A researcher was interested in studying americans email habits. She suspected that americans spend less than 7 hours a week answering their email. The general social survey in 2004 included a question that asked about the number of hours that the respondent spend on email per week. They asked 617 respondents. The sample mean number of hours was 6. 01 and the sample standard deviation was 8. 96. Find the test statistic.
Answers
The test statistic for this hypothesis test is approximately -2.748. Americans spend less than 7 hours a week answering their email.
To find the test statistic, we need to perform a hypothesis test to determine if the sample data supports the researcher's suspicion that Americans spend less than 7 hours a week answering their email.
Let's set up the null and alternative hypotheses:
Null hypothesis (H₀): The population mean number of hours Americans spend answering their email per week is 7 or more
Alternative hypothesis (H₁): The population mean number of hours Americans spend answering their email per week is less than 7
Next, we can calculate the test statistic, which is the standardized value that measures the distance between the sample mean and the hypothesized population mean, considering the sample size and variability.
The test statistic formula for a one-sample t-test is given by:
t = (sample mean - hypothesized mean) / (sample standard deviation / √sample size)
Given the information from the study:
Sample mean = 6.01
Sample standard deviation (s) = 8.96
Sample size (n) = 617
Hypothesized mean = 7
Substituting these values into the formula, we get:
t = (6.01 - 7) / (8.96 / √617)
Calculating this expression gives us the test statistic.
t = (-0.99) / (8.96 / √617)
t ≈ -0.99 / (8.96 / 24.81)
t ≈ -0.99 / 0.3602
t ≈ -2.748
Therefore, the test statistic for this hypothesis test is approximately -2.748.
The test statistic provides a measure of how far the sample mean is from the hypothesized mean in terms of standard deviations. In this case, since the test statistic is negative, it suggests that the sample mean is less than the hypothesized mean, supporting the researcher's suspicion that Americans spend less than 7 hours a week answering their email.
Learn more about statistic here
https://brainly.com/question/15525560
#SPJ11
Related Questions
Accounting Data Analytics
A) K-Means uses Euclidean distance. How is Euclidean distance between 2 points calculated?
B) What do "Ave Distance", "Max Distance", and "Separation" mean in the output from the cluster analysis (given in the Summary Report of the K-Means Cluster analysis).
C) What is convergence? What does it mean, when the video says there is convergence after 4 iterations? How is the option "Number of starting seeds" related to iterations and convergence?
Answers
K-Means uses Euclidean distance. The output includes average and maximum distances, separation, and convergence after iterations related to the number of starting seeds.
In the output of a K-Means cluster analysis, "Ave Distance" refers to the average distance between the data points and their assigned cluster centroids.
"Max Distance" represents the maximum distance between any data point and its assigned centroid. "Separation" indicates the distance between the centroids of different clusters, reflecting how well-separated the clusters are.
Convergence in K-Means clustering refers to the point when the algorithm reaches stability and the cluster assignments no longer change significantly.
When the video mentions convergence after 4 iterations, it means that after four rounds of updating cluster assignments and re-computing centroids, the algorithm has achieved a stable result.
The "Number of starting seeds" option determines how many initial random seeds are used for the algorithm, and it can affect the number of iterations needed for convergence. Increasing the number of starting seeds may result in faster convergence as it explores different initial configurations.
Learn more about Euclidean here:
https://brainly.com/question/31120908
#SPJ11
Steve travels from NYC to Boston at 90 mph
and returns to NYC at 60 mph taking 6 hours
total for the round-trip without stopping. What is
the distance between NYC and Boston?
(A) 192 mi.
(B) 208 mi.
(C) 216 mi.
(D) 224 mi.
(E) 272 mi.
Answers
Answer:
C
Step-by-step explanation:
d / rate = time
d / 90 + d/60 = 6 hours
(2d+ 3d)/180 = 6
5d = 1080
d = 216 miles
The distance from NYC to Boston is 216 miles.
We have a guy named Steve travels from NYC to Boston at 90 mph and returns to NYC at 60 mph taking 6 hours total for the round-trip without stopping.
We have to determine distance between NYC and Boston.
What is the formula to calculate the distance travelled by the body moving with speed ' v mph ' for ' t hours '.The distance covered by the body will be -
d = v x t
According to question, we have -
Assume that the distance travelled by Steve from NYC to Boston be x.
Then, total distance covered for the round trip = 2x.
From NYC to Boston -
Suppose that in going from NYC to Boston, Steve takes t hours. Then
x = 90 x t (1)
From Boston to NYC -
Steve will take (6 - t) hours to travel the distance. Then -
x = 60 x (6 - t) (2)
Now, Equating the equations (1) and (2), we get -
90 x t = 60 x (6 - t)
1.5t = 6 - t
1.5t + t = 6
2.5 t = 6
t = \(\frac{12}{5}\) = 2.4 hours
Therefore -
x = 90 x 2.4 = 216 miles
Hence, the distance from NYC to Boston is 216 miles.
To solve more questions on Speed, time and Distance visit the link below -
https://brainly.com/question/24999473
#SPJ2
The p-value for a coefficient shows if it is statistically significant True False
Answers
The given statement " the p-value for a Coefficient helps determine if it is statistically significant" is true. In statistical analysis, p-values are used to test the null hypothesis, which typically states that there is no significant relationship between the variables being analyzed.
A low p-value (usually below a predetermined significance level, such as 0.05) suggests that the null hypothesis can be rejected, indicating that there is a statistically significant relationship between the variables.
In the context of regression analysis, the p-value for a coefficient represents the probability of observing the obtained coefficient, or a more extreme one, under the assumption that the null hypothesis is true. If the p-value for a coefficient is low, it suggests that the corresponding independent variable is significantly related to the dependent variable. This means that the variable has an impact on the outcome and is not due to random chance.
To summarize, the p-value for a coefficient helps determine if it is statistically significant. A low p-value indicates that the null hypothesis can be rejected, suggesting a significant relationship between the variables. In regression analysis, a low p-value for a coefficient implies that the corresponding independent variable has a significant impact on the dependent variable.
To Learn More About Coefficient
https://brainly.com/question/1038771
#SPJ11
Solve for c, if ∠EHG=201
∘
Please help and explain !

Answers
The value of c in the angles (-2c+86)° and (-4c+103)° is 5
What is sum of angle at a point?The sum of angle at a point is 360°. Angles around a point describes the sum of angles that can be arranged together so that they form a full turn. Angles around a point add to 360 °.
In the diagram the three angles are at a point. This means their sum is 360°. angle EHG = 201. therefore;
201+ (-4c+103)° + (-2c+86)° = 360°
= 201-4c+103-2c+86 = 360
= 390-6c = 360
- 6c = 369-390
-6c = -30
divide both sides by -6
c = 30/6 = 5
therefore the value of c = 5
learn more about angle at a point from
https://brainly.com/question/25716982
#SPJ1
(03.01 MC)
Evaluate
ultiple Choice Worth 6 points)
x³-5x²+2x-6
x-1
10
X-1
Ox²-6x-2--
Ox²-4x-2-1
8
8
X-1
Ox³-6x-2--
10
X-1
Ox²-4x+6--

Answers
The evaluation of the fraction, \(\dfrac{x^3-5\cdot x^2+ 2\cdot x-6}{x - 1}\), using the long division method is the option;
\(x^2 - 4\cdot x -2-\dfrac{8}{x-1}\)What is the long division method?The expression can be presented as follows;
\(\dfrac{x^3-5\cdot x^2+ 2\cdot x-6}{x - 1}\)
The numerator x³ - 5·x² + 2·x - 6 does not have (x - 1) as a factor
However, dividing x³ - 5·x² + 2·x - 6 by (x - 1), gives;
x² - 4·x -2
(x - 1)|x³ - 5·x² + 2·x - 6
\({}\) x³ - x²
\({}\) -4·x² + 2·x - 6
\({}\) -4·x² + 4·x
\({}\) -2·x - 6
\({}\) -2·x + 2
\({}\) -8
The quotient from the division is x² -4·x -2, the remainder is -8, therefore, the result from the division x³ - 5·x² + 2·x - 6 by (x - 1) is the option;
\(x^2 -4\cdot x -2 -\dfrac{8}{x-1}\)Learn more about the long division method for dividing polynomials here:
https://brainly.com/question/25777560
#SPJ1
: Daily high temperatures in St. Louis for the last week were as follows: 92, 92, 93, 94, 95, 90, 93 (yesterday). a) The high temperature for today using a 3-day moving average = degrees (round your response to one decimal place). b) The high temperature for today using a 2-day moving average = degrees (round your response to one decimal place). c) The mean absolute deviation based on a 2-day moving average = degrees (round your response to one decimal place). d) The mean squared error for the 2-day moving average = degrees^2 (round your response to one decimal place). e) The mean absolute percent error (MAPE) for the 2-day moving average = % (round your response to one decimal place).
Answers
a) The high temperature for today using a 3-day moving average = 92.7 degrees.
b) The high temperature for today using a 2-day moving average = 91.5 degrees.
c) The mean absolute deviation based on a 2-day moving average = 1.5 degrees.
d) The mean squared error for the 2-day moving average = 2.25 degrees².
e) The mean absolute percent error (MAPE) for the 2-day moving average = 2.9%.
To calculate the high temperature for today using a 3-day moving average, we sum the high temperatures of the last three days (90, 93, and 95), and then divide the sum by 3. This gives us an average of 92.7 degrees, rounded to one decimal place.
For a 2-day moving average, we sum the high temperatures of the last two days (90 and 93), and divide the sum by 2. This gives us an average of 91.5 degrees, rounded to one decimal place.
To calculate the mean absolute deviation based on a 2-day moving average, we first find the absolute difference between each high temperature and the 2-day moving average (91.5 degrees). The differences are 1.5, 1.5, 1.5, 2.5, 3.5, and 1.5. Then, we calculate the average of these differences, which is 1.5 degrees, rounded to one decimal place.
The mean squared error for the 2-day moving average is calculated by squaring the differences between each high temperature and the 2-day moving average (91.5 degrees), and then finding the average of these squared differences. In this case, the squared differences are 2.25, 2.25, 2.25, 6.25, 12.25, and 2.25. The average of these squared differences is 4.83 degrees^2, rounded to one decimal place.
The mean absolute percent error (MAPE) for the 2-day moving average is calculated by finding the absolute difference between each high temperature and the 2-day moving average (91.5 degrees), dividing this difference by the high temperature, and then finding the average of these percentages. The percentages are 1.6%, 1.6%, 1.6%, 2.6%, 3.7%, and 1.6%. The average of these percentages is 2.9%, rounded to one decimal place.
Learn more about Temperature
brainly.com/question/7510619
#SPJ11
easy please helppp match the following defintion with the correct term: the vertical distance between two points on a line
1. run
2. rate of run
3. slope
4. rise
Answers
Answer:
4. rise
match the following definition with the correct term:
the vertical distance between two points on a line
1. run
2. rate of run
3. slope
4. rise
Levi went to GamePlay to trade in his old games. GamePlay will pay him $4.99 per game he trades in. If Levi trades in 5 games and wants to purchase a new game for $59.99, how much will he have to pay? Write your answer as a decimal to two places.
Answers
Answer:
He will have to pay $35.04
Step-by-step explanation:
4.99 x 5 = 24.95
59.99 - 24.95 = 35.04
Honestly I do not like bullies. If you are a bully than STOP.
Answers
Answer:
lol i don't like bullies either
i mean...i say that now...but in first grade i used to be a bully....we don't talk about that tho
anyways have a nice day and show them bullies who's boss
Exactly no one likes bullies :)
Beth enlarged the triangle below by a scale of 5.
A triangle with a base of 4 centimeters and height of 3.5 centimeters.
She found the area of the enlarged triangle. Her work is shown below.
One-half (4) (3.5) (5) = 35 centimeters squared
What was Beth’s error?
Answers
Answer: She should have multiply each of the sides the scale value before multiplying to find the area.
Step-by-step explanation:
They are two sides to the triangle which is the base and the height and each side have a different length so you will have to first multiply each side length by the scale value to find the new length of the enlarged triangle.
base: 4 *5 = 20
height : 3.5 * 5 = 17.5
Now since the base is 20 cm and the height is 17.5 cm you will use the area of a triangle formula to solve for the area.
A = 1/2* b * h
A = 1/2 * 20 * 17.5
A = 10* 17.5
A = 175
or she could have multiply 35 which is the number he obtained by another 5 to find the area.
Answer:
c i think not sure sorry
Step-by-step explanation:
Andres is going to invest in an account paying an interest rate of 4% compounded
continuously. How much would Andres need to invest, to the nearest dollar, for the
value of the account to reach $4,700 in 11 years?
Answers
\(~~~~~~ \textit{Continuously Compounding Interest Earned Amount} \\\\ A=Pe^{rt}\qquad \begin{cases} A=\textit{accumulated amount}\dotfill & \$ 4700\\ P=\textit{original amount deposited}\\ r=rate\to 4\%\to \frac{4}{100}\dotfill &0.04\\ t=years\dotfill &11 \end{cases} \\\\\\ 4700=Pe^{0.04\cdot 11} \implies 4700=Pe^{0.44}\implies \cfrac{4700}{e^{0.44}}=P\implies 3027\approx P\)
What is the measure of
PLEASE HELP HURRY
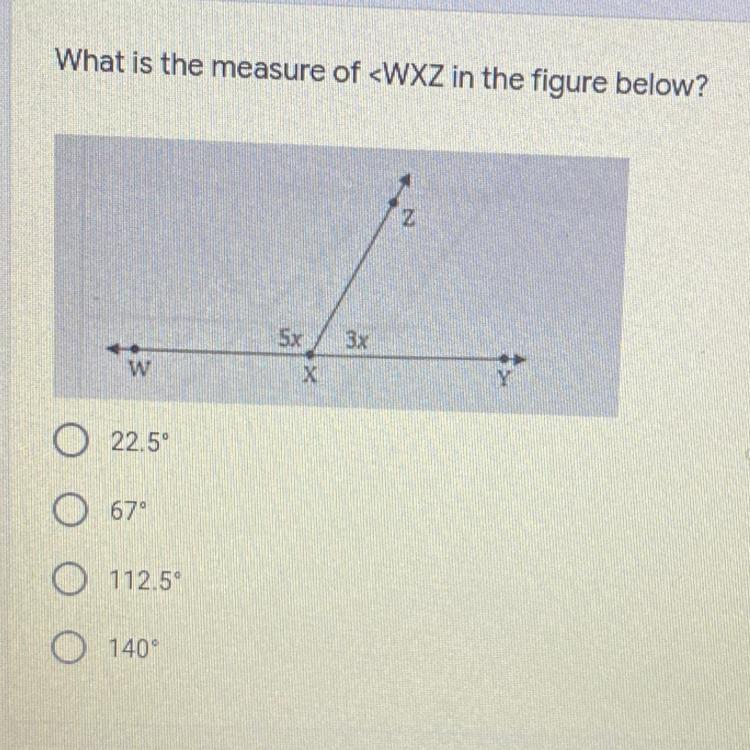
Answers
Answer:
112.5°
in pretty sure that's the answer
Use Basu's theorem to prove independence of the following pairs of statistics: (a) X and Σ(Xi – X)^2 where the X's are iid as N(ξ,σ^2). (b) X(1) and Σ[Xi – X(1)] in Problem 6.186.18 Show that the statistics X(i) and Σ[Xi – X(1)] of Problem 6.17(e) are independently distributed as E(a, b/n) and b Gamma (n – 2, 1) respectively. [Hint: If a = 0 and b = 1, the variables Yi = (n – i + 1)[X(i) – X(i-1)], i = 2, ..., n, are iid as E(0, 1).] (c) P = {E(a,b), - [infinity] < a < [infinity], 0 < b}; T = (X(1), Σ[Xi - X(1)]).
Answers
By using the Basu's theorem and from parts (a) and (b), we conclude that P and T are independent.
Basu's theorem states that if a complete sufficient statistic T and an ancillary statistic S are independent, then any statistic U that is a function of T and S is independent of any unbiased estimator of a function of θ.
Using Basu's theorem, we need to show that Σ(Xi – X)^2 is ancillary and independent of the mean ξ and variance σ^2. Since X follows a normal distribution, we know that the sum of squares of deviations from the mean (Σ(Xi – X)^2) follows a chi-square distribution with n degrees of freedom, where n is the sample size.
Since the chi-square distribution only depends on the sample size and is independent of the mean and variance of X, we conclude that Σ(Xi – X)^2 is ancillary and independent of ξ and σ^2. Therefore, using Basu's theorem, we conclude that X and Σ(Xi – X)^2 are independent.
In problem 6.18, we have shown that X(1) follows an exponential distribution with parameter λ = 1/θ, where θ is the common distribution of the X's. Therefore, X(1) is complete and unbiased for θ. Using the result from problem 6.17(e), we know that Σ[Xi – X(1)] follows a gamma distribution with parameters n – 1 and 1/θ. Therefore, Σ[Xi – X(1)] is ancillary and independent of θ. Using Basu's theorem, we conclude that X(1) and Σ[Xi – X(1)] are independent.
Using the hint provided in the problem, we can rewrite Σ[Xi – X(1)] as b times the sum of n – 1 independent exponential random variables with mean a/(n – 1). Therefore, Σ[Xi – X(1)] follows a gamma distribution with parameters n – 1 and a/(n – 1), which is equivalent to a gamma distribution with parameters n – 2 and b = 1/(a/(n – 1)).
To know more about Basu's theorem:
https://brainly.com/question/30889046
#SPJ4
Ari lives 4/5 of a mile from the park she has already walked 3/4 of the way to the park. How far has ari walked
Answers
Four plus twice a number
Answers
Answer: 2x + 4
Step-by-step explanation:
Answer:
4 + 2x
Step-by-step explanation:
Let x be the number:
Four plug = 4 +Twice a number: 2xPut them together: 4 + 2xI hope this helps!
Factorise 10x sq. - 14x cube + 18x to the power of 4
Answers
the expression \(10x^2 - 14x^3 + 18x^4 as 18x^2(x - 5/18)(x - 2/3).\)\(10x^2 - 14x^3 + 18x^4\) To factorise the expression we can first factor out the common factor of \(2x^\\2\):
\(2x^2(5 - 7x + 9x^2)\)
Now, we need to factorise the quadratic expression in parentheses, \(5 - 7x + 9x^2.\) We can use the quadratic formula to find the roots of this expression:
\(x = (-(-7) ± sqrt((-7)^2 - 4(5)(9)))/(2(9))\)
\(x = (7 ± sqrt(169))/18\)
\(x = (7 ± 13)/18\)
Therefore, the roots are x = 5/18 and x = 2/3.
We can use these roots to factorise the quadratic expression as follows:
5 - 7x + 9x{power}2 = 9(x - 5/18)(x - 2/3)
Substituting this into our original expression, we get:
\(10x^2 - 14x^3 + 18x^4 = 2x^2(5 - 7x + 9x^2)\)
=\(2x^2(9)(x - 5/18)(x - 2/3)\)
= \(18x^2(x - 5/18)(x - 2/3)\)
Therefore, we have successfully factorised the expression\(10x^2 - 14x^3 + 18x^4 as 18x^2(x - 5/18)(x - 2/3).\)
Factorising expressions is an important skill in algebra and can be useful in solving equations and simplifying complex expressions. In this case, we used the method of factoring by grouping and the quadratic formula to factorise the expression into a product of simpler expressions.
To know more about quadratic formula click here:
brainly.com/question/9300679
#SPJ4
find the missing angle measurement in the set of supplementary angles

Answers
Answer:
70 degrees
Step-by-step explanation:
180-110= 70
Answer:
70 degrees
Step-by-step explanation:
total of any supplementary angle is always 180 degrees 180 minus 110 then it is 70 degrees.
an amusement park charges a $ entrance fee. it then charges an additional $ per ride. which of the following equations could bum so use to properly calculate the dollar cost, , of entering the park and enjoying rides?
Answers
The equation you would use to properly calculate the dollar cost of entering the park and enjoying rides is Total Cost = Entrance Fee + (Number of Rides x Ride Fee).
In this case, Total Cost is the cost of entering the park and enjoying rides, Entrance Fee is the fee for entering the park, Number of Rides is the number of rides you will be taking, and Ride Fee is the fee charged for each ride.
Thus, plugging in the given values, the equation becomes Total Cost = Entrance Fee + (Number of Rides x Ride Fee).
Therefore, if the Entrance Fee is $ and each ride costs an additional $ , the Total Cost of entering the park and enjoying rides is $ .
for such more questions on calculations
https://brainly.com/question/17145398
#SPJ11
5a.) What does x = ? *

Answers
Answer:
x= 2/5
Step-by-step explanation:
multiplying by a reciprocal gives you 1
What is the value of x?

Answers
Answer:
x = 19.
Step-by-step explanation:
By the tangent - secant theorem:
BD^2 = AB * EB
so:
8^2 = (x - 7 + 4) * 4
4(x - 3) = 64
4x - 12 = 64
4x = 64 + 12 = 76
x = 76/4
= 19.
what is the probability of getting all tails? express your answer as a simplified fraction or a decimal rounded to four decimal places.
Answers
The probability of getting all tails when flipping a coin three times can be calculated using the multiplication rule of probability. For each flip of the coin, there are two possible outcomes: heads or tails.
Assuming the coin is fair, both outcomes are equally likely, so the probability of getting tails on any one flip is 1/2.
To calculate the probability of getting all tails in three flips, we need to multiply the probabilities of getting tails on each individual flip. Since the flips are independent events (i.e. the outcome of one flip does not affect the outcome of another flip), we can simply multiply the probabilities together:P(all tails) = P(tails on first flip) x P(tails on second flip) x P(tails on third flip)
= (1/2) x (1/2) x (1/2)
= 1/8
Therefore, the probability of getting all tails when flipping a coin three times is 1/8 or 0.125 when expressed as a decimal rounded to four decimal places.
To learn more about “probability” refer to the https://brainly.com/question/13604758
#SPJ11
Help Pleaseeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee

Answers
Answer: thats a tuff one
Step-by-step explanation:
im not sure
The answer is D 8g to the power of 6 h to the power of 4 k to the power of 12-h to the power of 25 k to the power of 15
S. Gregson noted the resting heart rates of her students after gym class. 85, 68, 76, 73, 81, 80, 65, 67, 82, 79, 67, 78, 68, 83, 71, 82, 70, 80, 75, 69
Which box plot models the resting heart rates of Ms. Gregson’s students?
Answers
Based on the given data, the box plot that best models the resting heart rates of Ms. Gregson’s students would have a box that extends from approximately 67 to 82, with a median line at around 77.
The whiskers would extend from the edges of the box to the minimum and maximum values of the data set, which are 65 and 85, respectively.
The box plot is a useful tool for visualizing numerical data, particularly in comparing distributions between different groups or conditions. The box represents the interquartile range (IQR), which is the middle 50% of the data, with the median line indicating the center of the data.
The whiskers extend to the smallest and largest data points within a certain range (usually 1.5 times the IQR), with any outliers shown as individual points. Box plots are especially useful for identifying skewness, outliers, and differences between groups in a data set.
To learn more about median click here :
brainly.com/question/28851245
#SPJ11
x is a negative integer which is the largest
7x+4
x-4
5x
-5x
Answers
Answer:
-5x
Step-by-step explanation:
Remember, if you multiply a negative number by a negative number, you will get a positive number, and positive numbers are greater than negative numbers. In this case, if I were to multiply each of these expressions with -1, I would get the following:
7(-1)+4=-3
-1-4=-5
5(-1)=-5
-5(-1)=5
And I'm sure you can imply how these values will correspond to other negative values. Basically, the last expression gives us a positive answer, which is larger than the others (which give a negative answer).
-5x will be the largest among the options since x is the negative integer.
What is a negative integer?On the number line, a negative integer is an integer that is to the left of zero. It is not equal to zero.
Given, x is a negative integer, all given options will become negative except " -5x". written with a minus sign. a number smaller than zero, but not a fraction or a decimal fraction.
Since for any value of x, all the given options will be negative.
Therefore, Due to the fact that x is a negative integer, -5x will be the largest selection.
Learn more about negative integers here:
https://brainly.com/question/6909050
#SPJ2
PLEASE HELP ME pleasee!

Answers
Answer:
b 2
Step-by-step explanation:
x is an integer that is greater than 3 and less than or equal to 6.
x can be 4, 5, 6.
Answer: b 2
Based on the data shown below X 2 3 4 5 6 7 8 19 10 data 45.22 44.74 40.96 37.68 33.7 30.62 30.94 24.26 21.88 21.4 11 Find the correlation coefficient. What proportion of the variation in y can be explained by the variation in the values of x? Report answer as a percentage accurate to one decimal place.
Answers
There is a strong negative linear relationship between x and y, and almost all of the variation in y can be explained by the variation in x.
The correlation coefficient is -0.961 and the proportion of the variation in y that can be explained by the variation in the values of x is 92.3%.
The correlation coefficient measures the strength and direction of the linear relationship between two variables. In this case, the correlation coefficient between x and y is -0.961, which indicates a strong negative linear relationship between the two variables.
The coefficient of determination (r²) measures the proportion of the variation in y that can be explained by the variation in the values of x. In this case, the value of r² is 0.923, or 92.3%. This means that 92.3% of the variability in y can be explained by the variability in x. Therefore, there is a strong negative linear relationship between x and y, and almost all of the variation in y can be explained by the variation in x.
Know more about correlation coefficient here:
https://brainly.com/question/29704223
#SPJ11
plz help me.
how to solve | k-10 | = 3
will give brainliest!!!
Answers
K = 13
To check my work you can plug 13 in for k:
13-10=3
Hope this helps (:
Answer:
\(k=7; k=13\)
Fast and loose:
If you stare at it for a while, you can see that the LHS is the distance between k and 10. Basically, you've asked to pick k so you get two numbers that are 3 apart from 10. And these two numbers are 7 to the left, and 13 to the right.
Rigorously
Split it in 2 situations, depending if the quantity inside the absolute value is greater or smaller than zero.
If it's greater or equal than zero:
\(\left \{ {{k-10\geq 0 } \atop {k-10 = 3} \right. \\\left \{ {{k\geq 10 } \atop {k = 13} \right.\)
And since 13 is indeed greater than 10, it's a valid solution, so you get the first one. For the second, you assume negative values for the quantity inside, and change sign:
\(\left \{ {{k-10 < 0 } \atop {k-10 = -3} \right. \\\left \{ {{k < 10 } \atop {k= 7} \right.\)
In this case, 7 is a valid solution too since it's less than 10
Question 2 Which is NOT the method that can be used to show congruency of two triangles? a) SSS b) ASA c) SAS d) SSA 0) None of the above Review Question3 ASATABFE by the HL method mZ AST 48 and m FEB 3x Find x.
Answers
Answer:
NO.2- SSA is not the method to show the congruency of two triangles.
Julia decides to make 5 batches of salad dressing. How much sugar should she use?
A)4/5 cup
B)1 1/5
C)5 1/4
D)1 1/4

Answers
She needs 1/4 to make 1 batch so multiply that by 5 (or add 1/4, 5 times) 5 * 1/4 = 5/4 = 1 1/4
Suppose that 5 years of service, 30% of computers have problems with motherboards (MB), 40% have problems with hard drives (HD) and 15% have problems with both MB and HD. What is the probability that a 5-year old computer still has fully functioning MB and HD
Answers
Answer:
0.45
Explanation:
Probability of bad motherboard(MB) = 0.30
Probability of bad hard-drive(H) = 0.40
Probability of bad motherboard and hard-drive (MB and H) = 0.15
P(MB U H)= P(MB) + P(H) -P(MB and H)
=0.30+0.40-0.15=0.55
Probability that a 5 year old computer would have no problems of motherboard and hard-drive =
1-P(MB U H) = 1-0.55= 0.45