so the slope is
m = 3/6 = 1/2
Y-intercept is located at (0, -3)
So, the equation is y = 1/2 - 3
Find the total surface area of the prism.

Answers
Answer:
302in cubed
Step-by-step explanation:
equation 2(5x11+6x11+5x6)
Answer:
do 11x6 four times and do 6x5 two times
Step-by-step explanation: